


ในยุคแห่งข้อมูลข่าวสารนี้ บ่อยครั้งที่เราจะต้องใช้ข้อมูลในการตัดสินใจ และถ้าเรื่องนั้นเป็นเรื่องที่สำคัญ การตัดสินใจผิดย่อมสร้างผลกระทบอย่างมหาศาล ในบทความนี้เราจะมาพูดถึงเรื่องของความลำเอียง (Bias) ด้านการทำงานเกี่ยวกับข้อมูล เพื่อช่วยให้เพื่อนๆ ไม่ตกหลุมพรางจนตัดสินใจผิดผลาดไป
ตัวอย่างที่ผมชอบมากคือ กรณีของการวิเคราะห์ข้อมูลของนักวิจัยในสมัยสงครามโลก เพื่อที่จะหาว่าจะเพิ่มเกราะป้องกันให้เครื่องบินตรงไหนดี เพื่อให้นักบินมีโอกาสรอดตายมากขึ้น (เพิ่มทั้งลำไม่ไหว เดี๋ยวบินไม่ขึ้นพอดี)
ซึ่งเค้าได้เก็บข้อมูลจากเครื่องบินที่กลับมาที่ฐานทัพทั้งหมดว่าถูกยิงที่จุดไหนบ้าง?
ซึ่งก็ได้ดังรูป (จุดแดงคือจุดที่ถูกยิง)

เพื่อนๆ คิดว่าเค้าควรจะติดตั้งเกราะป้องกันเพิ่มตรงบริเวณไหนดีครับ?
ถ้าคิดเร็วๆ ก็ต้องเพิ่มเกราะตรงจุดที่มีสีแดงเยอะๆ สิ เพราะว่าถูกยิงเยอะบริเวณนั้น…. ใช่มะ?
แต่การคิดแบบนี้ผิดโดยสิ้นเชิง เพราะจริงๆ แล้วเครื่องบินน่ะมีโอกาสถูกยิงทั้งลำนั่นแหละ แต่ลำที่โดนยิงตรงจุดที่ไม่ใช่สีแดงเนี่ยไม่มีโอกาสรอดกลับมาให้เก็บข้อมูลเหมือนกับกลุ่มนี้
ดังนั้นแปลว่าสิ่งที่เห็นคือเป็นข้อมูลที่ได้จากผู้รอดชีวิต (Survivor) เท่านั้น ไม่ใช่ข้อมูลที่ครบถ้วนจริงๆ มันถึงมีชื่อเรียก Bias หรือความลำเอียงแบบนี้ว่า “Survivorship Bias” นั่นเอง
แปลว่าถ้าคิดให้ลึกซึ้งขึ้นไปอีก เราควรเพิ่มเกราะตรงจุดที่ไม่ใช่สีแดงด้วยซ้ำ เพราะเป็นจุดที่โดนยิงแล้วตายเลย ไม่มีโอกาสรอดกลับมา ซึ่งเป็นคนละเรื่องละราวกับการตัดสินใจครั้งแรกเลย ดูสิว่า Bias อันตรายขนาดไหน!!
ดังนั้นเรามาดูกันดีกว่าว่ามี Bias เกี่ยวกับอะไรบ้าง ซึ่งการแบ่งประเภท Bias ผมได้ทำการจัดกลุ่มในลักษณะที่ผมคิดว่าเหมาะสม โดยพยายามเรียง Bias ตาม Step การทำงาน ตั้งแต่การเก็บข้อมูล การประมวลผล และการตีความผลลัพธ์เลย
Bias ในขั้นตอนการเก็บข้อมูล
1. Observer Effect
ความลำเอียงนี้เกิดขึ้นเมื่อ “ผู้ที่ถูกเก็บข้อมูลทำตัวไม่ปกติเพราะรู้ว่ามีคนคอยจับตาเป็นพิเศษ” เช่น ถ้าพนักงานรู้ว่าทีมตัวเองช่วงนี้กำลังถูก Monitor เค้าก็จะทำตัวดีผิดปกติ ทำให้ผลงานหรือค่าที่วัดได้ “ดูดีเกินจริง”
หรือแม้แต่การที่ถ้าผู้ถูกวัดต้องเปิดเผยตัวตนว่าได้ให้ความคิดเห็นยังไง ประเมินผลยังไง หรือลงคะแนน Vote แบบไหน ก็อาจจะมีผลต่อการตัดสินใจก็ได้ เพราะการ Vote บางแบบที่ตรงกับใจตนเอง อาจไม่ตรงใจกับเจ้านายที่เฝ้ามองอยู่…
ทางแก้เบื้องต้นคือ ต้องวัดแบบไม่ให้รู้ตัว หรือ อาจวัดให้นานขึ้น จนไม่สามารถ Fake ไหว (ถ้า Fake นานได้ก็ดีไปอีกแบบ) ถ้าเป็นการ Vote หรือการประเมินผลก็ต้องทำแบบ Anonymous ไม่ให้รู้ว่าใครเป็นผู้ให้คะแนนเป็นต้น
2. Survivorship Bias
อันนี้อธิบายไปแล้วในตัวอย่างเครื่องบิน แต่จริงๆ แล้วก็มีอีกหลายเรื่องเลยเช่น การใช้ชัวิตของคนดังที่ลาออกจากมหาลัยแล้วประสบความสำเร็จมากกมาย (ทั้งๆที่ไม่ได้เอาคนที่เรียนไม่จบทั้งหมดมาคิด) การวิเคราะห์ผลดำเนินงานของกองทุนรวมต่างๆ ส่วนใหญ่เราจะเผลอเอากองทุนที่เหลือรอดมาคิดเท่านั้น เพราะกองทุนที่ไม่รอดมันผิดตัวทิ้งไปหมดแล้ว เป็นต้น
ทางแก้เบื้องต้น คือ อย่าลืมคิดว่า มีอะไรที่เรามองไม่เห็น หรือไม่มีข้อมูลหรือไม่? ทำไมจึงไม่มีข้อมูลนั้น? ซึ่งการไม่มีข้อมูล บางทีก็บอกอะไรได้มากกว่าการที่มีข้อมูลด้วยซ้ำไป…
3. Selection / Sampling Bias
อันนี้เกิดจากการที่กลุ่มตัวอย่างที่เราไปเก็บมา ไม่ได้เป็นตัวแทนประชากรที่ดี เช่น อาจเก็บมาเฉพาะกลุ่มที่เราสนใจเท่านั้น หรืออาจมีเหตุการณ์บางอย่างที่ทำให้กลุ่มนึงมาตอบ อีกกลุ่มไม่ตอบ (ก็กลายเป็น Survivorship อีก)
ถ้าเราวิเคราะห์ค่าจากกลุ่มที่ไม่ใช่ตัวแทนที่ดี ผลที่ได้ก็ย่อมจะไม่สะท้อนประชากรที่แท้จริง
ดังนั้นทางแก้ก็คือ ต้องสุ่มข้อมูลให้เป็นกลาง เช่น มีประชากรอยู่ 1,000 คน เราสัมภาษณ์ไหวแค่ 100 คน เราอาจเอาชื่อคน 1000 คนมาเรียง
จากนั้นใส่ฟังก์ชัน RAND ใน Excel เพื่อทำการสุ่มเลข 0-1 (เป็นจุดทศนิยม)
แล้ว Copy Paste Value ไว้ไม่ให้ค่าเปลี่ยน

แล้ว Sort เอา 100 คนแรกมาสัมภาษณ์เจาะลึก เป็นต้น

4. Measurement Bias
อันนี้เกิดจากการวัดที่ไม่เที่ยงตรง อาจเป็นที่ตัวเครื่องมือวัดไม่เสถียร ทำให้วัดค่าได้แกว่งไปแกว่งมา เมื่อการวัดค่าไม่ได้เรื่อง การวิเคราะห์ในขั้นตอนต่อไปก็ย่อมจะแย่ไปตามกัน ดังที่บอกว่า Garbage-in Garbage-Out นั่นแหละครับ
วิธีแก้ก็คือ พยายาม Calibrate เครื่องมือด้วย หรือลองวัดกับตัวอย่างเดิมซ้ำๆ ว่าค่าที่ได้แกว่งหรือไม่
Bias ในขั้นตอนการคำนวณ
5. Outliers
การคำนวณด้วยค่าเฉลี่ยเลขคณิต (Mean หรือใน Excel คือ AVERAGE) จะถูกดึงค่าให้เบี้ยวโดยค่าที่น้อยผิดปกติมากๆ หรือ เยอะผิดปกติมากๆ ซึ่งเราเรียกค่าที่น้อยหรือเยอะผิดปกตินี้ว่า Outlier ซึ่งภาษาชาวบ้านเรียกปรากฏการณ์นี้ว่ามีการดึง Mean (ให้เบี้ยวไป) เช่น ในรูปข้างล่าง ค่า Mean เงินเดือนตั้งเกือบแสนเจ็ด ทั้งนี้เพราะดันมีคนเงินเดือนเป็นล้านอยู่ด้วย
วิธีแก้ก็อาจจะตัด Outlier ก่อนแล้วค่อยคำนวณ หรือจะเปลี่ยนไปใช้ค่ากลางตัวอื่นที่ไม่ได้รับผลจาก Outlier เช่นค่า MEDIAN แทนก็ได้ เพราะว่า MEDIAN จะเอาข้อมูลมาเรียงกันจากน้อยไปมากแล้วดูว่าค่าไหนอยู่ตรงกลาง ซึ่งการทำแบบนี้จะไม่ได้รับผลการฉุดดึงจาก Outlier เลย

6. Simpson’s Paradox
เป็นปรากฏการณ์ที่ผลสรุปของกลุ่มย่อย ดันดูขัดแย้งกับผลสรุปในกลุ่มใหญ่กว่า ตัวอย่างเช่นอันนี้

ถ้าเราได้ข้อมูลแบบนี้มา เราก็คงคิดว่า ผู้หญิงเนี่ยมาสายกว่าผู้ชายเนอะ ดูสิ สายกว่าทั้งสองแผนกเลย แย่จัง!
แต่ถ้าเรามาดูตัวเลขตัวรวม และดูที่มาจากเลขดิบอาจจะได้ข้อสรุปอีกแบบ
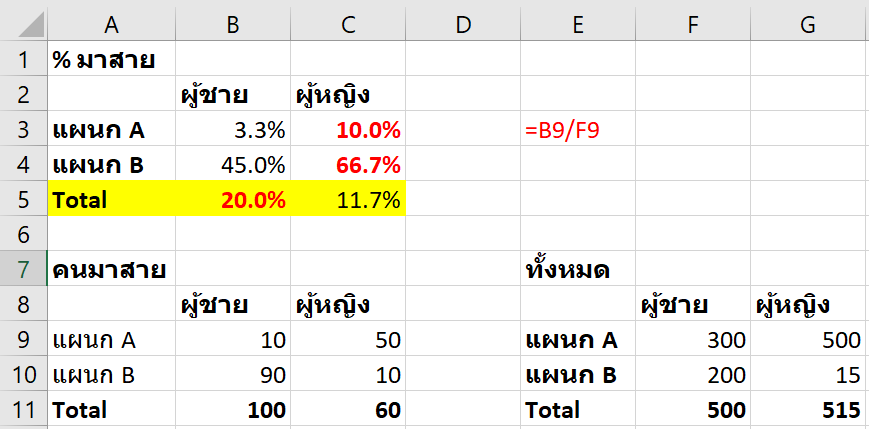
กลายเป็นว่า พอดูภาพรวมปุ๊ป ผู้ชายดันมี % การมาสายสูงกว่าผู้หญิงตั้งเกือบ 2 เท่า ทั้งๆ ที่ตอนดูแยกแผนก สัดส่วนของผู้หญิงที่มาสายดันมากกว่าตั้งเยอะ!
ทั้งนี้เพราะว่าเลข 66.67% ที่ดูเยอะ มาจากกลุ่มที่มีแค่ 15 คนเอง แต่ 10% นั่นมาจากตั้ง 500 คน การ Weight จึงเยอะว่า ซึ่งกลับด้านกับของผู้ชายเลย
นี่แหละความน่ากลัวของการดูข้อมูล หึหึ
Bias ในขั้นตอนการตีความผลลัพธ์
7. Correlation bias
Bias นี้ก็เจอบ่อยมากเลย โดยเฉพาะเวลาคนพยายามหาความสัมพันธ์ระหว่าง 2 ตัวแปร เช่น X กับ Y แล้วเห็นว่ามันมี Correlation กัน คือวิ่งแบบสัมพันกัน รู้ค่า X แล้วสามารถทำนาย Y ได้
ปัญหาคือ เรามักจะเผลอคิดไปด้วยว่า X จะต้องเป็นสาเหตุทำให้เกิด Y ด้วยก็เลยจะพยายามที่จะเพิ่ม X เพื่อให้ได้ Y มากขึ้น ซึ่งบางทีก็เป็นอย่างนั้นจริง แต่บางทีมันก็ไม่ใช่! (หรือบางที Y นั่นแหละที่ทำให้เกิด X ซึ่งกลับกันเลย)
เพื่อนๆ เคยได้ยินประโยคนี้มั้ย? “Correlation does not imply Causation” หรือแปลเป็นไทยว่า “มีความสัมพันธ์กันไม่ได้หมายความว่าเป็นเหตุผลซึ่งกันและกัน”
ถ้าอยากดูตัวอย่าง Correlation ประหลาดๆ ก็ลองเข้าไปดูได้ที่ tylervigen.com นี่เลย
มันมีลูกเล่นให้เราลองหา Correlation แปลกๆ ด้วยตัวเองได้ด้วย โดยไปที่หน้านี้ เช่น ที่ผมทำอันนี้เป็น Correlation ระหว่างจำนวนคนที่ตายจากการตกเตียง กับ จำนวนเงินที่จ่ายไปกับสัตว์เลี้ยง ซึ่งมี Correlation ตั้ง 94% แน่ะ (หรือว่าจริงๆ สัตว์เลี้ยงคือฆาตกร!!)

ป.ล. ที่แปลกกว่าคือ มีคนเก็บสถิติการตกเตียงตายด้วยเหรอ…เจ๋งจริงๆ
ทางแก้ Bias คือ เราต้องหาเหตุผลให้ได้ว่า X มันทำให้ Y เปลี่ยนแปลงได้ยังไง มีกลไกอะไร? อาจต้องทำการทดลองว่าเพิ่ม X ลด X แล้ว Y เปลี่ยนจริงรึเปล่า? และต้องควบคุมการทดลองให้ดีด้วยนะ ไม่ใช่ยังมีตัวแปรปริศนา Z ซ่อนตัวอยู่อีก แบบนั้นการสรุปผลของเราอาจจะผิดก็ได้
8. Gambler’s Fallacy
อันนี้มักเกิดขึ้นกับนักเสี่ยงโชค ที่คิดว่าสถิติหรือแนวโน้มบางอย่างในอดีตจะสามารถช่วยให้คาดการณ์เหตุการณ์ในอนาคตได้ ทั้งๆ ที่จริงๆ ไม่ได้เกี่ยวกันเลย

สมมติผมโยนเหรียญปกติ (ไม่ได้โกง) แล้วมันออกหัวไป 5 รอบติดกัน
ถามว่าตาต่อไป โอกาสออกหัวหรือก้อยจะเยอะกว่ากัน?
คำตอบคือ ถ้าเหรียญไม่ได้โกง มันก็จะยังมีโอกาสออกหัวอยู่ 50% เช่นเดิมตามปกติ ไม่ได้เกี่ยวอะไรกับที่เคยออกหัวไปแล้ว 5 รอบติดเลย
9. Confirmation bias
อันนี้เป็นการพยายามวิเคราะห์หรือสรุปข้อมูลเพื่อให้เข้าทางกับสิ่งที่ตัวเราเองมีความเชื่ออยู่ คือไม่ได้วางใจเป็นกลาง ซึ่งก็ค่อนข้างอันตรายเพราะว่าปกติคนเราก็มักจะเห็นเฉพาะสิ่งที่ตัวเองมองหาอยู่เท่านั้น
ตัวอย่างอันนึงที่ค่อนข้างน่าสนใจคือ คลิปให้นับว่ามีคนเสื้อขาวส่งบอลกี่ครั้ง?
คำตอบคือ 15 ครั้ง…
แต่มีคนเกินครึ่งที่ไม่เห็นคนใส่ชุดกอลิล่าที่เดินผ่านไปในคลิปนี้เลย…
นั่นเป็นเพราะปกติคนเราจะเห็นเฉพาะสิ่งที่เราสนใจเท่านั้น และเราก็จะ ignore ข้อมูลที่ไม่ได้ตรงกับใจเรา
ซึ่งเป็นกับทุกเรื่อง เรามักจะรับแต่ข้อมูลที่ Support ความคิดเรา และไม่สนใจข้อมูลของอีกฝ่าย ยิ่งยุคนี้ที่มี Social Media ยิ่งจะได้เห็นแต่ข้อมูลที่ตรงกับเรามากผิดปกติอีก (เพราะเค้าคิดว่าเราน่าจะชอบ) ซึ่งก็ต้องระวังกันไว้ พยายามเปิดใจรับฟังรอบด้านด้วย
ก่อนจากลา
วันนี้ผมขอจบบทความเท่านี้ดีกว่า หากเพื่อนๆ มีเรื่อง Bias อะไรน่าสนใจ ก็ Comment บอกกันได้นะครับ
และถ้าใครชอบบทความแนวนี้ ก็ยังมีเรื่องอื่นๆ อีกตามนี้เลย