


หลังจากที่เราทำการติดตั้ง ComfyUI ไปแล้วในตอนที่แล้ว ในตอนนี้ผมจะขออธิบายเรื่องของกระบวนการสร้างภาพ AI ให้พวกเราได้เข้าใจก่อน ซึ่งจะเป็นการอธิบายผ่าน Node พื้นฐานใน ComfyUI default workflow เลย เพื่อความง่าย
สิ่งที่คุณจะได้เรียนรู้ในบทความนี้ ได้แก่ ![]()
 ขั้นตอนการสร้างรูป AI ว่ามันทำงานอย่างไร จาก Noise เป็นภาพได้ยังไง
ขั้นตอนการสร้างรูป AI ว่ามันทำงานอย่างไร จาก Noise เป็นภาพได้ยังไง- เทคนิคการกำหนด Prompt เพื่อควบคุมลักษณะของภาพให้ตรงใจคุณมากที่สุด
- บทบาทสำคัญของการตั้งค่า Steps, CFG, Sampler และ Scheduler ที่ส่งผลอย่างมากต่อผลลัพธ์สุดท้าย
- การทำงานกับ Node ต่างๆ ใน ComfyUI เพื่อสั่งงาน AI ได้อย่างครบวงจร
 พร้อมด้วยความรู้เพิ่มเติมอีกเพียบที่รอให้คุณค้นพบ
พร้อมด้วยความรู้เพิ่มเติมอีกเพียบที่รอให้คุณค้นพบ
ไม่ว่าคุณจะเป็นมือใหม่ที่กำลังเริ่มศึกษา AI Art ![]() หรือเป็นผู้เชี่ยวชาญที่ต้องการเพิ่มพูนทักษะ
หรือเป็นผู้เชี่ยวชาญที่ต้องการเพิ่มพูนทักษะ ![]() บทความนี้จะช่วยให้คุณสามารถใช้ Stable Diffusion เพื่อสร้างผลงานอันน่าทึ่งได้อย่างเต็มประสิทธิภาพแน่นอน
บทความนี้จะช่วยให้คุณสามารถใช้ Stable Diffusion เพื่อสร้างผลงานอันน่าทึ่งได้อย่างเต็มประสิทธิภาพแน่นอน ![]()
แต่ที่สำคัญ บทความนี้ยาวและรายละเอียดเยอะมาก ดังนั้นค่อยๆ ทำความเข้าไปใจนะครับ !!
กระบวนการ Generate รูป AI
เราจะต้องเข้าใจก่อนว่า เวลาที่ AI มันสร้างรูป โดยเฉพาะ Stable Diffusion ที่ใช้หลักการของ Diffusion Model มาสร้างรูปนั้น มันจะมีกระบวนการดังนี้
ภาพที่มี Noise มาก –> AI ลด Noise ลง (ตามเงื่อนไขบางอย่าง) –> ภาพที่มี Noise น้อยลง
แล้วกระบวนการนี้จะทำซ้ำไปเรื่อยๆ หลายๆ รอบ (Steps) จนภาพผลลัพธ์สุดท้ายไม่เหลือ Noise เลย
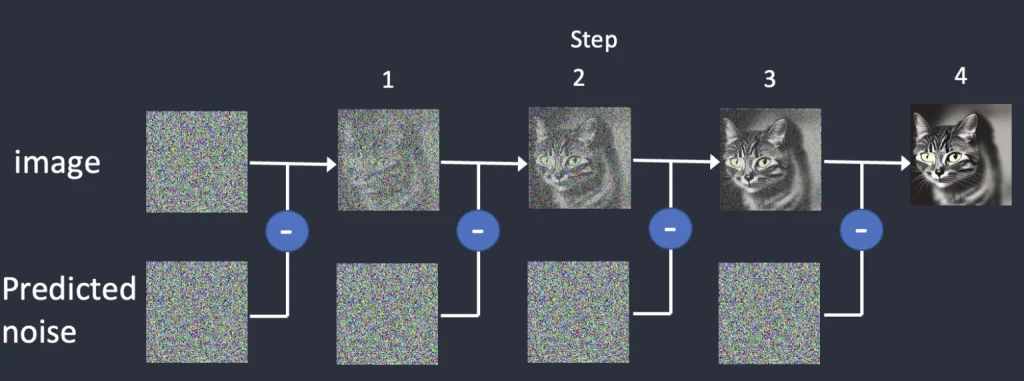
อย่างไรก็ตามไอ้จุด Noise ตั้งต้นมันเละจนดูไม่รู้เรื่องหรอก ดังนั้นตอนมันจะลด Noise ลงแต่ละขั้นตอน มันอาจจะได้กลับคืนออกมาเป็นรูปอะไรก็ได้ทั้งนั้น และอาจไม่เหมือนรูปที่ใช้เทรนได้ด้วย
ซึ่งขึ้นอยู่กับการเรียนรู้จากข้อมูลภาพต้นฉบับที่ใช้ train โมเดล และเงื่อนไข (Condition) ที่เราใส่เข้าไปตอนที่เรากำลัง Gen รูป
เงื่อนไขที่ว่า เช่น
- Text Prompt = กำหนดการสร้างรูปด้วยข้อความ เช่น Cat, Small Dog, Beautiful Woman แบบที่เราเล่นไปใน EP01 เป็นต้น
- IP Adapter = กำหนดการสร้างรูปด้วยรูป (IP=Image Prompt) เดี๋ยวจะสอนในตอนหลังๆ
- ControlNet = กำหนดการสร้างรูปด้วยวิธีอันหลากหลาย เช่น Pose, ความลึก, ลายเส้น เดี๋ยวจะสอนในตอนหลังๆ
ความสามารถในการปลด Noise ออก แล้วสร้างเป็นรูปตามเงื่อนไขของเราเนี่ยแหละ คือ กระบวนการสร้างรูป AI ซึ่งมันจะถูกดำเนินการในกล่อง หรือ Node ที่ชื่อว่า KSampler
เริ่มจาก Default Workflow ก่อน
ก่อนอื่นให้เราเข้า ComfyUI แล้วกด “Load Default” ด้านขวา เพื่อโหลด workflow มาตรฐานได้เลย (ผมยังใช้ Model Realistic Vision อันเดียวกับ EP01 นะ)
คุณจะเห็น Node ประมาณนี้ (ซึ่งผมลากย้ายที่เล็กน้อย จะได้มองเห็นเส้นชัดๆ)
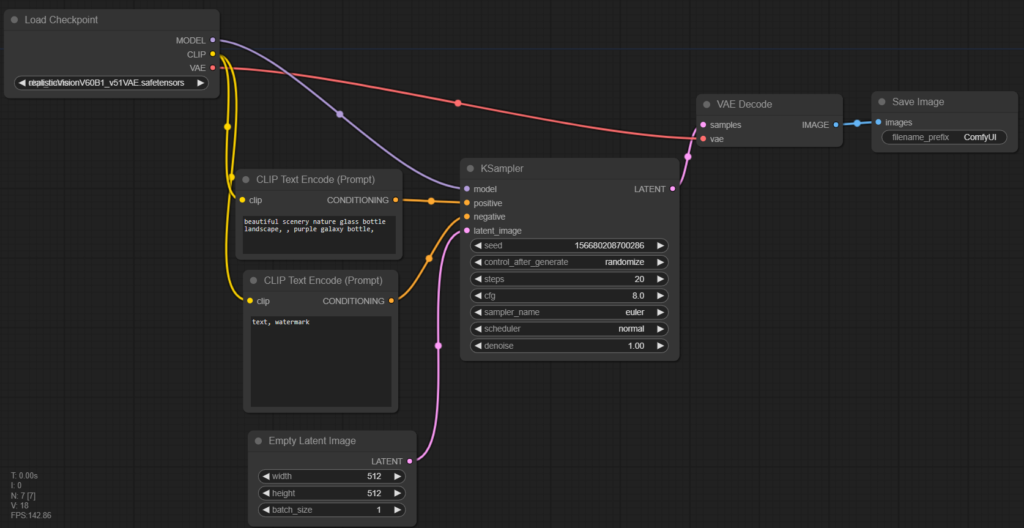
แต่ละ Node (หรือกล่องๆ) จะมีตุ่มๆ อยู่ 2 ฝั่งนะ แล้วแต่ละตัวก็บอกด้วยว่ามันต้องส่งข้อมูลประเภทไหน (แยกด้วยสี) เช่น ดูที่ KSampler ในรูปนี้
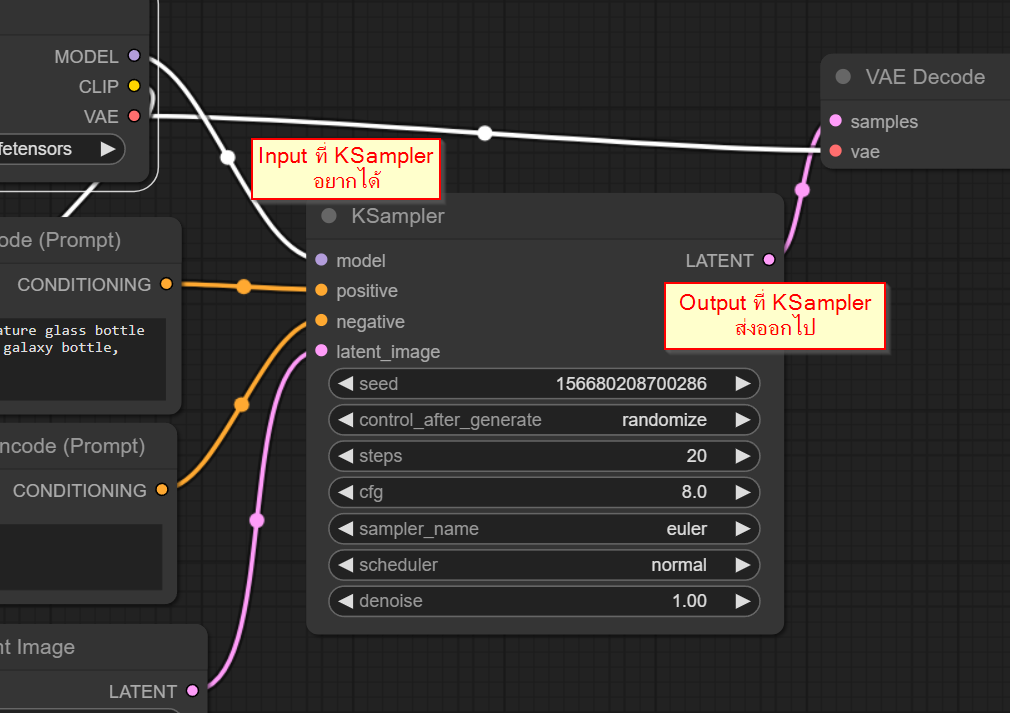
- ตุ่มด้านซ้ายคือ Input : เราส่งข้อมูลเข้าไปใน Node ผ่านทางนี้ แล้วบอกว่ามันต้องการข้อมูลแบบไหน
- ตุ่มด้านขวาคือ Output : เราส่งข้อมูลออกจาก Node ผ่านทางนี้ แล้วบอกว่ามันส่งข้อมูลแบบไหนออกไป
แปลว่า KSampler หรือกระบวนการลด Noise หลายๆ Steps นั้น ต้องการ
- Input คือ Model, Positive Condition, Negative Condition และ Latent Image เริ่มต้น
- Output คือ Latent ผลลัพธ์ ที่ลด Noise ไปแล้วนั่นเอง
Nerd Stuff : คำว่า Latent (แปลว่า ซ่อนเร้น) หมายถึง ตัวเลขเวกเตอร์หรือเมทริกซ์ ที่ AI เข้าใจ ซึ่งจะทำหน้าที่เป็น “ตัวแทน” ข้อมูลดิบ (เช่น รูปภาพ) ที่เก็บเฉพาะคุณลักษณะหลักๆ สำคัญๆ ของข้อมูลดิบเอาไว้ ทำให้ขนาดเล็กลงมากซึ่งจะสะดวกต่อการประมวลผลของโมเดล AI มาก
โดยที่ปกติแล้วเรา Gen รูปแต่ละครั้งรูปมันจะเปลี่ยนไปเรื่อยๆ ทั้งนี้เป็นเพราะมีการ Random ค่า Seed เอาไว้ทักครั้งที่กด Generate เช่น ถ้าลองกด Queue Prompt อีกที ภาพก็จะเปลี่ยนไป เพราะเลข Seed เปลี่ยน
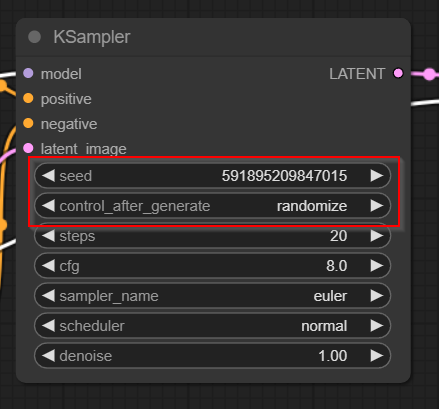

ดังนั้นเพื่อให้สะดวกในการเรียนรู้ในบทความนี้ ผมจะขอให้ตรึงหรือ Fixed ค่า Seed เอาไว้ที่เลข “555” แล้วกัน
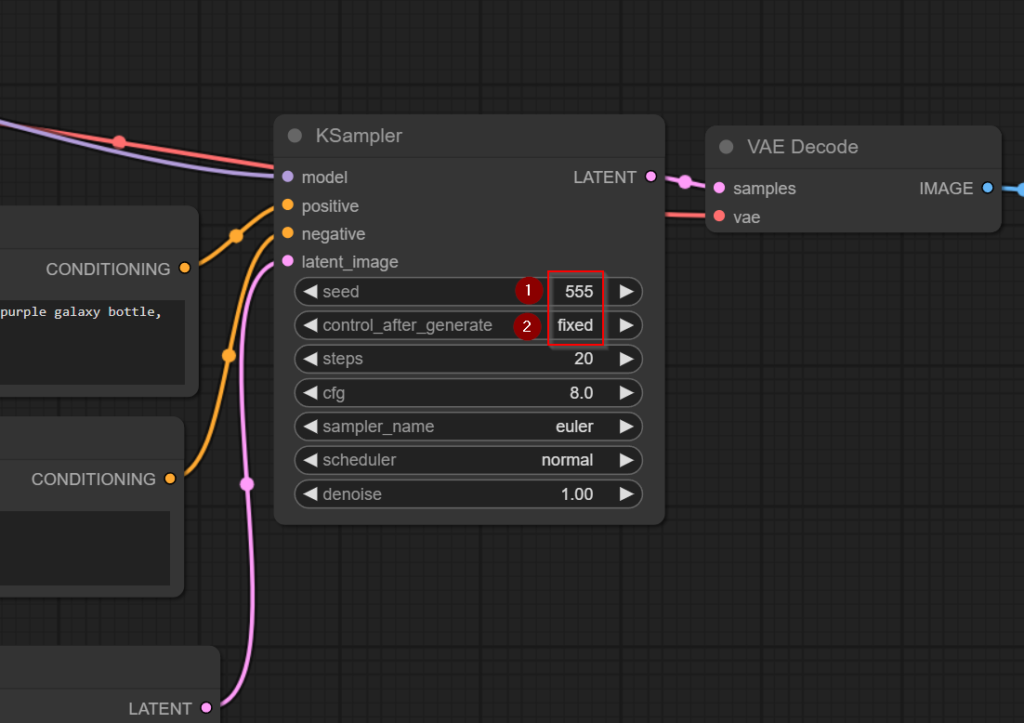
เมื่อกด Queue Prompt จะได้รูปนี้ ซึ่งน่าจะตรงกับผมแล้ว ถ้าเราใช้ Model เดียวกัน

ก่อนจะไปอธิบาย KSampler โดยละเอียดมากกว่านี้ ผมขออธิบายจาก Node ซ้ายไปขวา พร้อมทั้งบอกคำศัพท์ต่างๆ ที่เราควรรู้ก่อนละกันนะครับ
Load Checkpoint
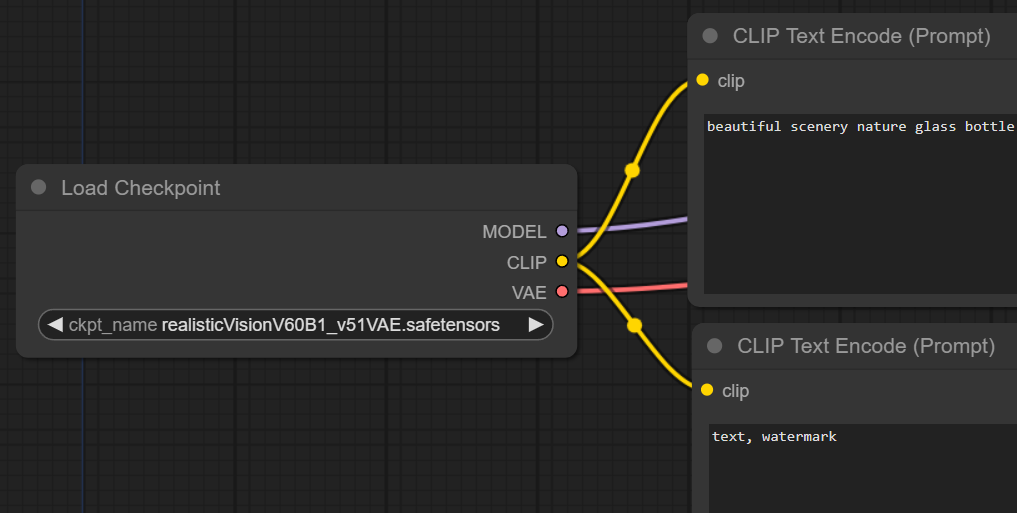
เคยสงสัยไหมว่าถ้าเราสั่งให้วาดรูปแมวใน Text Prompt แล้ว AI มันวาดออกมาเป็นรูปร่างแมวถูกต้องได้ยังไง? มันต้องมีส่วนที่เคยเรียนรู้เรื่องการวาดแมวมาก่อน จริงมะ? นั่นก็คือตัว Checkpoint Model นั่นเอง
สังเกตว่า Load Checkpoint นี้จะไม่มี Input จาก Node อันอื่นเลย เพราะ Concept ของมันคือการเลือกโหลด Checkpoint Model จากไฟล์ว่าจะใช้ตัวไหน (ซึ่งเรามักจะไปโหลดมาจาก https://civitai.com/)
ส่วน Output ของ Node นี้ก็จะมี 3 อัน เพราะว่า ใน 1 CheckPoint สามารถมีองค์ประกอบได้มากสุด 3 ส่วน คือ Model (Unet), CLIP , VAE (บาง Checkpoint อาจมีไม่ครบ เช่น ไม่ได้ใส่ VAE มา)
- Model (Unet) : เป็นตัว Model ที่เรียนรู้การลด Noise ให้กลายเป็นรูป (Concept เวลาอธิบายการทำงานละเอียด จะวาด Diagram รูปร่างคล้ายตัว U เลยเรียกกันว่า Unet) ทำหน้าที่เหมือนตัวศิลปินที่มีทักษะวาดรูป AI ซึ่งการที่มันจะรู้ว่าจะสร้างรูปแมวยังไง รูปคนยังไง อยู่ที่ตัวนี้เลย
- CLIP : เป็นตัวที่สามารถแปลงข้อความ Text Prompt ที่เราระบุให้เป็น Token แล้วค่อยแปลงเป็นตัวเลขที่ AI เข้าใจ เรียกว่า Text Embedding
- VAE : (ย่อมาจาก Variational Auto Encoder) เป็นตัวแปลงข้อมูลรูป ระหว่าง Pixel Space (รูปในโลกจริง) กับ Latent Space (รูปในโลกของ AI) ซึ่งเป็นพื้นที่ที่ข้อมูลถูกบีบอัดให้เล็กลงจน AI ทำงานสะดวก
Nerd Stuff: CLIP และ VAE จะเปลี่ยน ข้อมูลดิบ (เช่น Text หรือ รูป) ให้อยู่ในมิติที่ต่ำลงไว้ใน Latent Space ทำให้รูปมีขนาดเล็กลงมาก (ด้านละ 8 เท่า = กว้าง x ยาว = 8×8 = 64 เท่า) ซึ่งจะสะดวกต่อการประมวลผลของโมเดล AI มาก
เรื่อง Advanced เกี่ยวกับการ Load Model
ซึ่งนอกจาก Checkpoint Loader ที่โหลดทีเดียว 3 ก้อนแล้ว ใน ComfyUI มีโหนดที่สามารถโหลดแยกก้อนกันได้ด้วย เช่น หากเราดับเบิ้ลคลิ๊กที่ว่างๆ ใน Workflow แล้ว Search คำว่า Load จะเห็นแบบนี้
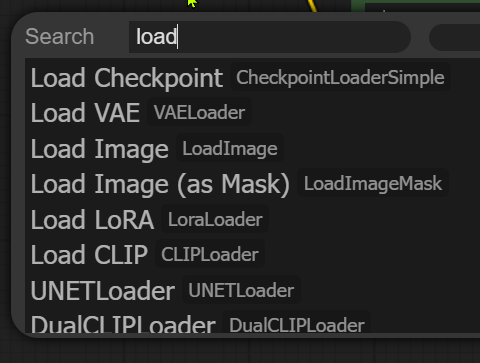
- UNET Loader : โหลดแต่โมเดลที่มีแค่ Model Unet
- Load CLIP : โหลดแต่ CLIP Model
- Load VAE : โหลดแต่ VAE Model (ตัวนี้ใช้บ่อยสุด)
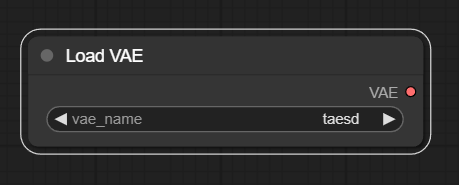
แต่การโหลดแยกแบบนี้เราไม่ค่อยได้ใช้หรอก ยกเว้น Load VAE อาจได้ใช้บ้าง กรณีที่ Checkpoint หลักไม่มี VAE ฝังมาด้วยนั่นเอง
CLIP Text Encode
ถัดไป ผมขอพูดถึงเรื่องของการระบุ Text Prompt ซึ่งมันจะอยู่ใน Node ที่เรียกว่า CLIP Text Encode
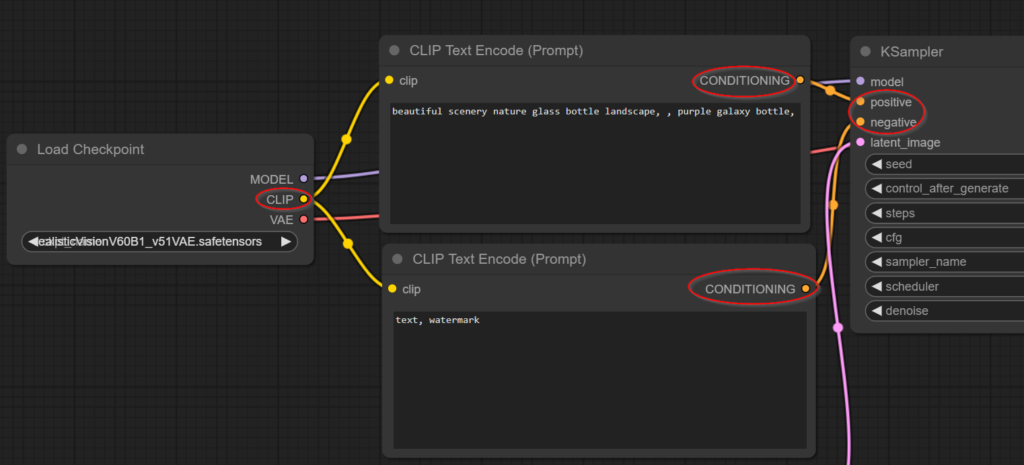
เป็นกล่องที่เอาไว้ให้เราระบุ Text Prompt หรือข้อความที่จะเป็น Condition ในการสร้างรูป ซึ่งคือที่ที่เราลองเปลี่ยน Prompt เล่นในตอน EP01 นั่นเอง
CLIP Text Encode จะรับ Input เป็น Text Prompt ที่เราระบุไป แล้วใช้ Input จาก Model CLIP ที่ส่งมาจาก Load Checkpoint ทำการแปลงให้เป็น สิ่งที่ AI เข้าใจ เรียกว่า Text Embedding เพื่อส่ง Output ไปกำหนด Condition ให้ KSampler อีกที
ถ้าใครสังเกต จะเห็นว่ามันมี CLIP Text Encode อยู่ 2 กล่องด้วยกัน กล่องนึงต่อเข้าคำว่า Positive ของ KSampler อีกกล่องต่อเข้า Negative ของ KSampler
- ตัวที่ต่อเข้า Positive เป็น Positive Prompt = ตัวกำหนดสิ่งที่เราอยากได้ในภาพ
- ตัวที่ต่อเข้า Negative เป็น Negative Prompt = ตัวกำหนดสิ่งที่เราไม่อยากได้ในภาพ
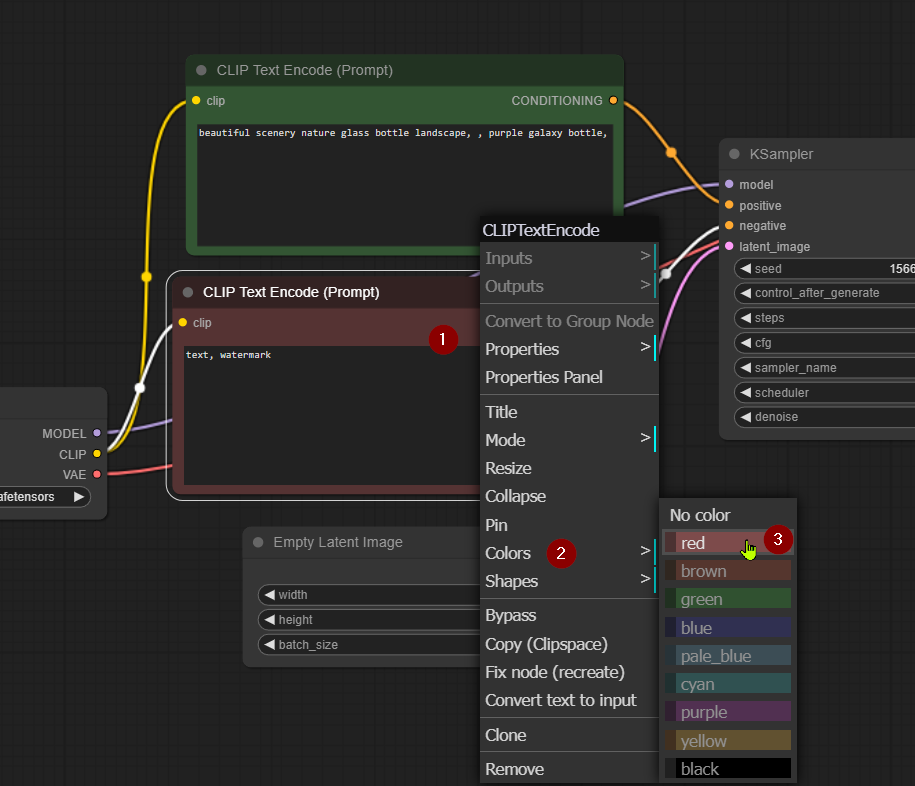
ซึ่งตรงนี้เราสามารถกำหนดสีของกล่อง Node ได้นะ จะได้เห็นชัดเจนขึ้น เช่น
ทำให้ CLIP Text Encode ที่ทำหน้าที่เป็น Positive Prompt เป็นสีเขียว และอีกอันเป็นสีแดง โดยการคลิ๊กขวาที่กล่อง แล้วเลือก Colors ที่ต้องการได้เลย
ลองปรับ Weight ของ Text Prompt
ถ้าใครสังเกตว่า Prompt ที่ผมใส่ใน EP01 มีวงเล็บและเลขแปลกๆ ด้วย
เช่น (realistic photo:1.25) มาดูกันว่ามันแปลว่าอะไร?
เราระบุน้ำหนักได้ในรูปแบบ (keyword:น้ำหนัก)ซึ่งเราสามารถใช้วิธี Highlight คำนั้นแล้วกด Ctrl+ขึ้น หรือ Ctrl+ลง เพื่อเพิ่ม/ลดน้ำหนักได้
- ถ้า keyword ไม่ระบุอะไรเพิ่มเลย และไม่มีวงเล็บด้วย คือน้ำหนัก 1
- (keyword:1.5) แปลว่า ให้น้ำหนัก 1.5 เท่าของปกติ
- (keyword:0.5) แปลว่า ให้น้ำหนักครึ่งนึงของปกติ (ลดน้ำหนักลงไป 2 เท่า)
- การใส่ (keyword) มีค่าเท่ากับน้ำหนัก 1.1 หรือ (keyword:1.1)
- การใส่ ((keyword)) มีค่าเท่ากับ (keyword:1.21) ซึ่งเกิดจาก 1.1*1.1
- การใส่ [keyword] คือ ลดน้ำหนักลงไป 1.1 เท่าของปกติ = (keyword:0.909)
Nerd Stuff: วิธีการที่ ComfyUI กับ Automatic1111 Weight น้ำหนัก Prompt จะไม่เหมือนกันนะครับ
Comfy มันเพิ่ม Weight เฉพาะ Keyword ที่เราใส่ตรงๆ
แต่ว่า Automatic1111 จะทำการถ่วงน้ำหนักเป็น Portion กับคำอื่นด้วย
ซึ่งทำให้ Comfy ควบคุมเฉพาะ Keyword ง่ายกว่า (แต่ก็ถ้าเพิ่มมากไปภาพก็จะพังได้)
มาดูตัวอย่างกัน (อย่าลืมว่า รูปเดี่ยวๆ พวกนี้คุณสามารถ Save แล้วลากลง ComfyUI ของคุณ เพื่อเอา Workflow ทั้งหมดได้เลยนะ)
photo of black cat and yellow flower in blue sky
ลองเพิ่มน้ำหนักให้ดอกไม้เหลือง จะเห็นว่าในรูปจะให้ความสำคัญกับดอกไม้เหลืองมากขึ้น
photo of black cat and (yellow flower:1.4) in blue sky
ลองลดน้ำหนักของแมวดำให้ลดลงไปอีก
photo of (black cat:0.75) and (yellow flower:1.4) in blue sky
ลองใส่ Negative Prompt
สมมติว่าผมไม่อยากได้ใบไม้กับก้อนเมฆในรูป ผมก็อาจใส่คำว่า leaf กับ cloud ลงไปใน Negative Prompt พร้อมกันเลยก็ได้ (ปรับ Positive กลับมาเป็นแบบปกติก่อน) สรุปคือ
Positive:
photo of black cat and yellow flower in blue sky
negative:
text, watermark, leaf, cloudได้แบบนี้ จะเห็นว่าใบไม้มันกับก้อนเมฆลดลงไปจากภาพเลย

ป.ล. ถ้าเราเพิ่ม Weight ของ Leaf หรือ Cloud ที่ Negative Prompt มันก็จะยิ่งพยายามหนักขึ้นเพื่อไม่ให้มีสิ่งนั้น
เรื่อง Advanced ของ Text Prompt
นอกจากเรื่องของ Weight แล้ว จริงๆ แล้วมันยังมีประเด็นขั้นสูงเกี่ยวกับตัว Text Prompt อีก นั่นคือ การที่ระบบจะส่งข้อมูล Prompt ไปให้ KSampler ได้ Embedding ชุดละ 77 Tokens แปลว่าถ้าข้อความยาวเกินไป จะถูกแยกชุด Embedding กันโดยอัตโนมัติ
และบางทีใน Embedding เดียวกัน ดันมี Keyword ที่ทำให้ AI สับสน จับหลายๆ ตัวปนกันมั่วทำให้ภาพออกมาผิด เช่น
asian woman wearing yellow shirt and purple hatnegative : text, watermark เฉยๆ ก็พอ
ผลที่ได้สีปนกันมั่วเลย 555

แทนที่เราจะปล่อยให้ระบบจัดการ Embedding ให้เราแบบควบคุมไม่ได้ จริงๆ เราสามารถควบคุมมันได้ โดยใช้ Node ที่ทำหน้าที่รวม Condition หลายก้อนเข้าด้วยกัน
วิธีเรียกใช้ Node มี 2 วิธี คือ
1.Double Click ที่ว่างเปล่าบน Workflow แล้วหาคำว่า Con
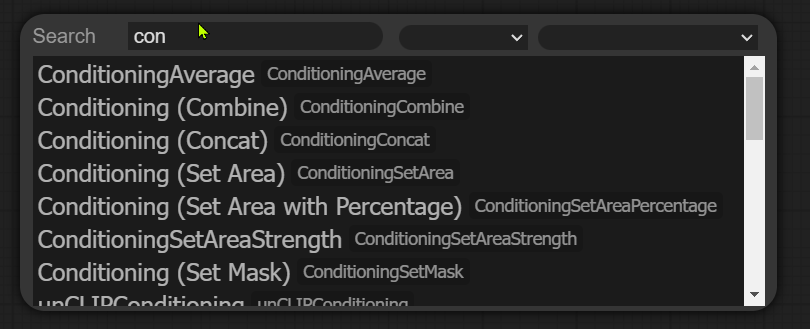
จะเจอ Code ที่มีคำว่า Conditioning เต็มเลย
2. ลากตุ่ม Condition ออกมาจาก Clip Text Encode จะมี Choice ให้เลือก
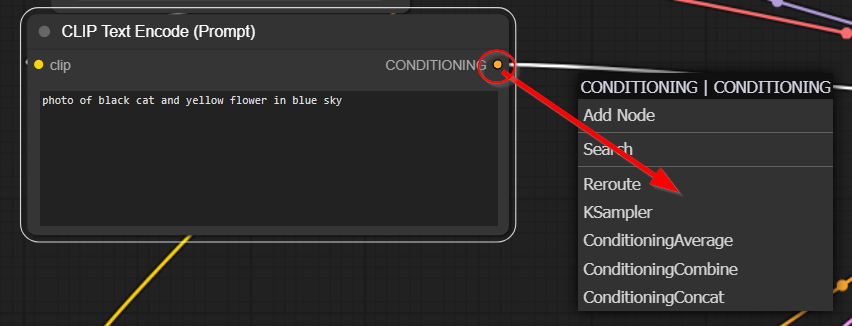
ซึ่งผมขอพูดถึง 3 ตัวนี้ก่อน
Conditioning Concat
เอา Embedding 2 ก้อนเป็นประโยคยาว ต่อกันแล้วส่งไปให้ KSampler ทีเดียว (ประโยชน์คือ Keyword ที่อยู่คนละ Embedding กันจะไม่ปนกันง่าย)
เราลองทดสอบ แยกเรื่อง yellow shirt กับ purple hat ให้อยู่คนละก้อนกัน แบบนี้
โดยการเชื่อมเส้น จะใช้การลากจากตุ่มฝั่งนึงไปปล่อยยังตุ่มอีกอันนึงนะ
จะลบเส้น ก็คลิ๊กที่กลมๆ ตรงกลางเส้นแล้ว Delete
(เราสามารถคลิ๊กขวาที่กล่อง Node เพื่อเปลี่ยนสีโดยกด Color ได้ เช่น ผมทำ Positive เป็นสีเขียว , Negative เป็นแดง จะได้ดูง่ายๆ)
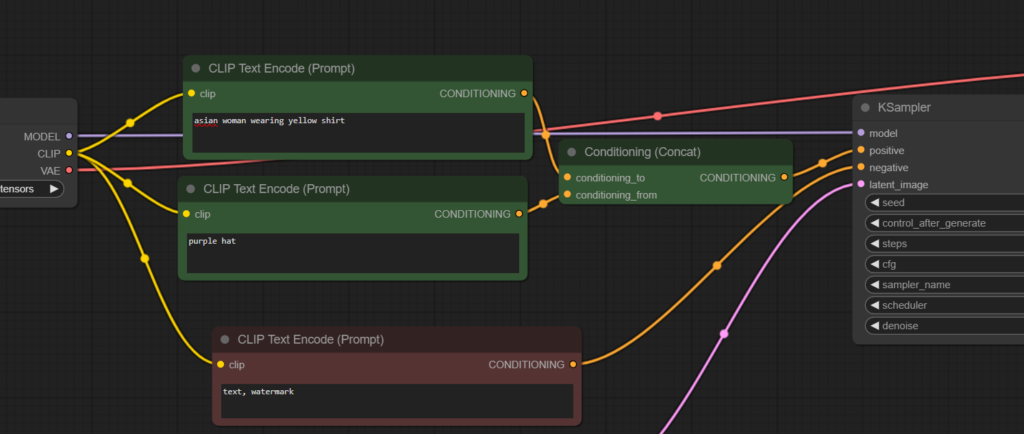
ผลลัพธ์จะได้แบบนี้เลย คือ ไม่ได้การันตีว่าสีจะไม่มั่ว แต่โอกาสที่สีมั่วจะน้อยลงมากๆ เพราะส่งแยกกันคนละชุด

ทีนี้ถ้าลองเลือกแบบอื่น เช่น Average กับ Combine บ้างล่ะ
Conditioning Average
เป็นการเอา Embedding 2 อันมาหาค่าเฉลี่ยเป็นก้อนเดียวก่อนส่งเข้า KSampler
ดังนั้นจะต้องตั้งค่า Conditioning To Strength หรือตั้งค่าความแรงของน้ำหนักในการเฉลี่ยให้กับฝั่ง to (ตัวแรกด้วย)
เช่น ถ้าตั้ง 0.4 แปลว่า ตัวแรก 40% ตัวสอง 60% ผลของตัวแรกจะน้อยกว่า (คนเอเชียหาย เสื้อสีเหลืองหาย)

เช่น ถ้าตั้ง 0.6 แปลว่า ตัวแรก 60% ตัวสอง 40% ผลของตัวแรกจะมากกว่า (สีม่วงหายไป)

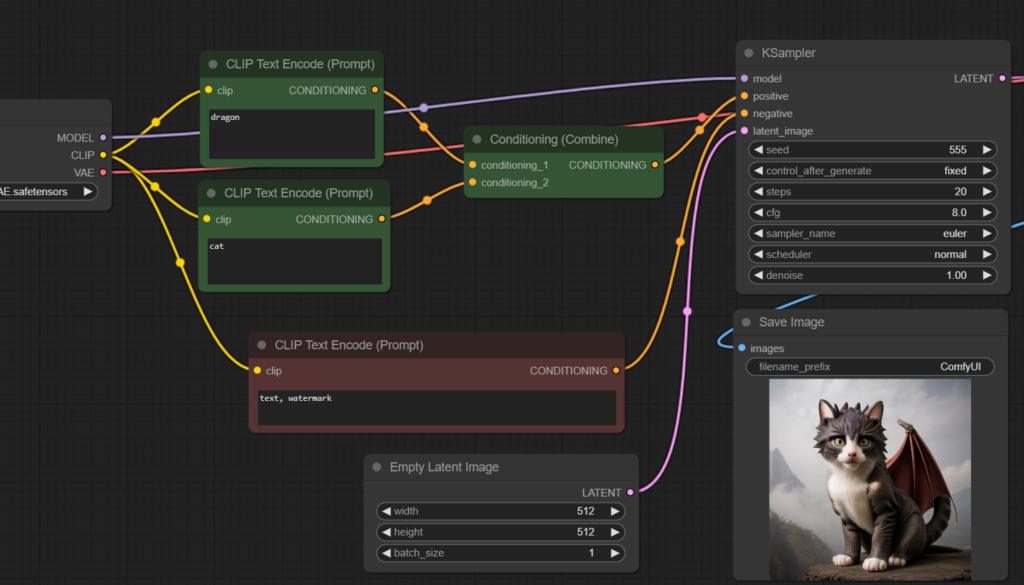
Conditioning Combine
เป็นการส่ง Embedding ไปสร้าง Noise 2 ชุด เหมือนจะสร้างรูปเริ่มต้น 2 รูปซ้อนกันในภาพเดียว แต่พอเริ่มลด Noise ก็ให้ KSampler เฉลี่ยๆ กันทีหลัง
ผลที่ได้ก็อาจจะแปลกๆ ไป อันนี้แล้วแต่ Prompt ด้วย หลายๆ ทีก็ Work นะ

ตัวอย่างการใช้ Conditioning Combine แล้วดู Work เช่นการผสมสัตว์คนละแบบเข้าด้วยกัน ผลที่ได้ดูเจ๋งดีนะ 😆


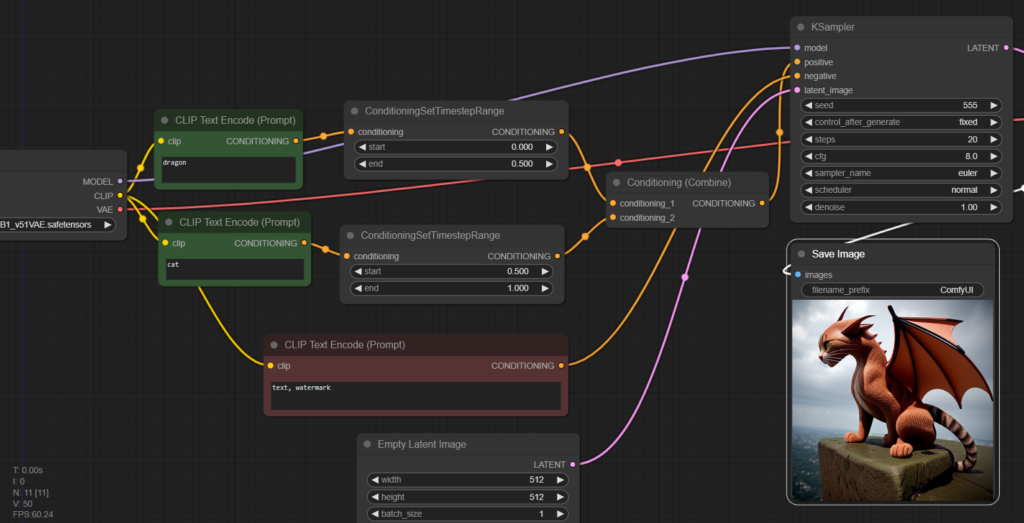
หรือจะ Advanced ขึ้นไปอีก คือ มีการใช้ Conditioning Set Time Step Range ต่อจาก Clip Text Encode ก่อนจะส่งเข้า Conditioning Combine เพื่อกำหนดว่าจะให้ Condition นั้นๆ ส่งผลตอนช่วงการ Gen กี่% เช่น ในรูปผมสั่งทำมังกรก่อน 50% แรก แล้วค่อย Gen แมวต่ออีก 50%

กำหนดขนาดรูป ที่ Empty Latent Image
ก่อนที่ KSampler จะทำการลด Noise จากรูปไปเรื่อยๆ จริงๆ แล้วจะต้องมีการกำหนดขนาดของ Latent ว่างเปล่าก่อน โดยผลลัพธ์ของ Node นี้ก็จะส่ง Latent ว่างเปล่าไปให้ KSampler ทำงานต่อ
ซึ่งเราจะกำหนดขนาดรูปเป็นหน่วย Pixel ตามปกตินี่แหละ เดี๋ยวโปรแกรมมันจัดการเอง
Tips : ควรกำหนดให้แต่ละด้านหารด้วย 8 ลงตัวนะ เพราะเวลามันแปลงจาก Pixel เป็น Latent ขนาดแต่ละด้านมันลดลง 8 เท่า
ผมระบุแนวตั้ง ถ้าอยากได้แนวนอนก็ไปสลับเลขเองนะ
ถ้าเป็น Model SD1.5 ขนาดที่นิยม คือ
- 512 x 512
- 512 x 768 (นิยมสุด ***)
- 576 x 768
- 768 x 768 (บางโมเดล Train มาที่ขนาดนี้)
ถ้าเป็น Model SDXL จะเทรนมาที่ขนาดใหญ่กว่านี้ คือ
- 1024 x 1024
- 768 x 1152
- 864 x 1152
- 768 x 1360
ในเคสนี้เรายังใช้ Model 1.5 อยู่ งั้นผมขอแก้เป็นขนาด 512 x 768 นะ แล้วลอง Gen ใหม่ โดยใช้ Prompt เดิมคือ
Positive:
photo of black cat and yellow flower in blue sky
negative:
text, watermark, leaf, cloudภาพเหมือนมีที่ให้น้องแมวหายใจเยอะขึ้นหน่อย

การตั้งค่าและกระบวนการทำงานใน KSampler
ได้เวลามาลงรายละเอียดใน KSampler กันซักที
สมมติว่าผมใช้ Prompt นี้ละกันจะเห็นภาพชัดกว่า (ลากรูปนี้ไปเลยก็ได้)
Positive:
realistic photo of beautiful thai girl idol wearing t-shirt and jeans shorts on a boat in thai water market
negative:
text, watermark, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime
เราจะพบว่า แม้จะพยายามปรับ Prompt ให้มัน Realistic แล้ว แต่ภาพก็ยังไม่ค่อยสมจริงเท่าไหร่ เช่น ผิวก็ยังดูเนียนๆ เป็น 3d cg ยังไงไม่รู้…
ทั้งนี้เป็นเพราะมันยังขึ้นอยู่กับเรื่องอื่นๆ ด้วย ที่เรายังไม่ได้พูดถึงใน KSampler ซึ่งมีดังนี้
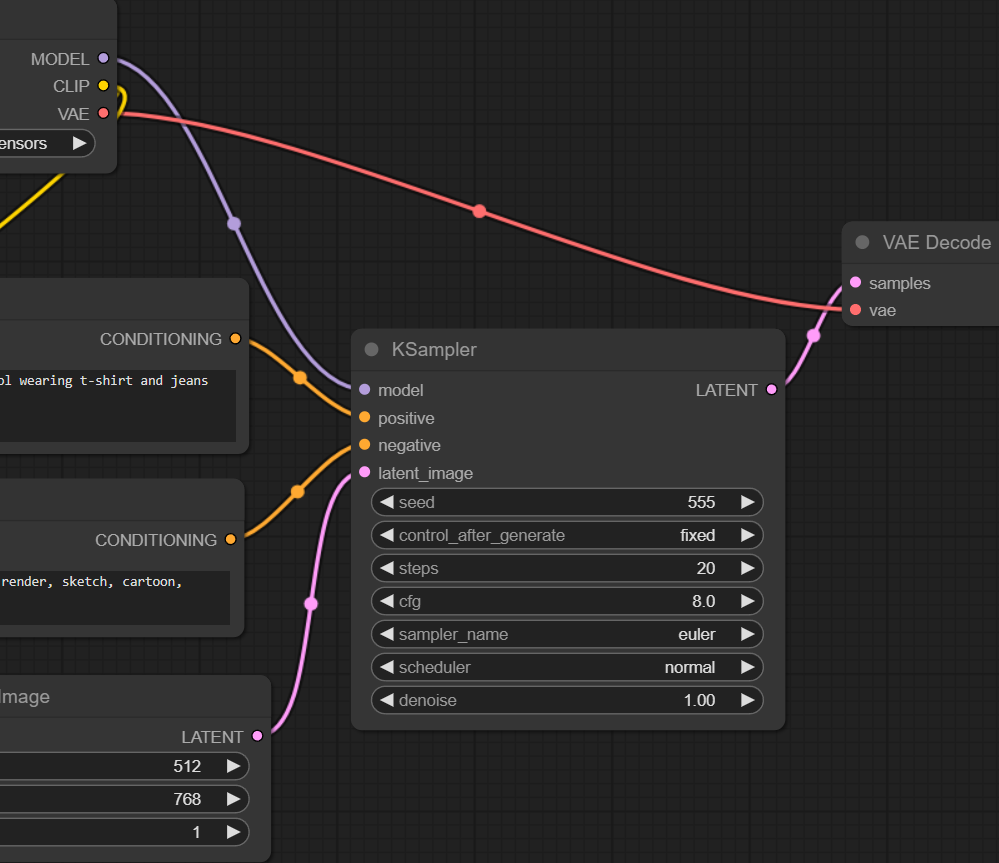
- Seed : กำหนดการ Random Noise ตั้งต้น ถ้าใช้ Seed เดิม ขนาด Latent เท่าเดิม ก็จะได้ Noise หน้าตาเหมือนเดิม
- Control After Generate : หลังจาก Gen รูปแล้ว จะให้เปลี่ยน Seed หรือไม่อย่างไร
- Steps: จำนวนขั้นตอนที่จะใช้ในการลด Noise ให้หมด
- ถ้ายิ่ง Step เยอะภาพจะแม่นยำขึ้น (แต่พอเยอะถึงจุดนึงจะเริ่มรู้สึกไม่มีอะไรเปลี่ยนแปลง ดังนั้นควรหาค่าที่พอดีๆ)
- ถ้าเป็น Model ปกติ แนะนำประมาณ 20-40 ครับ
- ถ้าเป็น SDXL Turbo, Lightning ใช้แค่ 4-8 ก็สวยมากแล้ว
- CFG: ย่อมาจาก Classifier Free Guidance
- ยิ่งเลขมาก จะทำให้ Sampler พยายามทำตาม Prompt ที่เราสั่งมากขึ้น (ถ้าเยอะไปรูปอาจพัง)
- ถ้าเลขน้อย การ Gen ภาพจะยึดตาม Model เป็นหลัก ไม่ค่อยสน Prompt
- ถ้าเป็น Model ปกติ แนะนำประมาณ 7-8 ครับ
- ถ้าเป็น SDXL Turbo, Lightning แนะนำ 1-2 ครับ (ใส่ทศนิยมได้)
- Sampler Name: เอาไว้ตั้งค่ารูปแบบการ Sampling Noise ผมขอแนะนำ
- DPMPP 2M (ภาพโดยรวมไม่ค่อยเปลี่ยนเมื่อเพิ่ม step)
- dpmpp_2m_sde (ภาพโดยรวมเปลี่ยนเมื่อเพิ่ม step)
- Scheduler: เอาไว้กำหนดรูปแบบว่า Noise จะลดเยอะแค่ไหนในแต่ละ Step
- แนะนำเป็น Karras มักจะได้ภาพสวยสุด
- Denoise: ความแรงในการเปลี่ยนจาก Noise เดิม
- ถ้าเป็นการสร้างรูปจาก Empty Latent ควรต้องใส่เป็น 1.0 (หรือ 100%)
- ถ้ามีรูปถูกสร้างไว้อยู่แล้ว แล้วจะทำเพิ่ม ควรใส่น้อยลง เช่น 0.4 (40%)
ส่วนใครอยากอ่านละเอียดก็อ่านต่อได้ ใครขี้เกียจอ่านก็ไป Node ถัดไปได้เลย 555
เรื่อง Advanced ของ K-Sampler
Steps
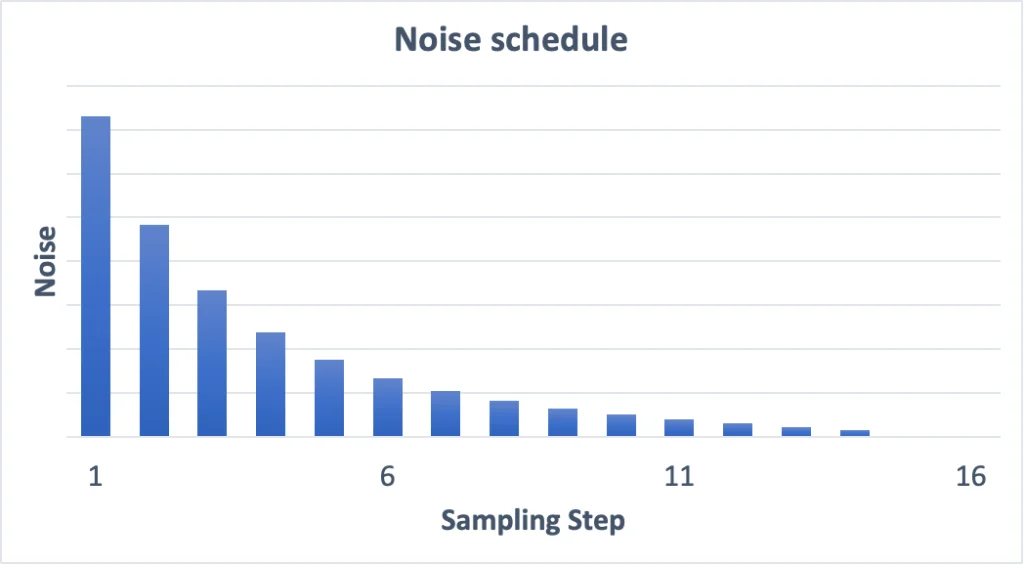
สำหรับเรื่อง Steps นั้น สมมติว่าเราสั่งให้ทำงานปลด Noise 15 Step กับ 30 Steps มันไม่ได้แปลว่า 15 Steps ทำแค่ครึ่งนึง ของ 30 Steps แล้วหยุดนะ
แต่มันเป็นการบอกว่าให้ปลด Noise ให้หมดภายใน 15 Steps ต่างหาก ซึ่งแปลว่าแต่ละ Step ระดับ Noise จะลดลงไปมาก ถ้าเทียบกับการบอกให้ปลด Noise ให้หมดภายใน 30 Steps
ดูภาพนี้ประกอบ จะเห็นว่าภาพ Step เยอะ มันจะค่อยเป็นค่อยไปกว่า ภาพที่ได้มีโอกาสจะออกมาดีกว่า ไม่ค่อยมีส่วนที่เพี้ยนๆ

Seeds
ลองมาดูว่า การที่เราใช้ Latent Image ขนาดเท่าเดิม และ Seed เป็นเลขเดิม ทำให้ Noise เหมือนเดิมมันแปลว่าอะไร?
เดี่ยวผมจะลอง Load Default Workflow แล้วกำหนด Fixed seed แต่เปลี่ยนแค่ Positive Prompt ให้ดู โดยผมกำหนดให้ปลด Noise ให้หมดภายใน 2 Steps (Model ทำไม่ไหว Step น้อยไปเลยทำได้แค่นี้)
เราจะเห็นว่าโครงสร้างของกลุ่ม Noise มันหน้าตาคล้ายๆ กันมาก
อันนี้ seed 555



อันนี้ seed 7777777



นี่แหละครับ ที่บอกว่า seed คือตัวกำหนด noise มันคือแบบนี้
Sampler
เดี๋ยวเรามาทำความเข้าใจเรื่อง Sampler โดยลองเพิ่ม Steps กับภาพผู้หญิงที่ตลาดน้ำดูเป็นซัก 30 กับ 50 ว่าผลเป็นยังไง?
เหมือนว่าภาพมีความชัดเจนขึ้น โดยเฉพาะฉากหลังมีรายละเอียดมากขึ้น รูปที่ได้มีการเปลี่ยนไปเล็กน้อย โดย Sampler ยังเป็น Euler อยู่


เดี๋ยวเราลองเปลี่ยน Sampler เป็น DDPM ดู จะเห็นว่า เมื่อ Steps มากขึ้น ภาพที่ได้ค่อนข้างเปลี่ยนไปจากเดิมมากเลย เมื่อเทียบกับ Sampler เดิมคือ Euler



ที่เกิดแบบนี้เพราะว่า Sampler นั้น ทำหน้าที่สุ่ม (sample) เวกเตอร์ noise ใน latent space เพื่อใช้เป็นจุดเริ่มต้นในการสร้างภาพ ซึ่งจริงๆ มีวิธีการทำงานหลายแบบ แต่ผมขอแบ่งเป็น 2 กลุ่มใหญ่ๆ คือ
- แบบที่คาดเดาได้ : เมื่อ Steps เยอะขึ้น องค์ประกอบภาพจะไม่เปลี่ยนจากเดิมมาก (ผลลัพธ์ converge เป็นค่าเดียว)
- Euler : เป็นตัว Classic ทำงานเร็ว แต่ภาพอาจไม่ค่อยดี
- DPMPP 2M : ตัวนี้เป็นตัวยอดฮิตที่ทำภาพสวยมาก
- DDIM
- UNI PC
- ตัวอื่นๆ ไม่ค่อยได้ใช้
- แบบที่คาดเดาไม่ได้ : เมื่อ Steps เยอะขึ้น องค์ประกอบภาพอาจเปลี่ยนไปจนคาดเดาไม่ได้ (ผลลัพธ์ไม่ converge เป็นค่าเดียว)
- ลงท้ายด้วย ancestral เช่น euler ancestral, dpm_2 ancestral
- ลงท้ายด้วย sde เช่น dpmpp_2m_sde ตัวนี้เป็นตัวยอดฮิตที่ทำภาพสวยมาก
- DDPM
- DPM Fast
- ตัวอื่นๆ ไม่ค่อยได้ใช้
เราลองใช้ DPMPP 2M (ผลลัพธ์คาดเดาได้) ดูจะได้แบบนี้



เราลองใช้ DPMPP 2M SDE (ผลลัพธ์คาดเดาไม่ได้ และ steps ต่ำๆ ยังเอา noise ออกไม่หมด)



Scheduler
ทีนี้ยังเหลืออีกเรื่องคือ Scheduler เพื่อกำหนดว่า จะลด Noise เร็วช้าแค่ไหน ซึ่งเดิมทีผมเลือกแบบ Normal คือค่อยๆ ลดเท่าๆ กันในทุก Steps
แต่ถ้าเราลองเลือกอันอื่น ความเร็วในการลด Noise จะเปลี่ยนไป เช่น แนะนำให้ลองใช้ Karras ดู ซึ่งเป็นตัวที่นิยมมากเหมือนกัน เพราะมักจะได้ภาพสวยขึ้น
Karras + DPMPP 2M (ผลลัพธ์คาดเดาได้)



Karras + DPMPP 2M SDE (ผลลัพธ์คาดเดาไม่ได้)



VAE Decode
หลังจากที่ KSampler สร้างรูปเสร็จ ผลลัพธ์ออกมาเป็น Latent Image ซึ่งมนุษย์มองไม่รู้เรื่อง มันจะต้องมีการแปลงรูปจาก Latent Space เป็น Pixel Space ในโลกจริงก่อน
ซึ่งตัวที่แปลงได้คือ VAE Decode ที่ต้องรับ Input คือ VAE จาก Load Checkpoint Model และ Latent จาก KSampler นั่นเอง

ผลลัพธ์จะได้ออกมาเป็นรูปปกติ ซึ่งมนุษย์มองรู้เรื่องแล้ว
Save Image
ถ้าเราส่ง Image ปกติเข้าไปใน node Save Image รูปนั้นก็จะถูกบันทึกไว้ให้ที่ Folder Output ให้เลย
เรื่อง Advanced เกี่ยวกับการ Save รูป
ถ้าเรายังไม่อยากบันทึกรูปทันที
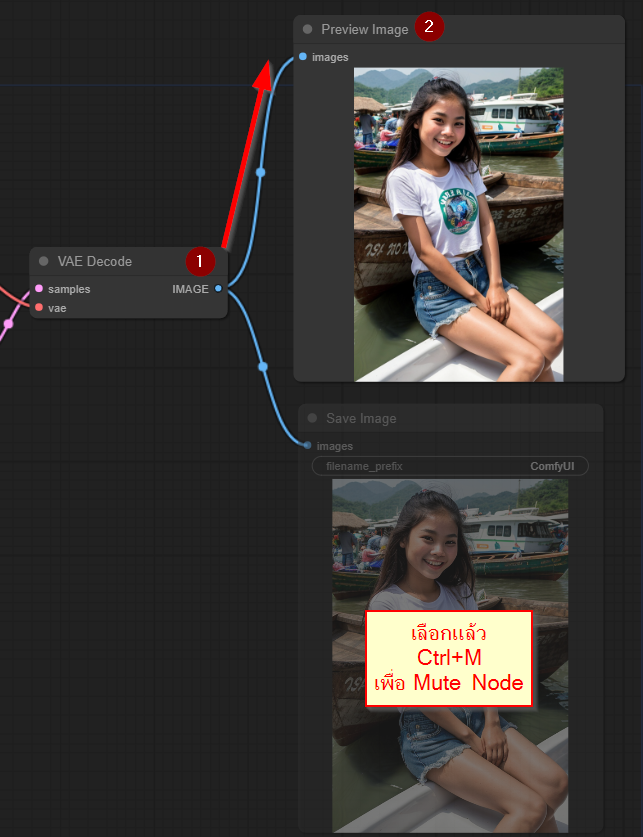
เราสามารถใช้ Node Preview Image แทนได้นะ วิธีการคือลากจากตุ่ม Image ของ VAE Decode ออกมา จะห็นว่ามี Choice ให้เลือกได้ว่าจะต่อด้วย Node อะไร ซึ่งเราเลือก Preview Image ได้
จากนั้นให้ไปเลือก Node Save Image แล้วกด Ctrl+M เพื่อ Mute ไม่ให้ Node นั้นทำงาน
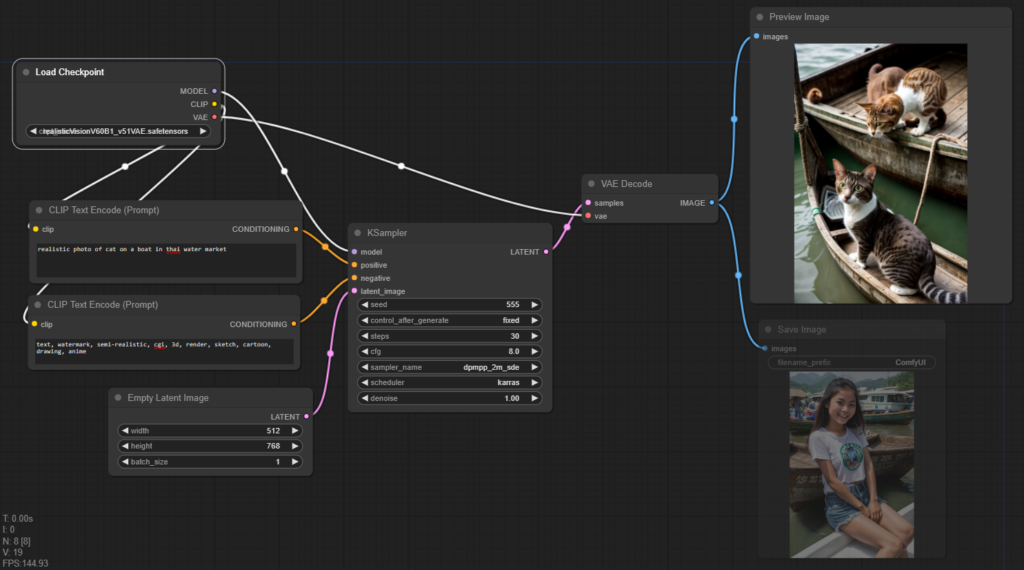
เช่น ผมลองเปลี่ยน Prompt เป็น
realistic photo of cat on a boat in thai water market
แล้ว Queue Prompt จะได้แบบนี้ ซึ่งรูปแมวจะไม่ถูกบันทึก
แต่ถ้าเราพอใจแล้วอยาก Save ค่อย Unmute ตัว Save Image ด้วยการกด Ctrl+M แล้ว Queue Prompt อีกรอบ (มันเร็วปรื๊ด เพราะไม่ได้ Gen ใหม่แล้วนะ)

ถ้าอยากจะใส่ข้อมูลเพิ่มเติมเข้าไปในชื่อไฟล์ที่ Save
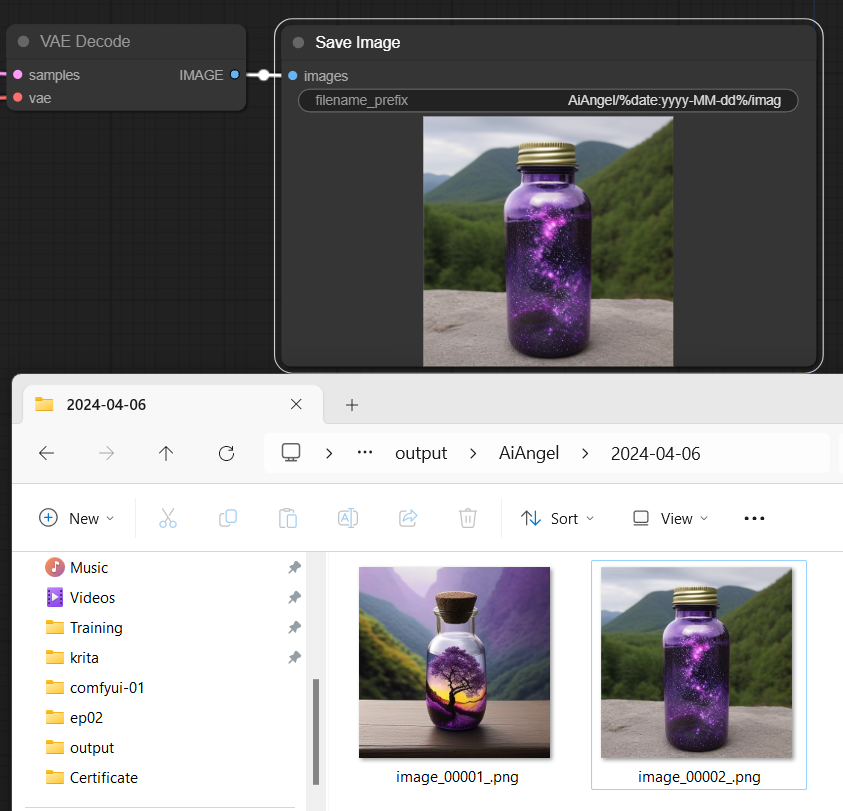
เราสามารถกำหนด Sub Folder แล้ว กำหนดวันที่เป็น Folder ด้วย แบบนี้ก็ได้นะ เช่น
AiAngel/%date:yyyy-MM-dd%/imageผลที่ได้จะออกมาใน Folder ที่กำหนดเลย
หรือถ้าอยากได้ค่า Parameter บางอย่าง บันทึกไปด้วย ก็ใส่คำพวกนี้ไปได้ (จะเอาไว้เป็นชื่อ Folder หรือ ชื่อไฟล์ก็ได้นะ) เช่น
- %KSampler.seed% = ค่า seed
- %Empty Latent Image.width% = ความกว้างรูป
- %Empty Latent Image.height% = ความสูงรูป
- %date:yyyy-MM-dd% = วันที่ ปี เดือน วัน
- %date:hhmmss% = เวลา ชม นาที วินาที
เช่น ผมแก้เป็นแบบนี้ จะได้มีความกว้าง ความสูง และ seed ติดมาที่ชื่อไฟล์ด้วย (ถ้าข้อมูลด้านหน้าชื่อไฟล์ไม่เหมือนกัน มันก็จะรันเลขของใครของมันนะ)
AiAngel/%date:yyyy-MM-dd%/image_%Empty Latent Image.width%x%Empty Latent Image.height%_%KSampler.seed%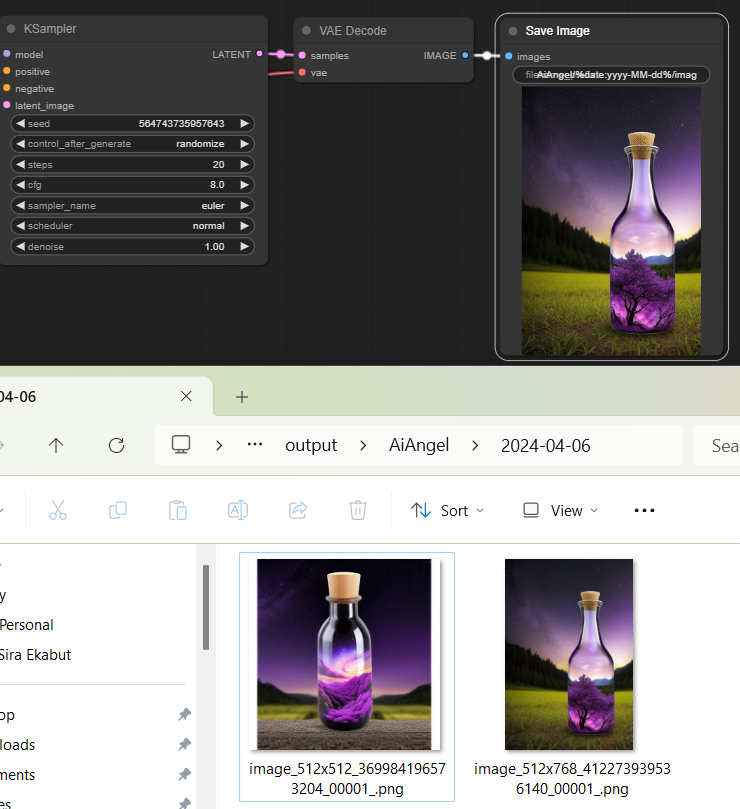
คลิปสอน
อันนี้เป็นคลิปภาษาอังกฤษที่เคยทำไว้นานแล้ว แต่น่าจะช่วยให้เห็นภาพชัดขึ้นในบางเรื่องครับ
สรุป
จากที่เราได้ทำความเข้าใจเกี่ยวกับกระบวนการสร้างภาพด้วย Stable Diffusion ผ่าน Node ต่างๆ ใน ComfyUI จะเห็นได้ว่าปัจจัยสำคัญที่ส่งผลต่อคุณภาพและลักษณะของภาพสุดท้ายที่ได้ ไม่ได้มีเพียงแค่ Prompt เท่านั้น แต่ยังรวมถึงปัจจัยอื่นๆ ทั้งหมดเริ่มตั้งแต่ขนาดของภาพ การกำหนดค่าใน KSampler ตั้งแต่เรื่องของ Seed ไปจนถึง Steps, CFG, และ Sampling และ Scheduler ด้วย
ดังนั้นการทำความเข้าใจถึงบทบาทและผลกระทบของ Sampler, Scheduler และ Step Count รวมถึงการเลือกใช้ และปรับแต่งค่าต่างๆ เหล่านี้อย่างเหมาะสม จะทำให้เราสามารถควบคุมกระบวนการสร้างภาพให้ได้ผลลัพธ์ที่มีคุณภาพ และตรงตามความต้องการได้ดียิ่งขึ้น ซึ่งจะนำไปสู่การสร้างสรรค์ผลงานที่น่าทึ่งด้วย Stable Diffusion ต่อไป
ตอนต่อไป
ในตอนต่อไป เราจะมาดูวิธีการติดตั้ง ComfyUI Manager และการติดตั้ง Custom Nodes เพื่อเพิ่มความสามารถให้ ComfyUI กันครับ