


ControlNet คืออะไร? ทำไมต้องใช้?
ในยุคที่ AI Art กำลังมาแรง หลายคนอาจเคยลองใช้ Midjourney, DALL-E หรือ Stable Diffusion ในการสร้างภาพอันน่าทึ่งจาก Prompt กันบ้างแล้ว แต่ปัญหาคือเรามักควบคุมผลลัพธ์ได้ไม่ค่อยตรงใจ ทำให้ภาพที่ได้อาจไม่เป็นดั่งหวัง
แต่สำหรับ Stable Diffusion นั้นต่างออกไป เพราะมีความสามารถพิเศษที่เรียกว่า “ControlNet” ซึ่งช่วยควบคุมภาพให้แม่นยำขึ้นมาก จนสร้างภาพได้ตรงใจขึันหลายเท่า!
ControlNet เป็นโมเดลเสริมของ Stable Diffusion ที่ให้ผู้ใช้ป้อนภาพตัวอย่างหรือเงื่อนไขบางอย่าง เพื่อควบคุมท่าทางตัวละคร เส้นขอบ ระยะตื้นลึกภาพได้อย่างละเอียด
ความโดดเด่นของ ControlNet คือการปรับแต่งรายละเอียดในภาพได้อิสระตามต้องการ ไม่ยึดติดแค่ Prompt ตัวหนังสืออย่างเดียว แต่ยังรับข้อมูลเพิ่มเติมจากภาพมาช่วยควบคุมด้วย
ด้วยคุณภาพและความคิดสร้างสรรค์เหนือชั้นแบบนี้ ControlNet จึงเป็นจุดแข็งสำคัญที่ทำให้ Stable Diffusion โดดเด่นกว่า AI อื่นๆ ใครอยากวาดภาพในฝันให้เป็นจริงตามใจปรารถนา
ในบทความนี้เราจะพูดถึง ControlNet ยอดนิยมแค่ 4 ตัวเท่านั้น แต่ถ้าใครอยากรู้ว่า ControlNet ทั้งหมดมีอะไรบ้าง ลองไปอ่านบทความเก่าของผมได้ที่นี่
เตรียมความพร้อม
ก่อนลงมือ เราต้องติดตั้ง Custom Node และโหลด Model ต่างๆ ดังนี้
- Custom Node: ติดตั้ง ComfyUI’s ControlNet Auxiliary Preprocessors จาก https://github.com/Fannovel16/comfyui_controlnet_aux
- โหลด Model ControlNet ต่อไปนี้:
SD1.5 Controlnet model ยอดนิยม:- Openpose : control_v11p_sd15_openpose_fp16.safetensors
- Depth : control_v11f1p_sd15_depth_fp16.safetensors
- Line Art : control_v11p_sd15_lineart_fp16.safetensors
- Scribble : control_v11p_sd15_scribble_fp16.safetensors
- Model อื่นๆ ถ้าอยากโหลดเล่น : Model ControlNet ทั้งหมด
นำ Model ที่ดาวน์โหลดมาทั้งหมดไปไว้ในโฟลเดอร์
…\ComfyUI_windows_portable\ComfyUI\models\controlnet
หัดต่อ Node ControlNet เบื้องต้นด้วย OpenPose
ControlNet OpenPose คือ Model ของ ControlNet ที่ใช้ควบคุมท่าทางของมนุษย์ในภาพที่สร้างจาก Stable Diffusion ให้เป็นไปตามโครงร่างท่าทางที่เรากำหนด
โดย OpenPose เป็นเทคนิคหนึ่งในการตรวจจับท่าทางของมนุษย์ (Human Pose Estimation) จากภาพหรือวิดีโอ ซึ่งจะแสดงผลเป็นโครงกระดูกที่ประกอบไปด้วยจุดและเส้นเชื่อมต่อบนตำแหน่งข้อต่อสำคัญต่างๆ ของร่างกาย เรียกว่า Keypoint ซึ่งผมชอบเรียกว่า มนุษย์ก้าง
เราสามารถสร้าง OpenPose ได้หลายวิธี เช่น กำหนดท่าทางผ่านการสร้าง 3D Model ก่อนโดยใช้โปรแกรม Blender (ซับซ้อน) หรือใช้เว็บ https://app.posemy.art/ (ง่าย) แล้วนำมาใช้ควบคุมท่าทางใน ComfyUI ได้
![เจาะลึก ControlNet ใน Stable Diffusion [Part8] 3](https://www.thepexcel.com/wp-content/uploads/2023/06/PoseMyArt4-1024x657.png)
![เจาะลึก ControlNet ใน Stable Diffusion [Part8] 9](https://www.thepexcel.com/wp-content/uploads/2023/06/PoseMyArt5-openposehand-200x300.png)
ข้อมูลโครงกระดูกจาก OpenPose นี้สามารถนำมาเป็นภาพต้นแบบ หรือ Condition ให้กับ ControlNet เพื่อควบคุมการวางท่าทางของคนในภาพใหม่ที่เราจะสร้างขึ้นมาจาก Stable Diffusion ได้
แต่วิธีที่ง่ายที่สุดคือ เอารูปปกติมา Convert เป็น OpenPose ซึ่งเราก็สามารถทำใน ComfyUI ได้เลย
สมมติเรามีรูปต้นฉบับคืออันนี้

ขั้นตอนการต่อ Node เพื่อใช้ ControlNet มีดังนี้
- ลาก Node “Apply ControlNet (Advanced)” มาวางในพื้นที่ทำงาน
- เชื่อมต่อ Node “Load ControlNet Model” เข้ากับ Apply ControlNet แล้วเลือก Model ที่ต้องการใช้เป็นตัวควบคุม ในตัวอย่างแรก จะใช้ Openpose หรือตัวควบคุมท่าทางมนุษย์นั่นเอง
- นำรูปภาพต้นฉบับที่ต้องการควบคุมท่าทางเชื่อมเข้ากับ Image ใน Apply ControlNet (รูปภาพต้องเป็นโครงร่างท่าทางมนุษย์ก้างปลาเท่านั้น)
- หากเป็นรูปธรรมดา ให้เชื่อมผ่าน Node “Openpose Pose” เพื่อแปลงเป็นโครงร่างมนุษย์ก้างก่อน (เราเลือกได้ว่าเราจะให้คุมอะไรบ้าง เช่น เอา ท่าทาง, มือ, โครงหน้า)
- เชื่อมต่อ Positive/Negative Prompt เข้ากับ Apply ControlNet ก่อนจะส่ง Output เข้า KSampler (Prompt กับ ControlNet อะไรจะอยู่ก่อนก็ได้)
- ส่ง Output จาก Apply ControlNet ไปยัง KSampler เพื่อสั่ง Generate ภาพ
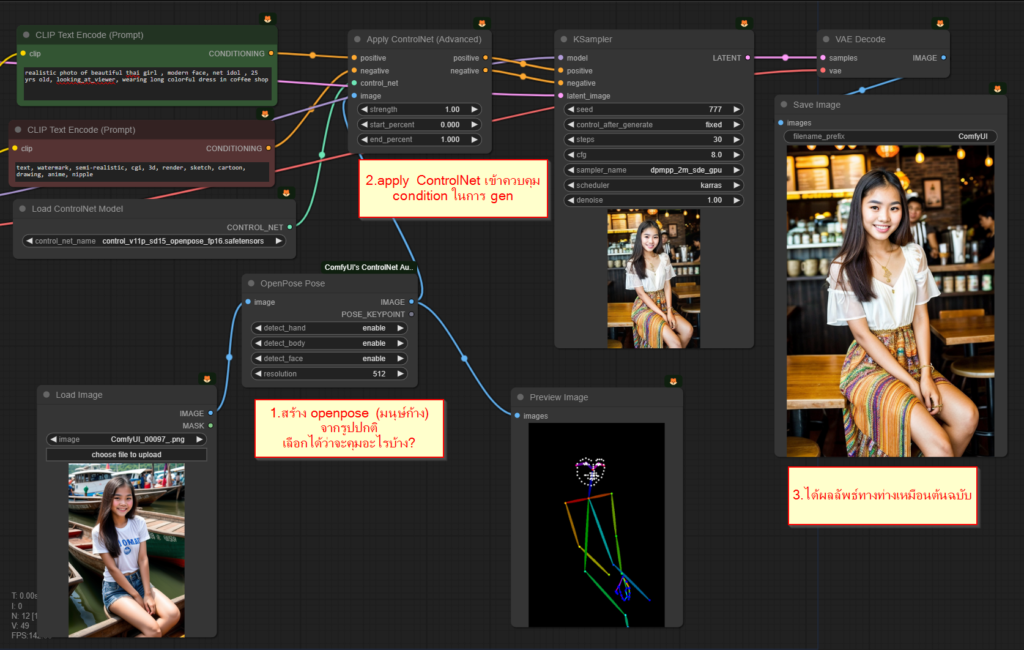
ผลลัพธ์ที่ได้จะมีท่าทางตรงตามรูปภาพต้นฉบับที่เราเลือกมา เช่นในตัวอย่างนี้ที่ใช้รูปหญิงสาวยิ้ม ภาพที่สร้างออกมาจึงมีท่าทางและรอยยิ้มเหมือนต้นแบบเป๊ะ

ลองควบคุมด้วย Depth
หากเรามีภาพฉากหลังที่มีระยะความลึกถูกใจแล้ว เราสามารถนำมาเป็นตัวควบคุมการสร้างภาพอื่นๆ ที่มีความลึกในลักษณะเดียวกันได้ ด้วย Node “Midas Depth”
สมมติว่าผม Gen ฉากหลังที่มีโครงสร้างความลึกที่โดนใจได้แล้ว เช่น อันนี้

ผมลองเอามา Gen เพื่อให้ได้ฉากอื่นๆ ที่มีลักษณะความลึกเหมือนกัน ซึ่งจะใช้ Midas Depth ช่วยในการควบคุม
เชื่อมต่อรูปภาพฉากหลังเข้ากับ Image ใน Apply ControlNet (Advanced) แล้วเลือก Model เป็น Depth จากนั้นสั่ง Generate ภาพใหม่ ผลลัพธ์ที่ได้จะมีระยะความลึกของวัตถุเหมือนภาพต้นฉบับที่ใช้ควบคุม
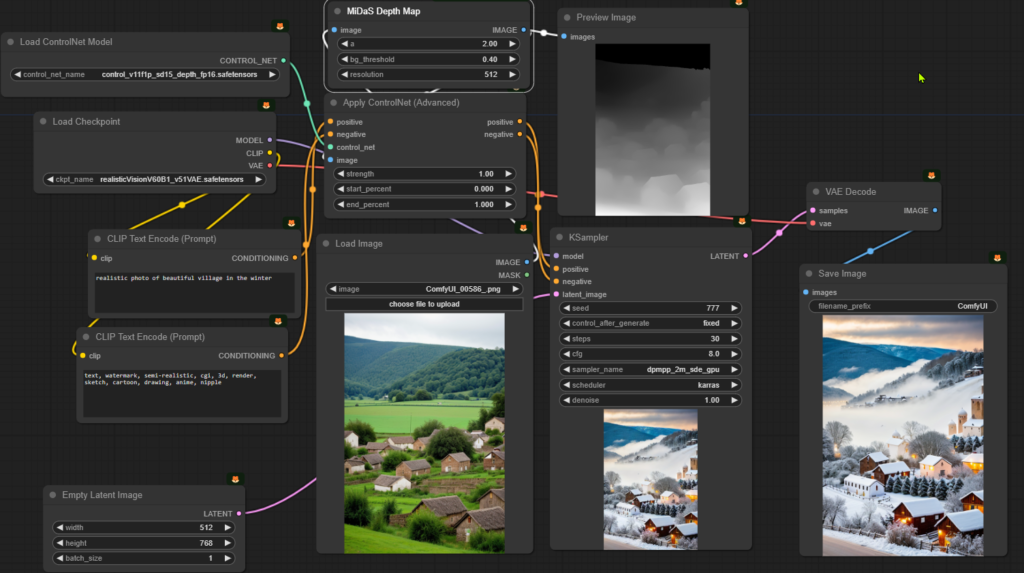
จะได้ผลลัพธ์แบบนี้ ซึ่งมี “ความลึก” เหมือนรูปต้นฉบับ แต่รายละเอียดอื่นเปลี่ยนตาม Prompt ได้ เช่น
realistic photo of beautiful village in the winter
ลองควบคุมด้วย Line Art
ControlNet Line Art เป็นอีกหนึ่ง Model ของ ControlNet ที่ใช้ควบคุมโครงร่างหรือลายเส้นของวัตถุในภาพที่สร้างจาก Stable Diffusion ให้เป็นไปตามเส้นร่างที่เรากำหนด
เมื่อเรานำภาพ Line Art ไปใช้เป็น Condition ให้กับ ControlNet แล้ว มันจะช่วยควบคุมให้ Stable Diffusion สร้างภาพที่มีโครงร่างตรงตามลายเส้นนั้นๆ ได้
เหมาะกับในกรณีที่เรามีภาพลายเส้นที่วาดสวยเป๊ะแล้ว เราสามารถนำมาเป็นโครงร่างให้ ControlNet ช่วยสร้างภาพจากลายเส้นนั้นได้เลย
วิธีการนำ Line Art มาใช้ใน ComfyUI ก็ทำได้ง่ายๆ ดังนี้
- เตรียมภาพ Line Art ของเรา อาจวาดเองหรือหามาจากที่อื่นก็ได้
- นำภาพเข้า Node “Invert Image” เพื่อกลับสีขาวดำก่อน (ControlNet จะอ่านเส้นสีขาวบนพื้นดำ)
- ส่งภาพจาก Invert Image ไปเข้า Apply ControlNet แล้วเลือก Model เป็น “Line Art”
- เชื่อมต่อ Prompt (Positive/Negative) และ LatentImage เข้ากับ Apply ControlNet
- ส่ง LatentImage จาก Apply ControlNet ไปเข้า Node อื่นๆ จนถึง KSampler
- สั่ง Generate ภาพได้เลย
สมมติผมมีภาพที่มีภาพลายเส้นแบบนี้

จากนั้นต่อ Node เพื่อใช้ LineArt เข้าควบคุม (อย่าลืม Invert Image กลับขาวดำ) โดยสั่ง Prompt ตามต้องการ เช่น ผมกำหนดให้เป็นสี Pastel
realistic photo of beautiful bedroom, pastel color 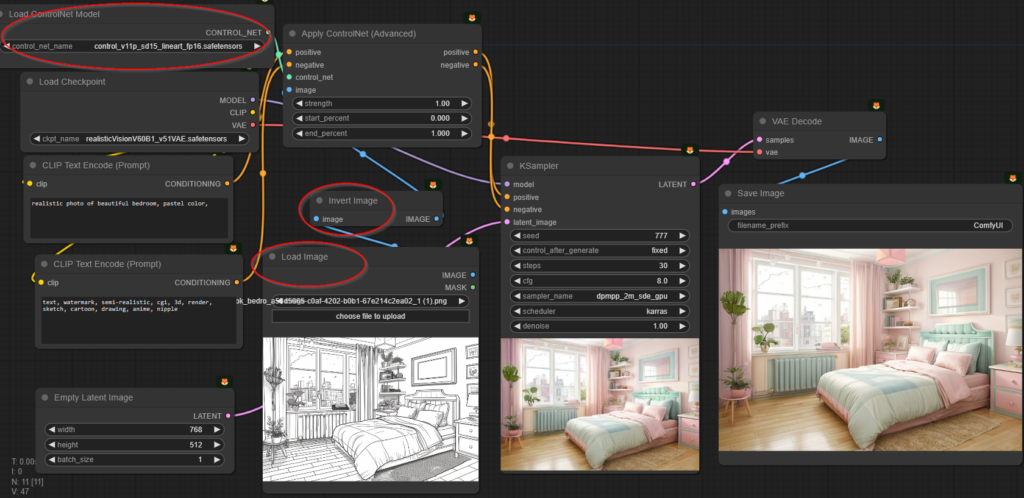

ลองควบคุมด้วย Scribble
นอกจากภาพลายเส้นละเอียดแล้ว เรายังสามารถใช้ภาพเส้นที่วาดอย่างหยาบๆ มาเป็นโครงร่างคร่าวๆ ให้ ControlNet สร้างภาพตามได้ด้วย
สมมติผมมีภาพที่มีภาพลายเส้นที่วาดหยุกหยุยแบบนี้ (ซึ่งตัวอย่างนี้ผมวาดเยอะไปหน่อย จะคุมยากนิดหน่อย)
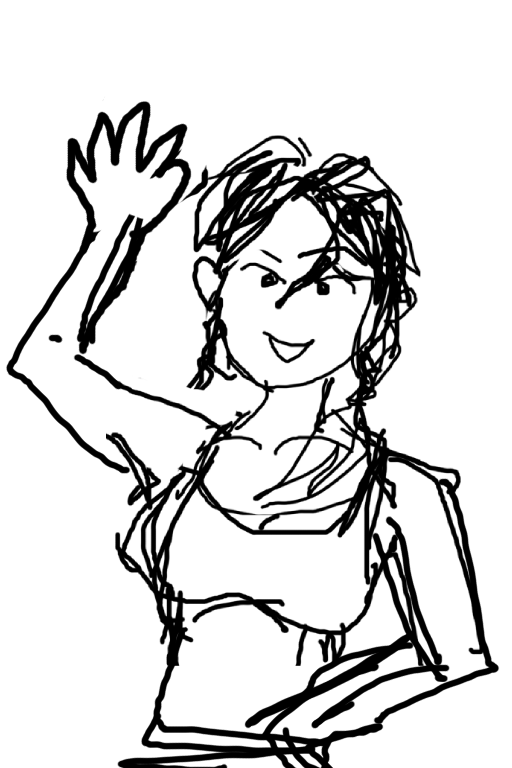
แล้วเราก็สั่งให้ตัวนี้เข้าไปควบคุมรูป ด้วย Scribble (ซึ่งต้อง invert ภาพเช่นกัน) แต่เคล็ดลับคือต้องลด weight ลงพอสมควรเลย เช่น ในที่นี้ผมใช้ 0.3 เอง และต้องใช้การทดลองผิดลองถูกพอสมควรครับ (ยิ่งถ้าวาดรายละเอียดเยอะ ยิ่งคุมด้วย Scribble ยาก)
ในเคสนี้ ถ้า Prompt น้อยมันอาจจะไม่เข้าใจ ในที่นี้ผมใช้ Prompt ระบุละเอียดหน่อย เพื่อให้ได้ตรงใจที่สุด
realistic close up photoshot of beautiful (mix european korean chinese thai ) woman 20 yrs old, looking at viewer, wet twin_braids, smile ,(hand waving bye bye:1.15), beautiful eyes, wearing (wet white tank top:1.2), wet, in summer songkran festival, (sexy medium breast:1.2)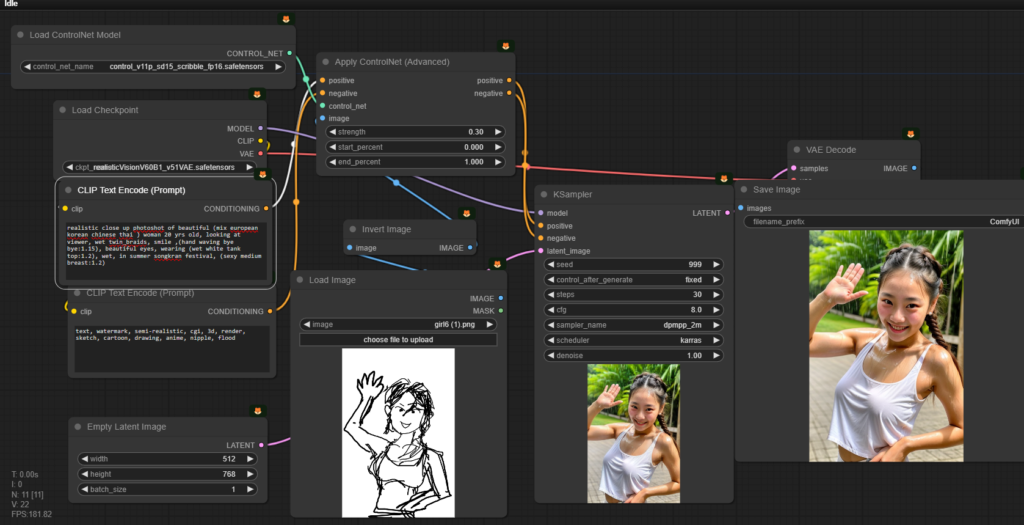

ลองควบคุมหลายอย่างพร้อมกัน
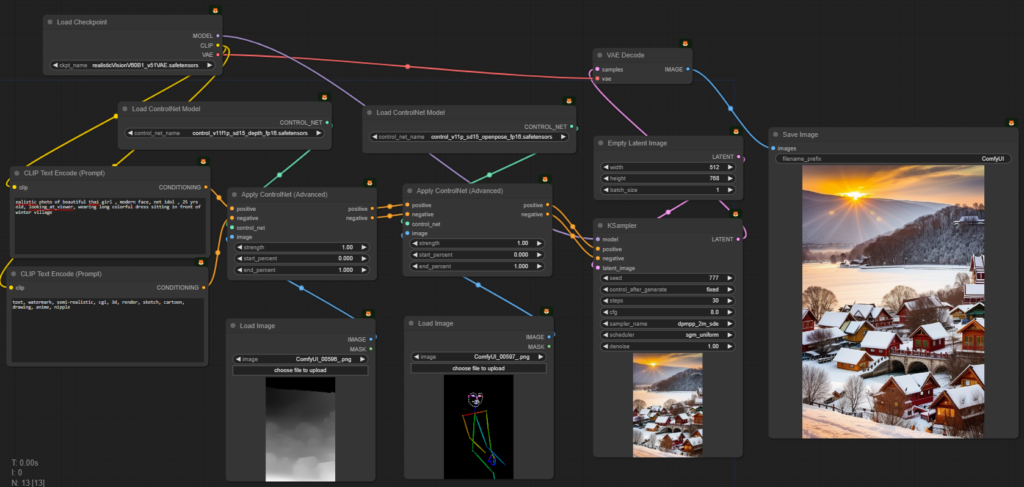
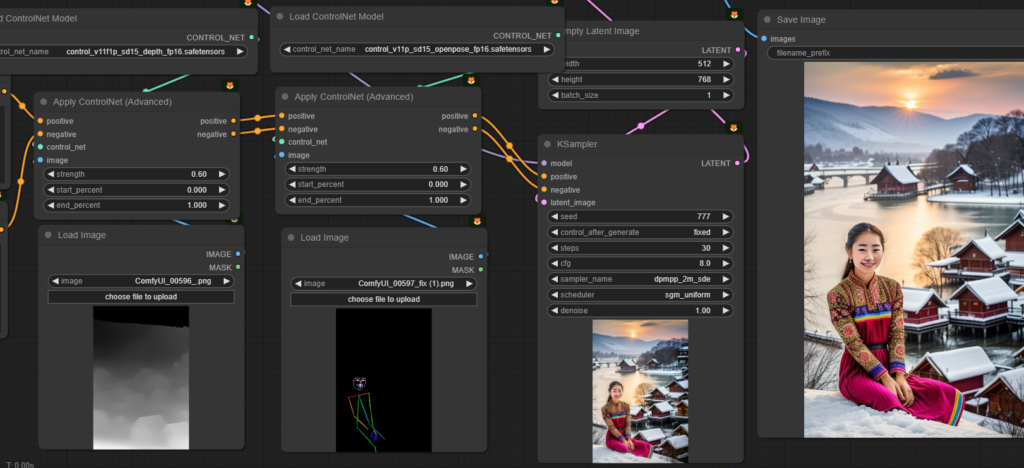
เราสามารถใช้ ControlNet หลายแบบมาควบคุมการสร้างภาพร่วมกันได้ เช่น ใช้ทั้ง Depth และ Openpose พร้อมกัน
เดี๋ยวเราจะลองเอาภาพ Depth กับ Openpose มาใช้คุมทั้งคู่เลย เช่น แบบนี้
ealistic photo of beautiful thai girl , modern face, net idol , 25 yrs old, looking_at_viewer, wearing long colorful dress sitting in front of winter villageโดยการเชื่อมภาพที่ใช้ควบคุมแต่ละแบบเข้ากับ Apply ControlNet คนละตัว แล้วส่ง Latent ต่อกันไปเรื่อยๆ ก่อนส่งเข้า KSampler
จะเห็นว่าภาพออกมาไม่เห็นมีคนเลย เพราะทั้งนี้การควบคุมมัน Conflict กันอยู่ และแต่ละอันก็มี Weight เยอะมากคือ 1.0 ทั้งคู่

คราวนี้ลองลด Weight ลง สมติเหลือ 0.6 ทั้งคู่ จะได้ภาพสุดประหลาดแบบนี้

ทางแก้ไขมีหลายวิธี
ผลัดกัน Control กันคนละช่วง
นอกจากนี้เราอาจแก้ไขความขัดแย้งของภาพที่ใช้ควบคุมได้ วิธีแรกคือ การปรับให้ ControlNet แต่ละตัวส่งผลในจังหวะเวลาที่ต่างกัน เช่น ให้ Depth ควบคุม 30% แรก ส่วน Openpose ควบคุม 70% ที่เหลือ ภาพมันก็อาจจะพยายามทำให้ Make sense ขึ้นได้ (Weight 60% ทั้งคู่)
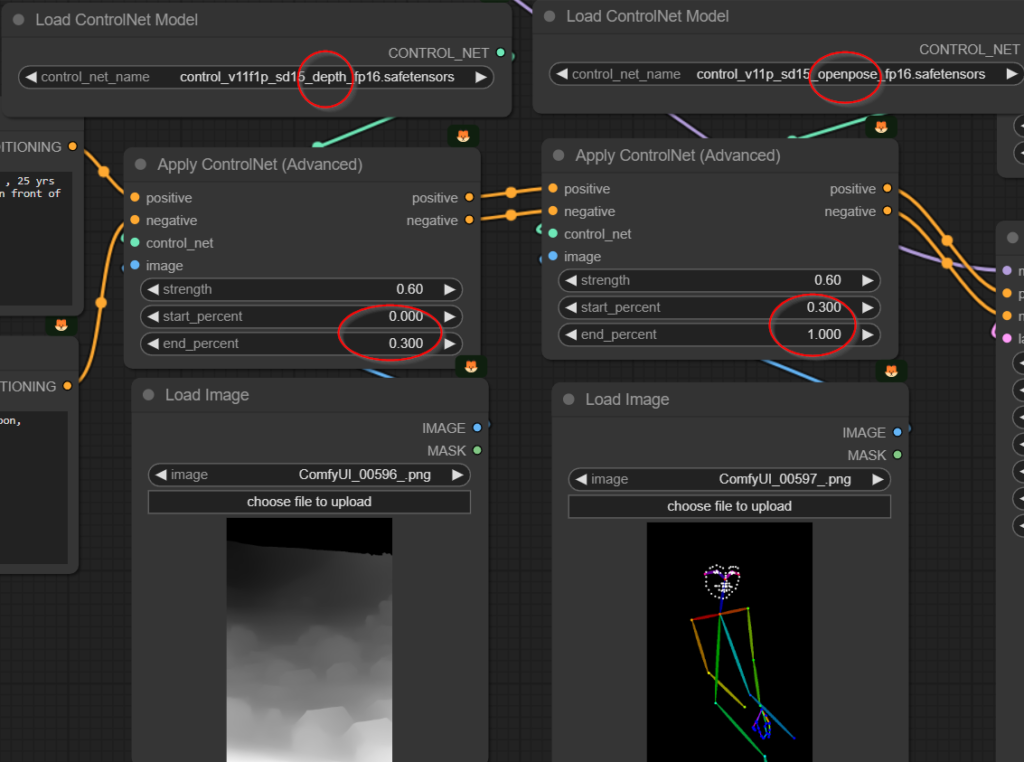

เอาตัว Control ไปปรับ Size ให้เหมาะสมก่อน
หรืออีกวิธีคือ แก้ไขรูปภาพที่จะใช้ Control ให้เข้ากันตั้งแต่ต้น ด้วยการเปิดใน Photo Editor เพื่อปรับขนาดส่วนต่างๆ ให้สอดคล้องกัน แล้วจึงนำมาใช้งาน
อีกวิธีคือเอาตัว Control ไปปรับ Size ให้เหมาะสม ซึ่งถ้าใครเก่งแล้ว เราทำส่วนนี้ใน ComfyUI ได้เลยนะ (ไว้ผมจะสอนใน EP ถัดๆ ไป)
แต่ในบทความนี้ เราจะเอาไปปรับข้างนอก คือทำใน Photo Editor ที่ทำเป็น Layer ได้ เช่น Photoshop, Kritra (ฟรี) หรือ Photopea (ฟรี) แล้วปรับขนาด Openpose ให้เหมาะกับ Depth ก่อนนำมาใช้
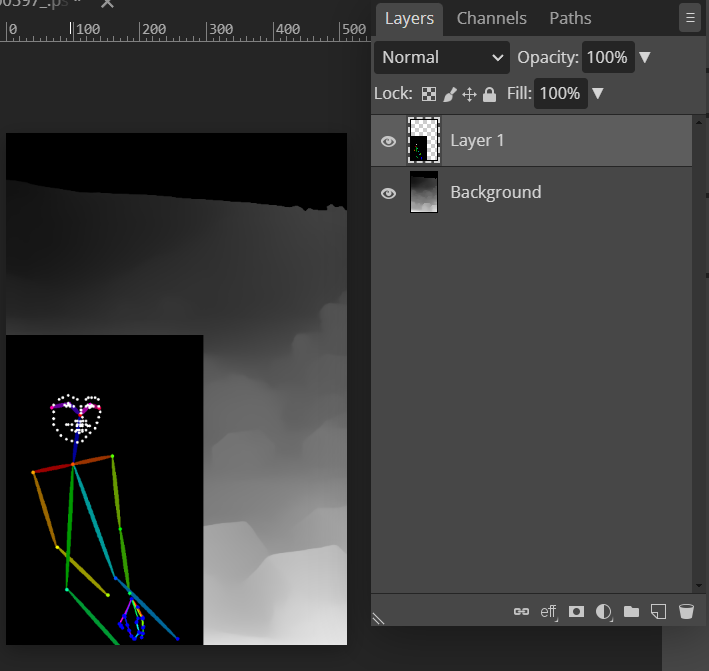
สุดท้าย save openpose ตัวแก้ไขกลับมาใหม่
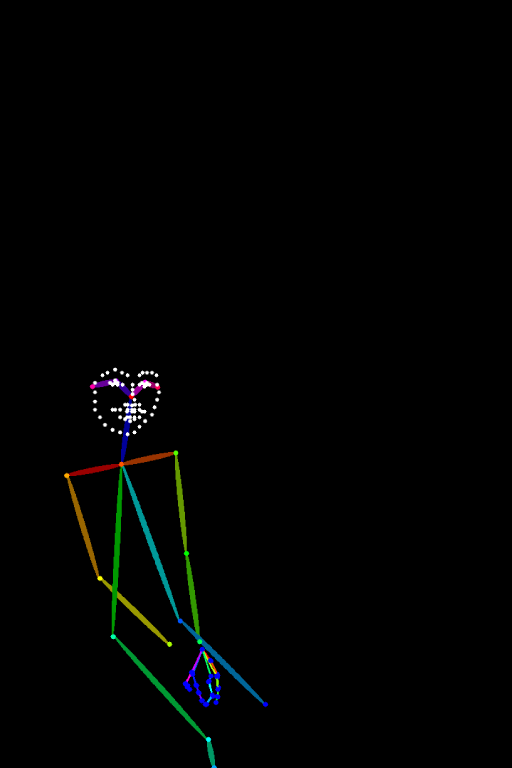
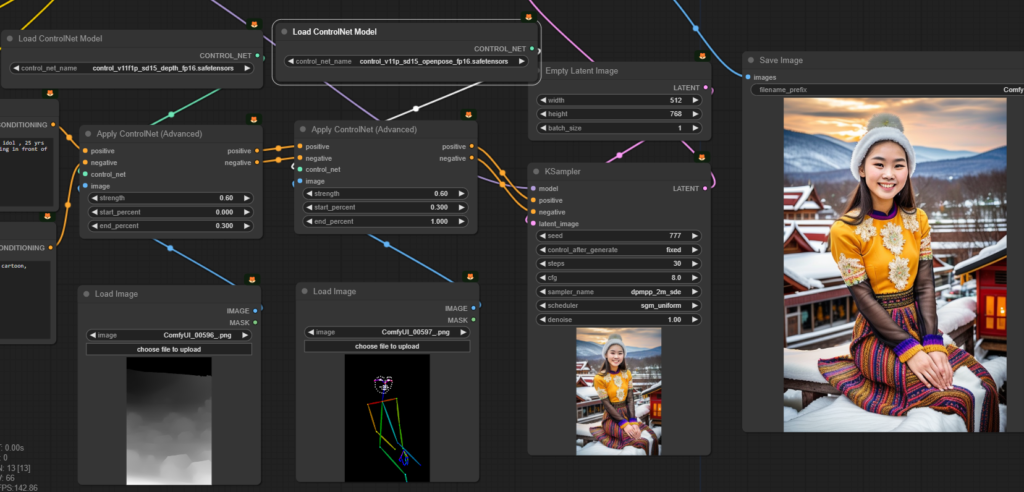
แล้วเอามา Gen ใหม่ ซึ่งคราวนี้ไม่ต้องไปแบ่งช่วงเวลา Gen แล้ว เพราะมันไม่ Conflict กัน

จากนี้ก็เล่นอะไรก็ได้ละ
แบบนี้เราลองเปลี่ยน Prompt เป็นหน้าร้อนหน่อย

เหมือนว่าจะร้อนไม่พอ

ok กำลังได้ที่ 555

คลิปวีดีโอ
สรุป + ตอนต่อไป
ControlNet ช่วยให้เราสามารถควบคุมการสร้างภาพจาก Stable Diffusion ได้อย่างอิสระตามต้องการ ทั้งด้านโครงร่าง ท่าทาง และระยะความลึก ซึ่งทำได้ง่ายๆ ผ่าน Node ต่างๆ ใน ComfyUI
การฝึกใช้ ControlNet บ่อยๆ และหมั่นปรับแต่งค่า Weight หรือรูปภาพที่ใช้ควบคุม จะช่วยให้เราสร้างผลงานตรงใจได้มากขึ้นเรื่อยๆ ลองนำเทคนิคต่างๆ ในบทความนี้ไปใช้ดูนะครับ
แล้วพบกันใหม่ในบทความหน้า ที่จะมาสอนเรื่อง LoRA ที่จะช่วยสร้างภาพตัวละครหรือสไตล์ใหม่ๆ ที่โมเดลหลักดั้งเดิมมันไม่เคยเรียนรู้มาก่อนได้