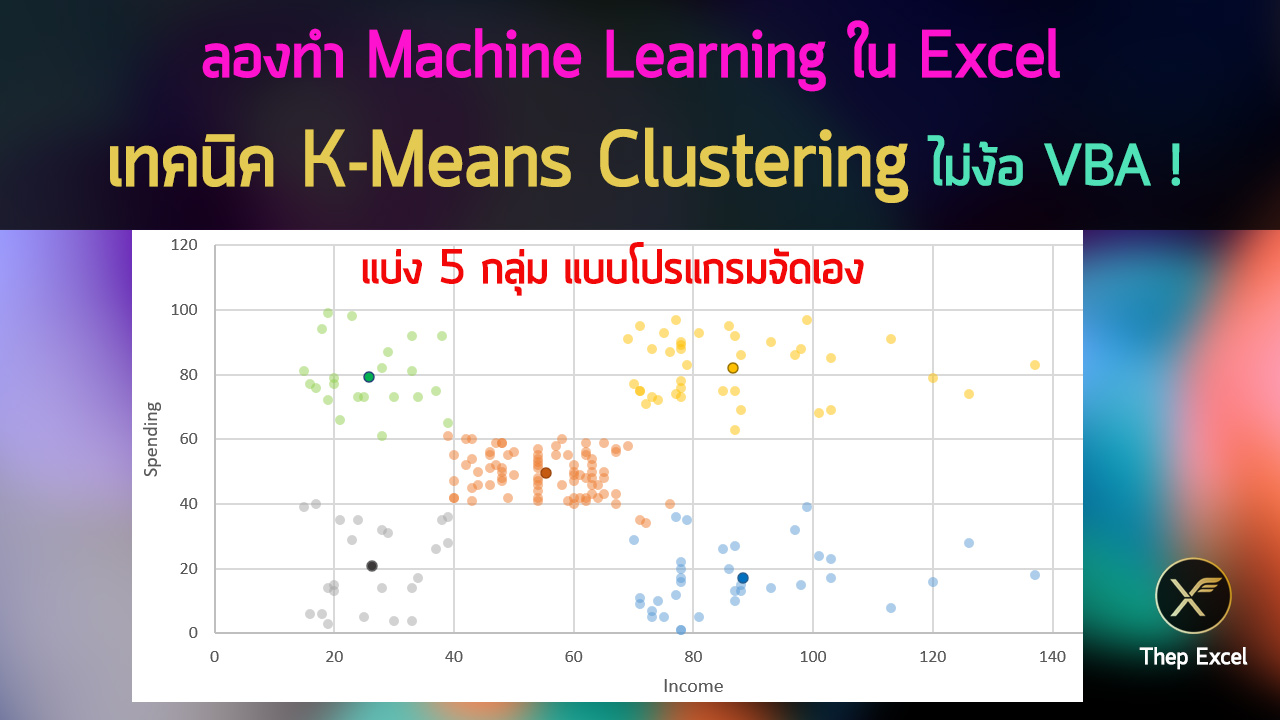


การแบ่งกลุ่มข้อมูลนั้นจริงๆ สามารถทำได้หลายวิธี ซึ่งวันนี้ผมจะมานำเสนอวิธีที่เรียกว่า K-Means Clustering นั่นคือ ให้โปรแกรมพยายามจัดกลุ่มที่มีความใกล้เคียงกันเข้าอยู่เป็นกลุ่มเดียวกันได้ด้วยตัวมันเอง โดยที่เราไม่ต้องเป็นคนบอกมันว่าแบบไหนควรอยู่กลุ่มอะไร ซึ่งมันต้องมีการวน Loop คำนวณซ้ำๆ หลายรอบ
หลายคนอาจคิดว่าการวน Loop จะต้องใช้ VBA เขียนโปรแกรมเอาแน่ๆ แต่ในบทความนี้ผมจะทำให้ดูว่า วิธีการเขียนสูตรธรรมดาๆ ในโหมดที่เรียกว่า Iterative Calculation ก็สามารถทำได้ครับ! รับรองว่าคุณจะได้เห็นแง่มุมใหม่ๆ ในการใช้สูตร Excel แบบที่ปกติไม่ค่อยได้เห็นแน่นอนครับ ^^
ลองลงมือทำดู
เราจะใช้ข้อมูลลูกค้าในห้าง อันนี้ https://www.kaggle.com/shwetabh123/mall-customers
โดยที่ผมจะลองแบ่งกลุ่มจากข้อมูลแค่ 2 แกน คือ Annual Income (k$) และ Spending Score (1-100) เท่านั้นครับ ซึ่งหากลองทำ Scatter Plot จะได้ดังนี้
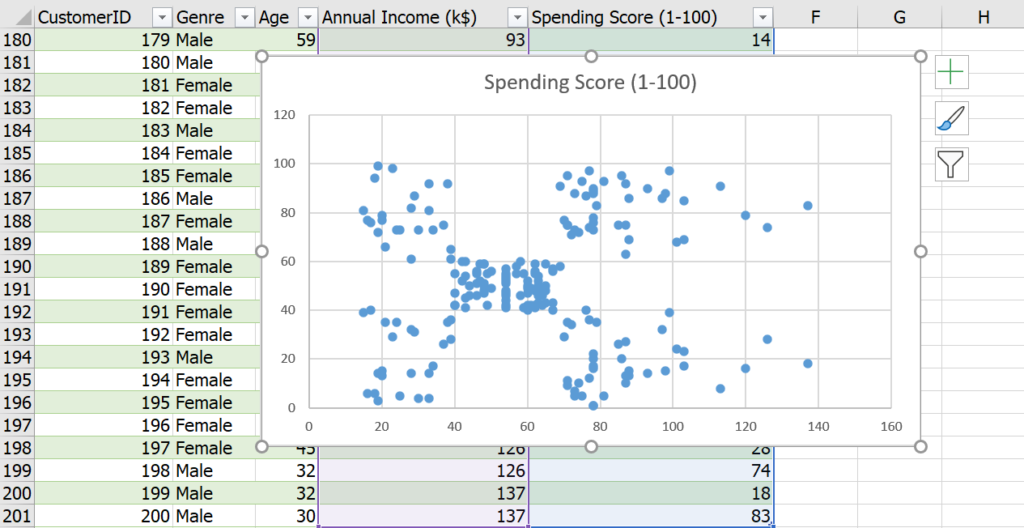
ซึ่งถ้าดูจากกราฟที่ออกมา ผมคิดว่าน่าจะแบ่งลูกค้าเป็น 5 กลุ่ม (เรียกจำนวนกลุ่มว่า k=5)
ขั้นตอนต่อไป ผมสร้าง sheet ใหม่แล้วเราจะ random สร้างจุดขึ้นมา 5 จุดจาก Range ของข้อมูลที่มี เสร็จแล้วทำให้กลายเป็น Value ไว้ด้วย จะได้ไม่เปลี่ยนอีก (x คือ Income, y คือ spending)

จากนั้นคำนวณว่าแต่ละจุดอยู่ใกล้ Point กลางอันไหนเท่าไหร่ ด้วยสูตรระยะห่างระหว่างจุด จากความสัมพันธ์เพื่อคำนวณด้านตรงข้ามสามเหลี่ยมมุมฉากสมัยเด็กๆ (ผมมีเปลี่ยนชื่อคอลัมน์เป็น Income กับ spending ด้วยจะได้ง่ายๆ)
Warning : การหาระยะห่าง ควรทำให้ข้อมูลตัวเลขมีปริมาณที่เป็น Standard ใกล้เคียงกันก่อน เพราะหากเลขเยอะๆ เช่น รายได้เป็นหมื่นเป็นล้าน มาหาระยะห่างกับเลขน้อยๆ เช่น อายุ ที่เป็นแค่หลักสิบ ระยะห่างจากรายได้มันจะกลับ effect ของอายุหมดเลย แต่พอดีข้อมูลนี้เลขมันค่อนข้างมีปริมาณพอๆ กันอยู่แล้วเลยไม่มีปัญหา
=SQRT((x1-x2)^2+(y1-y2)^2)=SQRT(([@Income]-VLOOKUP(F$1,Pointกลาง!$A:$C,2,0))^2+([@Spending]-VLOOKUP(F$1,Pointกลาง!$A:$C,3,0))^2)
แล้วเราก็ดูว่าห่างจากจุดกลางอันไหนน้อยที่สุด จะถือว่าข้อมูลอยู่ในกลุ่มนั้น ซึ่งเราก็เขียนสูตรหาได้ดังนี้
MinDistance (คอลัมน์ K) ก็ใช้ฟังก์ชัน MIN ปกติเลย
=MIN(F2:J2)ส่วนอยู่กลุ่มไหน (คอลัมน์ L) คำนวณดังนี้
=INDEX($F$1:$J$1,MATCH([@MinDistance],F2:J2,0))
จากนั้นกลับมาอีกชีทนึง แล้วผมก็ใช้ countifs เพื่อนับว่าแต่ละกลุ่มมีกี่จุด ดังนี้
=COUNTIFS(Mall_Customers[อยู่กลุ่มไหน],Pointกลาง!A2)
ความหมายของ K-Means
ขั้นตอนต่อไปคือ เราจะเอาจุดในกลุ่มเดียวกันมาหาค่าเฉลี่ย แล้วสถานปนาให้กลายเป็นจุด Center ตัวใหม่ แล้ววน Loop ทำแบบนี้ไปเรื่อยๆ จนกว่าจุด Center จะไม่เปลี่ยนอีกแล้ว ถึงจะจบขั้นตอน มันก็เลยเรียกว่า k-means ไงล่ะ เพราะเป็นการหาค่าเฉลี่ยของสมาชิกในกลุ่ม
แล้วเราจะทำเรื่องแบบนี้ใน Excel ได้ยังไง…
หลายคนอาจคิดว่ายังไงก็ต้องใช้ VBA ทำแน่ๆ แต่ในบทความนี้ผมจะลองทำอีกวิธีนึงนั่นก็คือ การใช้สูตรแบบ Iterative Calculation ครับ ซึ่งเป็นโหมดที่รองรับสูตรแบบงูกินหางหรือที่เรียกใช้ตัวเองซ้ำๆ ได้ โดยจะใช้งานได้จะต้องไปเปิดโหมดนี้ใน Excel Option ซะก่อน ซึ่งผมจะตั้งค่าให้มันทำทีละ 1 ครั้ง และเปิดโหมด Cal แบบ Manual ที่ต้องกด F9 ซะก่อน (จะได้เห็นภาพชัดๆ ว่าคืออะไรกันแน่?)

Iterative Calculation ทำงานยังไง?
สมมติเราเขียนสูตรในช่อง F2 ว่า
=F2+1ซึ่งจะเห็นว่าสูตรนี้มันเรียกข้อมูลจากตัวเองมาบวก 1 ซึ่งถ้าเป็นโหมดทำงานปกติใน Excel มันจะด่าเราว่าเป็น Circular Reference แล้วผลลัพธ์จะออกมาเป็น 0 ตลอด
แต่ถ้าเราเปิดโหมด Iterative Calculation แล้ว สูตรนี้จะทำงานได้แบบไม่ Error โดยที่ถ้า Maximum Iteration เป็น 1 เมื่อกด F9 1 ทีมันก็จะคำนวณ 1 รอบ ทำให้ช่อง F2 มีค่าเพิ่มเรื่อยๆ ทีละ 1 หลังจากกด F9
เอา Iterative Calculation มาวน Loop
เราก็มาแก้สูตรของ Center แต่ละตัว ให้เป็นการเฉลี่ยภายในกลุ่มตัวเอง ซึ่งผมจะใช้ AVERAGEIFS มาช่วยครับ (สูตรนี้เป็นสูตรงูกินหาง เพราะกลุ่มก็คิดจากจุด Center แล้วจุด Center ดันคิดจากกลุ่มอีก)
คำนวณค่า X (ลาก B2:B6 ใส่สูตรแล้วกด Ctrl+Enter เพื่อใส่สูตรพร้อมกัน)
=AVERAGEIFS(Mall_Customers[Income],Mall_Customers[อยู่กลุ่มไหน],Pointกลาง!A2)คำนวณค่า Y (ลาก C2:C6 ใส่สูตรแล้วกด Ctrl+Enter เพื่อใส่สูตรพร้อมกัน)
=AVERAGEIFS(Mall_Customers[Spending],Mall_Customers[อยู่กลุ่มไหน],Pointกลาง!A2)แล้วจะได้ผลลัพธ์ตามนี้ ซึ่งจำนวณจุดจะยังไม่เปลี่ยน (เพราะยังไม่ได้กด F9 เพื่อ Calculate)

คราวนี้เรากด F9 สูตรทั้งไฟล์จะคำนวณ 1 ครั้ง จะได้ผลดังนี้

คราวนี้เรากด F9 สูตรทั้งไฟล์จะคำนวณอีก 1 ครั้ง จะเห็นว่าจุดเปลี่ยนตำแหน่งไป (ลอง Plot กราฟดูก็ดีนะ)
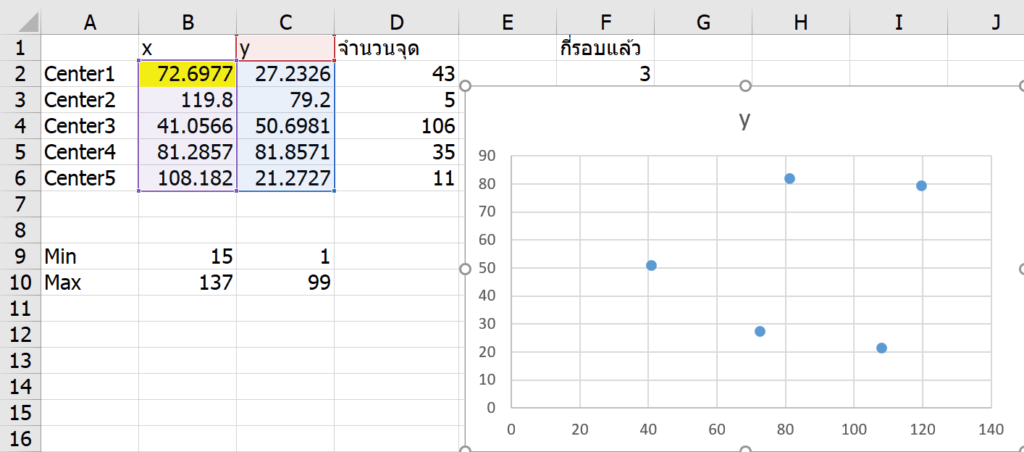
กด F9 ดูอีกซักรอบ จะเห็นเลยว่าจุดค่อยๆ ขยับ
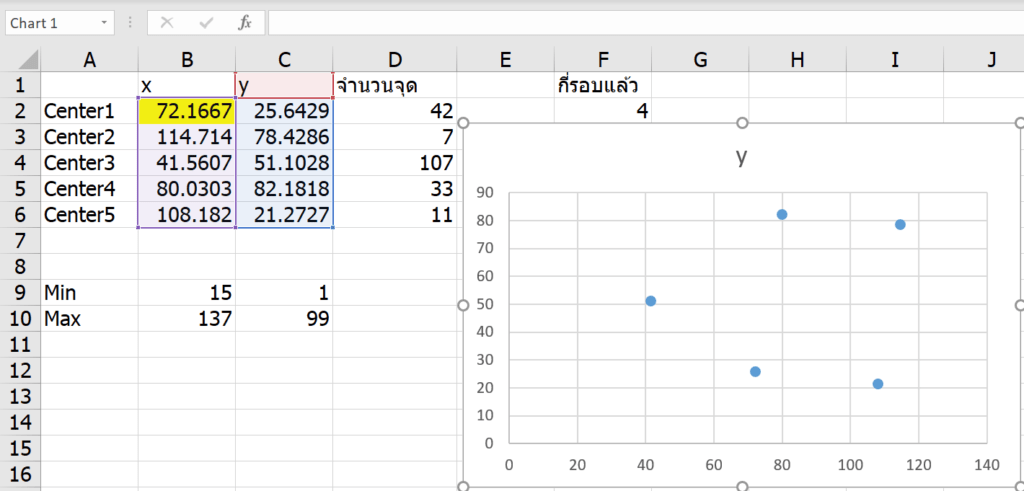
คราวนี้เราขี้เกียจมานั่งกด F9 หลายๆ รอบ ดังนั้นเราไปแก้ Option ให้มัน iterate ทีละ 10 ดีกว่า

แล้วเราก็ลองกด F9 ดู จะเห็นว่าคราวนี้มันทำทีเดียว 10 รอบต่อการกด F9 1 ครั้งเลย

ถ้ากดอีกที ก็จะเพิ่มอีก 10 จะเห็นว่าจุดไม่เปลี่ยนตำแหน่งแล้ว แสดงว่านี่แหละคือจุดสมดุลย์ที่จะเป็นจุดกึ่งกลางของแต่ละกลุ่มของเราแล้วล่ะครับ

หมายเหตุ : จริงๆ เราสามารถใส่จำนวน Iteration เยอะๆ เช่น 100 และทำแบบ Auto Calculate ก็ได้นะครับ แค่ผมทำแบบ Manual ให้ดูจะได้เห็นผลชัดๆ เฉยๆ
ลอง Random จุดเริ่มต้นใหม่อีกที
มันมีความเป็นไปได้ที่จุดเริ่มต้นแบบนึง ก็จะได้ผลลัพธ์แบบนึง ดังนั้นเราจะลอง Random จุดเริ่มต้นใหม่ โดยเราจะสร้าง Cell ขึ้นมาทำหน้าที่เป็น Switch เช่น H2 โดยเงื่อนไขคือ ถ้า H2=1 เราจะทำการ Random ใหม่นั่นเอง
ดังนั้นเราจะแก้สูตรของค่า X,Y ของ Center เป็นแบบนี้แทน
คำนวณค่า X (ลาก B2:B6 ใส่สูตรแล้วกด Ctrl+Enter เพื่อใส่สูตรพร้อมกัน)
=IF($H$2="Y",RANDBETWEEN($B$9,$B$10),AVERAGEIFS(Mall_Customers[Income],Mall_Customers[อยู่กลุ่มไหน],Pointกลาง!A2))คำนวณค่า Y (ลาก C2:C6 ใส่สูตรแล้วกด Ctrl+Enter เพื่อใส่สูตรพร้อมกัน)
=IF($H$2="Y",RANDBETWEEN($C$9,$C$10),AVERAGEIFS(Mall_Customers[Spending],Mall_Customers[อยู่กลุ่มไหน],Pointกลาง!A2))แล้วเราก็แก้ F2 ใหม่ด้วย เป็นดังนี้
=IF(H2="Y",1,F2+1)ซึ่งพอใส่ให้ H2 เป็น Y แล้วกด F9 จะพบว่าจุดจะเปลี่ยนที่เพราะถูก Random ใหม่ และจำนวนรอบถูก Reset

คราวนี้ลองลบค่า Y ออกจากช่อง H2 แล้วกดปุ่ม F9 จะได้ว่าจุดจะเปลี่ยนที่เพราะคำนวณค่า Mean ของกลุ่ม พอกดไปเรื่อยๆ คราวนี้จะไปสมดุลย์ที่นี่

เดี๋ยวเราจะลอง Random ค่าหลายๆ แบบ แล้ว Plot กราฟให้เห็นกลุ่ม และจุดศูนย์กลางชัดๆ
Plot กราฟ แยกกลุ่มให้เห็นภาพชัดๆ
เพื่อที่จะ Plot Scatter Plot แยกสีตามกลุ่มได้ เราต้องมี Data หลายๆ คอลัมน์ตามกลุ่มซะก่อน โดยผมใช้ Power Query Pivot Column แตก Group ออกมาเป็นหลายๆ คอลัมน์ซะ อันนี้เป็น MCode ของ query ที่ผมสร้างจาก table Mall_Customers นะครับ (code ดูน่าปวดหัว แต่จริงๆ เกิดจากการกดปุ่มไปเรื่อยๆ ไม่มีอะไรต้องเขียนเองเลย)
let
Source = Excel.CurrentWorkbook(){[Name="Mall_Customers"]}[Content],
#"Renamed Columns1" = Table.RenameColumns(Source,{{"Annual Income (k$)", "Income"}, {"Spending Score (1-100)", "Spending"}}),
#"Removed Other Columns1" = Table.SelectColumns(#"Renamed Columns1",{"อยู่กลุ่มไหน", "Income", "Spending"}),
#"Changed Type" = Table.TransformColumnTypes(#"Removed Other Columns1",{{"อยู่กลุ่มไหน", type text}, {"Income", Int64.Type}, {"Spending", Int64.Type}}),
#"Added Index" = Table.AddIndexColumn(#"Changed Type", "Index", 1, 1, Int64.Type),
#"Pivoted Column" = Table.Pivot(#"Added Index", List.Distinct(#"Added Index"[อยู่กลุ่มไหน]), "อยู่กลุ่มไหน", "Spending", List.Sum),
#"Sorted Rows" = Table.Sort(#"Pivoted Column",{{"Index", Order.Ascending}}),
#"Removed Other Columns" = Table.SelectColumns(#"Sorted Rows",{"Income", "Center1", "Center2", "Center3", "Center4","Center5"}),
#"Renamed Columns" = Table.RenameColumns(#"Removed Other Columns",{{"Center1", "Group1"}, {"Center2", "Group2"}, {"Center3", "Group3"}, {"Center4", "Group4"}, {"Center5", "Group5"}})
in
#"Renamed Columns"
แล้วค่อยสร้างกราฟ จาก Data ที่ Link จาก PrepareChart มาอีกที (ถ้าสร้างจากผลลัพธ์ query ตรงๆ แล้วบางที cell มันเลื่อนตำแหน่ง) โดยเขียนสูตรประมาณนี้
=IF(PrepareChart!A2="",NA(),PrepareChart!A2)
จะเห็นว่าการจัดกลุ่มแต่ละรอบอาจไม่เหมือนกันก็ได้ บางอันก็ดูดีกว่าอันอื่น เช่นอันนี้ ผมว่าดูดีที่สุดในความคิดผม
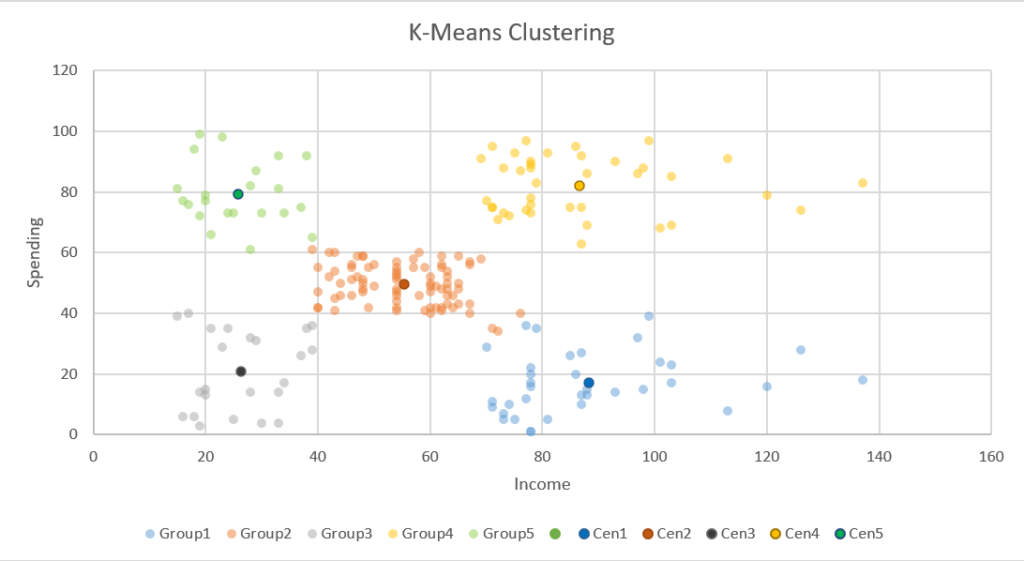
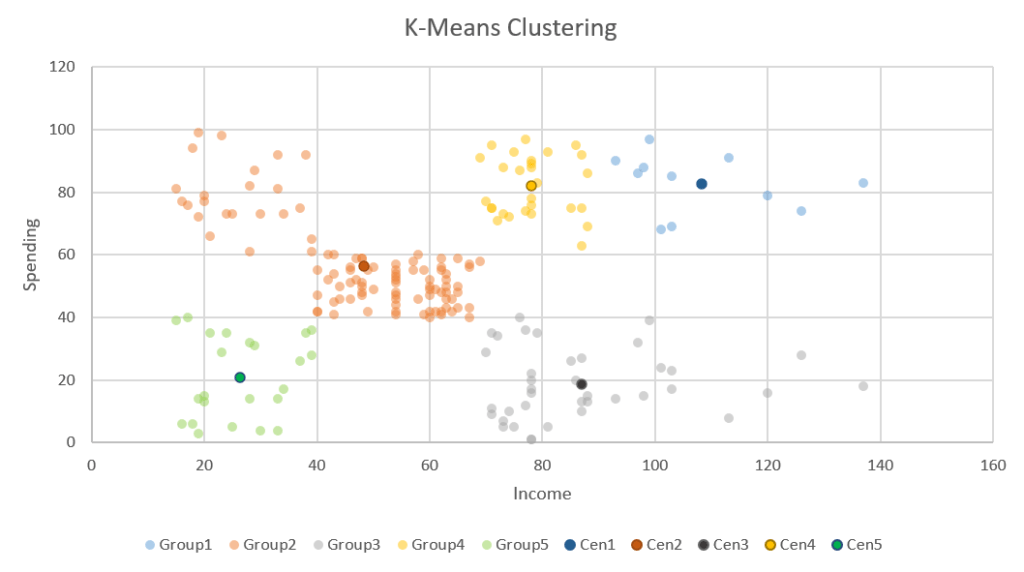
ส่วนอันอื่นๆ ก็ได้ผลเปลี่ยนไป ขึ้นอยู่กับ Random ตอนแรกไปลงแถวๆ ไหน

จบแล้ว
ในบทความนี้ก็เป็นการแนะนำ Concept ของการใช้เทคนิค K-Means Clustering และการใช้โหมด Iterative Calculation ใน Excel ครับ แต่ว่ายังไม่ได้แสดงวิธีหาจำนวนกลุ่มที่ Optimize ที่สุดนะครับ ว่า k ควรจะมีค่าเป็นเท่าไหร่? ไว้เดี๋ยวมีโอกาสจะเขียนแนะนำวิธีตัดสินใจให้อีกที แต่ถ้าใครอยากรู้ตอนนี้ก็สามารถไปอ่านเพิ่มเติมได้ที่นี่ก่อนได้ครับ