


การแบ่งกลุ่มลูกค้าหรือ การทำ Customer Segmentation เพื่อบริหารจัดการลูกค้าแต่ละกลุ่มอย่างเหมาะสมเป็นเรื่องที่สำคัญต่อการทำธุรกิจมาก เพราะว่าเราไม่สามารถลงแรงเพื่อดูแลลูกค้าทุกคนเท่าๆ กันได้ขนาดนั้น (ลองคิดตามกฎ 80:20 สิ)
แต่เราจะแบ่งลูกค้ายังไงดีล่ะ? แบ่งตามอะไร? แค่แบ่งตามยอดซื้อเท่านั้นเหรอ?
Model หนึ่งที่สามารถใช้ Data มาช่วยในการแบ่งกลุ่มลูกค้าได้นั่นก็คือ RFM Model หรือ RFM Analysis นั่นเอง
RFM Analysis คืออะไร?
RFM Analysis คือเทคนิคที่ใช้ Data เกี่ยวกับพฤติกรรมการซื้อของของลูกค้าในการแบ่งกลุ่มลูกค้า โดยขึ้นกับปัจจัย 3 ตัว ซึ่งย่อเป็น RFM นั่นก็คือ
- Recency : ซื้อครั้งล่าสุดสดๆ ร้อนๆ แค่ไหน? (Recent ที่แปลว่าไม่นานมานี้)
- Frequency : ซื้อบ่อยแค่ไหน?
- Monetary : มูลค่าเงินที่ซื้อเยอะแค่ไหน?
Edit : เดิมที ผมเขียนบทความนี้คิด Monetary เป็นยอดเงินรวมที่ลูกค้านั้นจ่ายทั้งหมดเลย แต่มีผู้รู้ คือ อาจารย์เช็ค Thanachart Ritbumroong ได้ให้คำแนะนำว่า ควรจะคิดจากมูลค่าเงินเฉลี่ยต่อครั้ง (Ticket Size) จะดีกว่าการคิดรวม (ซึ่งเป็นวิธีโบราณ) เพราะลูกค้าแต่ละคนมีอายุการเป็นลูกค้าไม่เท่ากัน ซึ่งผมก็เห็นด้วยเลยครับ การคิดจากยอดรวมมันมีความซ้ำซ้อนกับความถี่ในการซื้อไปแล้วด้วยซ้ำ ดังนั้นผมจึงจะขอแก้บทความนี้ใหม่ เป็นคิดเงินจากยอดเฉลี่ยต่อครั้งแล้วกันครับ
จากนั้นก็เอาข้อมูลของลูกค้ามาให้คะแนนในแต่ละด้าน โดยอาจจะให้คะแนน 1-5 ก็ได้ (1 คือคะแนนน้อย, 5 คือเยอะ) หรือบางค่ายอาจแบ่งเป็น 4 ท่อนก็ได้ อันนี้แล้วแต่เลยครับ แต่ในที่นี้ผมจะแบ่ง 5 ให้ดู เพราะแบ่ง 4 มันง่ายไป อิอิ
จากนั้นก็เอาผลที่ได้มาแบ่งเป็น Segment อีกทีซึ่งมีหลายสูตรมากๆ บางสำนักก็แบ่งเป็น 6 กลุ่มบ้าง 12 กลุ่มบ้าง ซึ่งผมว่ามันไม่ใช่สาระสำคัญ แต่สิ่งสำคัญคือการคัดเลือกกลุ่มที่เราควรจะเข้าไปจัดการต่อมากกว่า ว่าจะจัดการกลุ่มไหนยังไงดี? บางทีแบ่งเยอะไปก็จัดการไม่ถูกนะ
ข้อมูลตัวอย่าง
เพื่อให้เห็นภาพมากขึ้น เรามาลองวิเคราะห์ข้อมูลตัวอย่างอันนี้กันครับ เป็นไฟล์ csv นะ
https://www.kaggle.com/kyanyoga/sample-sales-data
คัดเลือกข้อมูลที่ต้องการ
ในไฟล์จะมีข้อมูลที่ไม่เกี่ยวข้องอยู่ด้วยเต็มไปหมด ผมจะขอคัดเลือกมาเฉพาะที่ต้องการ ซึ่งผมจะขอใช้ Power Query ทำเพราะสามารถจัดการประเภทข้อมูลได้ด้วยง่ายดี (แต่เพื่อนๆ จะใช้ Excel ปกติทำก็ได้นะ)
สรุปแล้ว ผมใช้ Data แค่นี้ก็เพียงพอต่อการทำ RFM แล้วล่ะ นั่นก็คือ ชื่อลูกค้า วันที่ซื้อของ และมูลค่าการซื้อครั้งนั้น
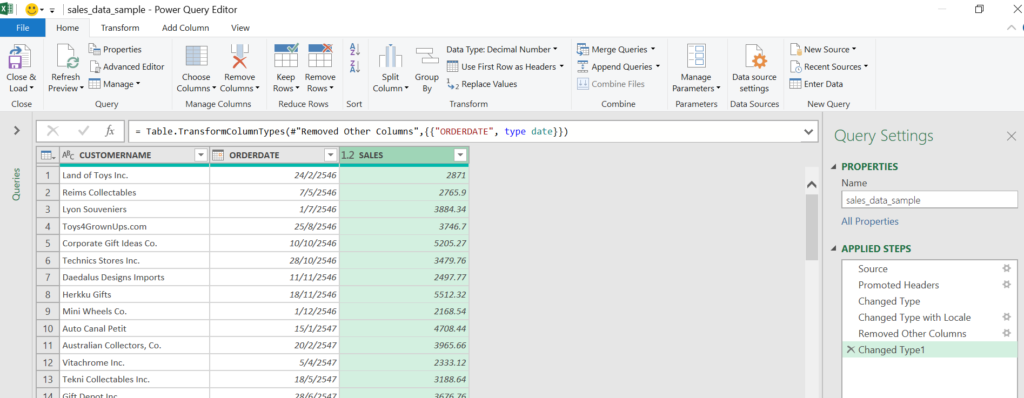
พอได้ข้อมูลแบบนี้ เดี๋ยวเราจะเอาไปเข้า PivotTable ต่อเลย เพื่อหาข้อมูลเป็นรายลูกค้า (จริงๆ จะใช้ Group By ใน Power Query ก็ได้ แต่กลัวบางคนใช้ไม่เป็น)
พอเอาเข้า Pivot Table เราก็จะลากสรุปข้อมูลรายลูกค้าดังนี้

ผมลาก OrderDate ลงมา 2 รอบ ซึ่งมันจะทำการสรุปด้วย Count ให้ ผมจะเปลี่ยนให้สรุปด้วยการใช้ค่า Max แทน เพื่อให้ได้วันที่ล่าสุดที่ซื้อ (อย่าลืมว่าวันที่คือตัวเลข ดังนั้นหาค่า Max ได้) ส่วน OrderDate2 เป็นการนับซึ่งผมจะถือว่าเป็น Frequency การซื้อของลูกค้าคนนั้นไปซะ
การเปลี่ยนวันที่ในคอลัมน์ B เป็น MAX จะได้เลข 3 หมื่นเกือบ 4 หมื่นออกมา ซึ่งมันคือค่าที่แท้จริงของวันที่ เราแค่กดคลิ๊กขวา Number Format แล้วเปลี่ยน Format เป็นวันที่ได้เลย ส่วนยอดเงินเฉลี่ยต่อครั้งในคอลัมน์ E ก็เกิดจากการเอายอดเงินรวมหารด้วยจำนวนครั้งที่ซื้อครับ (อันนี้ใช้วิธีหารเอาข้างๆ แบบลูกทุ่งเลย ในความเป็นจริงจะใช้ Calculated Field หรือ Measure ก็ได้นะครับ)
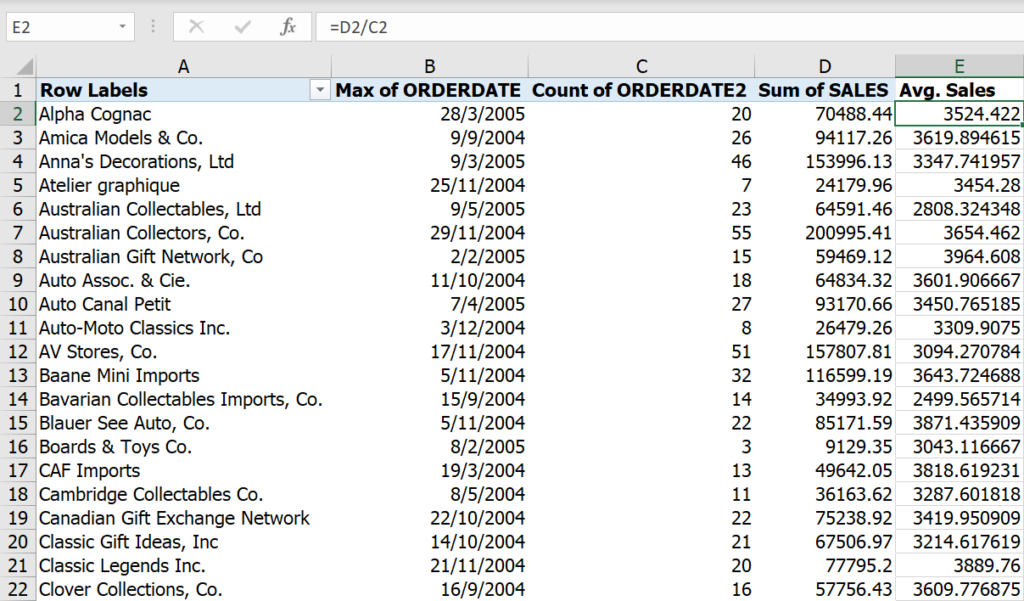
ที่นี้เราก็ได้ค่า R F M แล้วดังนี้

แบ่งคะแนนด้วยวิธีไหนดี?
หากเราเอาแค่ค่าน้อยสุดมากสุดมาแบ่งเป็น 5 ท่อนเฉยๆ มันจะไม่ Work อย่างแรง เนื่องจากข้อมูลมันเบ้ขวามากๆ ทำให้แต่ละท่อนมีข้อมูลต่างกันมากเลย ดังนั้นวิธีที่น่าจะ Work ที่สุดก็คือการหาค่า Percentile ที่ 20,40,60,80 มาเป็นตัวแบ่งนั่นเอง
หมายเหตุ : ที่เราสามารถคำนวณข้อมูลวันที่ได้เลยตรงๆ ไม่ต้องเอามาลบหาระยะห่างวัน เพราะถ้าวันที่ใหม่ เลขจะเยอะ ทำให้ได้อยู่ในกลุ่มคะแนนมากอยู่แล้ว
แต่ถ้าหากเราทำใน Excel เราสามารถใช้ PERCENTRANK มาช่วยหาได้ว่าค่าที่สนใจอยู่ที่ Percentile เท่าไหร่ แล้วเราค่อยมาปรับให้เป็น 1-5 อีกทีก็ได้ ดังนี้
อันนี้คำนวณอันดับ Percentile ของแต่ละค่าออกมาก่อน
=PERCENTRANK.INC(G$2:G$93,G2)
จากนั้นปรับให้เป็น Score 1-5 ซะ
=IF(K2=0,1,CEILING.MATH(K2/0.2,1))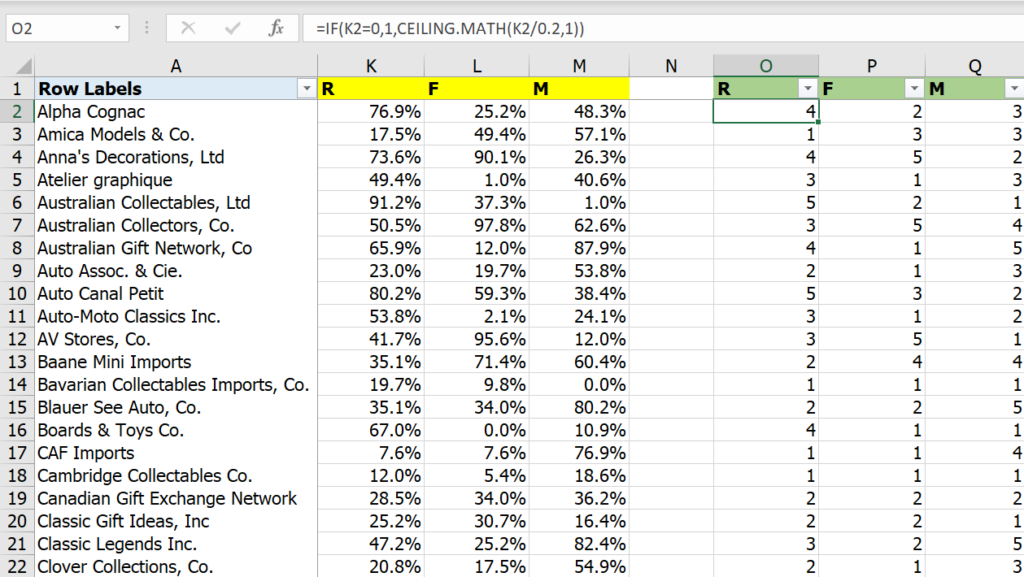
ได้เวลาจัด Segment
การจัด Segment นั้นทำได้หลายแบบมากๆ เช่น ถ้าไปดูตามเว็บต่างๆ จะเห็นว่ามีจัดเป็น Champions, Loyal Customer, New Customers อะไรแบบนี้ ซึ่งจริงๆ มันไม่ได้มีมาตรฐานสากลอะไร เช่น อันนี้คือไปเจอมาจากเว็บเมืองนอกดังนี้
| Segment | Description | R | F | M |
|---|---|---|---|---|
| Champions | Bought recently, buy often and spend the most | 4 – 5 | 4 – 5 | 4 – 5 |
| Loyal Customers | Spend good money. Responsive to promotions | 2 – 4 | 3 – 4 | 4 – 5 |
| Potential Loyalist | Recent customers, spent good amount, bought more than once | 3 – 5 | 1 – 3 | 1 – 3 |
| New Customers | Bought more recently, but not often | 4 – 5 | < 2 | < 2 |
| Promising | Recent shoppers, but haven’t spent much | 3 – 4 | < 2 | < 2 |
| Need Attention | Above average recency, frequency & monetary values | 3 – 4 | 3 – 4 | 3 – 4 |
| About To Sleep | Below average recency, frequency & monetary values | 2 – 3 | < 3 | < 3 |
| At Risk | Spent big money, purchased often but long time ago | < 3 | 2 – 5 | 2 – 5 |
| Can’t Lose Them | Made big purchases and often, but long time ago | < 2 | 4 – 5 | 4 – 5 |
| Hibernating | Low spenders, low frequency, purchased long time ago | 2 – 3 | 2 – 3 | 2 – 3 |
| Lost | Lowest recency, frequency & monetary scores | < 2 | < 2 | < 2 |
ถ้าพิจารณาดูแล้ว จะเห็นว่า คะแนนในตารางข้างบนที่ผมหามาได้ ตัว M ของเค้าหมายถึงยอดเงินรวม ไม่ใช่ยอดเฉลี่ยต่อครั้งเหมือนอันใหม่ที่ผมทำ ดังนั้นตารางนี้จึงไม่เหมาะกับผม
ในบทความนี้ผมจึงคิดเกณฑ์ใหม่ขึ้นมาเองให้เหมาะสมกับการให้คะแนนของผมเอง ตามตารางนี้ครับ (เราคิดการแบ่งของเราเองได้นะ ไม่ได้ผิด!) โดยที่หากลูกค้าคนใดสามารถอยู่ได้หลายกลุ่มพร้อมกัน ผมจะถือว่าให้เค้าอยู่ในกลุ่มที่สูงที่สุดยึดตาม Priority ใน List นี้ด้วยครับ
ผมเอาคะแนนที่เป็นไปได้ใส่ลงไปใน Cell โดยคั่นด้วย comma เลยแบบนี้ จะได้อ่านค่าได้ตรงๆ ด้วย FIND, SEARCH ได้ง่าย
| Segment | Description | R | F | M |
|---|---|---|---|---|
| สุดยอดลูกค้า | สุดยอดลูกค้า ดีสุดในทุกด้าน | 4,5 | 4,5 | 4,5 |
| เคยเป็นสุดยอดแต่หายไปนาน | เคยสุดยอด แต่ไม่ซื้อนานแล้ว | 1,2 | 4,5 | 4,5 |
| ลูกค้าใหม่จ่ายเยอะ | ลูกค้าใหม่ เพิ่งมาซื้อครั้งแรกๆ ซื้อก้อนโต | 4,5 | 1 | 4,5 |
| ลูกค้าใหม่จ่ายน้อย | ลูกค้าใหม่ เพิ่งมาซื้อครั้งแรกๆ ซื้อนิดเดียว | 4,5 | 1 | 1,2,3 |
| นานมาทีจ่ายเยอะ | นานๆ มาที ซื้อก้อนใหญ่ | 3,4,5 | 1,2 | 4,5 |
| นานมาทีจ่ายเยอะแต่หายไปนาน | นานๆ มาที ซื้อก้อนใหญ่ แต่ไม่ซื้อนานแล้ว | 1,2 | 1,2 | 4,5 |
| มาบ่อยจ่ายน้อย | มาบ่อยๆ แต่ซื้อนิดเดียว | 3,4,5 | 4,5 | 1,2 |
| มาบ่อยจ่ายน้อยแต่หายไปนาน | มาบ่อยๆ แต่ซื้อนิดเดียว แต่ไม่ซื้อนานแล้ว | 1,2 | 4,5 | 1,2 |
| ลูกค้าประจำ | ลูกค้าประจำ ซื้อบ่อย | 3,4,5 | 3,4,5 | 1,2,3,4,5 |
| ลูกค้าประจำแต่หายไปนาน | เคยเป็นลูกค้าประจำ แต่ไม่ซื้อนานแล้ว | 1,2 | 3,4,5 | 1,2,3,4,5 |
| ไม่ค่อยสำคัญ | น้อยในทุกด้าน | 1,2 | 1,2 | 1,2 |
| อื่นๆ | ไม่เข้าพวกข้างบน | 1,2,3,4,5 | 1,2,3,4,5 | 1,2,3,4,5 |
โดยที่ผมสร้าง Table ขึ้นมาว่า RFMtable ดังนี้

เพื่อให้เห็นภาพชัดที่สุด ผมจะเอา 12 Segment นี้ไปเป็นหัวตาราง แล้วคำนวณว่าลูกค้าแต่ละคนเข้า Segment นั้นได้หรือไม่ ดังนี้
สูตรใน S2 เป็นดังนี้ (ใช้ Logic AND ในการคิดแต่ละช่อง)
=AND(ISNUMBER(FIND($O2,INDEX(RFMtable[R],MATCH(S$1,RFMtable[Segment],0)))),
ISNUMBER(FIND($P2,INDEX(RFMtable[F],MATCH(S$1,RFMtable[Segment],0)))),
ISNUMBER(FIND($Q2,INDEX(RFMtable[M],MATCH(S$1,RFMtable[Segment],0)))))
ทีนี้เราจะหาว่า FinalSegment โดยหลักการคือ หาว่า TRUE ตัวแรกอยู่ที่อันไหน อันนี้ใช้ INDEX+MATCH มาช่วยได้ดังนี้
=INDEX($S$1:$AD$1,MATCH(TRUE,S2:AD2,0))
พอเอาข้อมูลไป Pivot ก็จะได้ผลลัพธ์ประมาณนี้

สรุป
จะเห็นว่าวิธีที่ผมทำให้ดูในบทความนี้ ค่อนข้างทุกลักทุเลหน่อยๆ คือมี Pivot แล้วมาทำต่อข้างนอก Pivot แล้วเอาไป Pivot ใหม่อีกที แต่มันก็สามารถได้คำตอบเหมือนกัน
ในตอนต่อไป ผมจะทำด้วยวิธีใช้ DAX ใน Power BI ซึ่งจะสามารถเขียน Measure ออกมาคำนวณให้ได้ผลลัพธ์ที่ต้องการได้แบบอัตโนมัติกว่านี้ครับ ใครสนใจก็รอติดตามได้เลยครับ