


ในตอนที่แล้วเราได้พูดถึงภาพรวมของสถิติและค่าทางสถิติเบื้องต้นกันไปแล้ว ในตอนนี้เราจะมาปูพื้นฐานอีกเรื่องที่สำคัญมากๆ นั่นก็คือเรื่อง ความน่าจะเป็น หรือภาษาอังกฤษว่า Probability นั่นเอง
Probability (ความน่าจะเป็น) คือ ค่าที่บอกให้รู้ว่าเหตุการณ์ที่เราสนใจจะมีโอกาสเกิดขึ้นมากหรือน้อยแค่ไหน
โดยมีค่าตั้งแต่ 0 (ไม่มีทางเกิดขึ้น) ถึง 1 (เกิดขึ้นแน่นอน) หรือจะเขียนเป็น 0% – 100% ก็ได้ (เพราะ % คือหาร 100)
เช่น ความน่าจะเป็นของการถูกรางวัลเลขท้าย 2 ตัว คือ 1 ใน100 หรือ 0.01 หรือ 1% เราก็จะรู้ว่าโอกาสมันน้อยมาก…
การเข้าใจความน่าจะเป็น จะช่วยให้เราตัดสินใจได้ดีขึ้น (กว่าไม่รู้) ซึ่งเรื่องนี้เป็นเรื่องที่มีประโยชน์มากๆ
บอกเลยว่าบทความนี้ยาวมาก แต่ผมก็ตั้งใจเขียนบทความนี้มากๆ เช่นกัน และอยากให้ออกมาดีที่สุดเท่าที่ทำได้ หวังว่าทุกคนจะได้ศึกษาจนเข้าใจและใช้มันได้อย่างสนุกสนานด้วยนะครับ
นิยามของคำที่เกี่ยวข้อง
การที่เราจะเข้าใจเรื่องความน่าจะเป็นนั้นเราจะต้องทำความรู้จักคำศัพท์ต่างๆ เหล่านี้ก่อน ดังนั้นมาลุยกันเลย!
- Trial = การทดลอง หรือ การสังเกตการณ์ ซึ่งมักจะเป็นเหตุการณ์ที่เราไม่รู้แน่ชัดถึงผลลัพธ์ เช่น Trial คือการโยนเหรียญ การทอยลูกเต๋า การการดึงไพ่ เป็นต้น ซึ่งความน่าจะเป็นนั้นจะให้ความสนใจถึงผลลัพธ์ของ Trial นั้นๆ
- Sample Space (S) = ผลลัพธ์ทั้งหมดที่เป็นไปได้ของ Trial
เช่น การโยนเหรียญ ซึ่งหน้าเหรียญที่เป็นไปได้มี 2 แบบ คือ h=หัว, t= ก้อย- ถ้า Trial เป็นการโยนเหรียญ 1 ครั้ง S ={h,t} คือมีทั้งหมด 2 แบบ
- ถ้า Trail เป็นการโยนเหรียญ 2 ครั้ง S = {(h, h), (h, t), (t, h), (t, t)} ซึ่งจะมีทั้งหมด 4 แบบ
- Events (E) = เหตุการณ์ใน Sample Space ที่เราสนใจ เช่น เหตุการณ์ที่เหรียญออกหัวอย่างน้อย 1 ครั้ง ในการโยนเหรียญ 2 ครั้ง คือ E={(h, h), (h, t), (t, h)} ซึ่งเป็นไปได้ 3 แบบ
ดังนั้น ความน่าจะเป็นของสิ่งที่เราสนใจ จะเขียนได้ว่า
Probability of Event หรือ P(E) = จำนวน Event E / จำนวน Sample Space = E/S
- S = {(h, h), (h, t), (t, h), (t, t)} = 4 แบบ
- E = {(h, h), (h, t), (t, h)} = 3 แบบ
ดังนั้น P(ออกหัวอย่างน้อย 1 ครั้งในการโยนเหรียญ 2 ครั้ง) = 3/4 = 0.75 หรือ 75% นั่นเอง
Counting Theory (กฎการนับ)
การที่จะคำนวณความน่าจะเป็นได้ดีแบบไม่ต้องมานั่งเขียนผลลัพธ์ที่เป็นไปได้ทีละตัวนั้น เราจะต้องนับ Event และ Sample Space ให้ถูกต้องโดยใช้หลักการต่างๆ เหล่านี้ให้เป็นเสียก่อน
กฏพื้นฐานของการนับ (Fundamental Principle of Counting)
มีกฎ หลักๆ 2 อันในการหาจำนวนผลลัพธ์ที่เป็นไปได้ คือ
- ถ้าสิ่งที่ต้องทำมีหลายขั้นตอน ให้เอาจำนวนทางเลือกแต่ละขั้นตอนคูณกัน
- ถ้าสิ่งที่ต้องทำเป็นไปได้หลายกรณี ให้เอาจำนวนผลลัพธ์ที่เป็นไปได้ในแต่ละกรณีบวกกัน (ระวังบวกเบิ้ลหากมีความเป็นไปได้ที่จะเกิดทั้ง 2 กรณีพร้อมกัน)
ตัวอย่าง : แต่งตัวเล่นละคร Titan
สมมติว่าในการเล่นละครเวทีคุณต้องเลือกว่าจะเล่นเป็นฝ่ายมนุษย์ หรือฝ่าย Titan (ยักษ์)
- ถ้าเป็นฝ่ายมนุษย์ : จะมีเสื้อให้เลือก 4 แบบ กางเกง 2 แบบ
- ถ้าเป็นฝ่าย Titan : จะเลือกใส่ชุดได้ 9 ชุด แต่ละชุดมี 3 สี
ถามว่ามีความเป็นไปได้ในการแต่งตัวเล่นละครเวทีทั้งหมดกี่แบบ?
แบบนี้จะเห็นว่ามี 2 กรณี คือ กรณีเล่นเป็นมนุษย์ กับเล่นเป็นฝ่าย Titan ซึ่งเราต้องคิดแยกกรณีกัน แล้วเอามาบวกกัน
ฝ่ายมนุษย์ : มีเสื้อ 4 แบบ กางเกง 2 แบบ จะแต่งตัวได้กี่แบบ = มีขั้นตอนต้องทำ 2 ขั้นคือ เลือกเสื้อกับเลือกกางเกง
ดังนั้นต้องเอารูปแบบของทั้ง 2 ขั้นตอนคูณกัน = ใส่เสื้อ ได้ 4 แบบ * ใส่กางเกงได้ 2 แบบ = มีการใส่เสื้อผ้า 8 วิธี
ฝ่าย Titan : มี 9 ชุด 3 สี = มีขั้นตอนต้องทำ 2 ขั้นคือ เลือกชุดกับเลือกสี
ดังนั้นต้องเอารูปแบบของทั้ง 2 ขั้นตอนคูณกัน = ใส่ชุด ได้ 9 แบบ * เลือกสีได้ 3 แบบ = มีการใส่เสื้อผ้า 27 วิธี
รวมทุกกรณี มีรูปแบบการใส่เสื้อผ้า = 8 + 27 = 35 วิธี
ทำไมมีหลายขั้นตอนแล้วต้องคูณกัน?
วิธีที่จะเข้าใจเรื่องการนับพื้นฐานได้ดี คือ การวาดแผนผังต้นไม้ (Tree Diagram) ดังนี้ จะเข้าใจได้เลยว่าทำไมต้องคูณกัน

โดยที่ใน Excel เราสามารถเอาตัวเลขทั้งหมดใน Range คูณกันได้ง่ายๆ โดยใช้ฟังก์ชัน PRODUCT มาช่วย
=PRODUCT(data) // ใส่ data เป็น range ได้เลย
ใครสนใจวิธี List ความเป็นไปได้ทั้งหมดออกมา สามารถดูในคลิปนี้ได้ครับ
ทำความรู้จัก Factorial
คำถาม : ตัวอักษรคำว่า SIRA สามารถนำมาสลับกันได้กี่รูปแบบ? (ไม่สนใจความหมาย)
วิธีคิดให้เข้าใจง่ายๆ คือ เหมือนมี Slot ให้ใส่ข้อความได้ 4 ตำแหน่ง แล้วเรามี Block ตัวอักษรอยู่ 4 ตัวคือ S, I, R, A เราจะสามารถสร้างคำได้กี่รูปแบบ?
แสดงว่าการทำงานมี 4 ขั้นตอน คือ เลือกตัวใส่ Slot1, 2, 3, และ 4 ตามลำดับ ดังนั้นเราต้องเอารูปแบบแต่ละขั้นตอนมาคูณกัน
- Slot 1 = มีให้เลือก 4 ตัว
- Slot 2 = มีให้เลือก 3 ตัว (เพราะหยิบไปใส่ใน Slot 1 แล้วอันนึง)
- Slot 3 = มีให้เลือก 2 ตัว
- Slot 4 = มีให้เลือก 1 ตัว
ดังนั้นการคำนวณ = 4*3*2*1 = 24 วิธี ดังนี้ (เห็นมะว่าเยอะ ผม List เองยังเหนื่อยเลย)

ซึ่งเจ้า 4*3*2*1 นั้น สามารถเขียนได้อีกอย่างว่า 4! ซึ่งอ่านว่า “4 แฟคตอเรียล”
โดยที่ n! อ่านว่า “n แฟคตอเรียล” หมายถึง เอาตัวมันเองคูณด้วยตัวมันเองลบ 1 ไปเรื่อยๆ จนถึง 1 นั่นเอง
*สิ่งที่ควรรู้คือ ค่า 0! จะได้ 1 นะครับ
ซึ่งใน Excel สามารถใช้ฟังก์ชัน FACT ได้แบบง่ายๆ คือ
=FACT(number) =FACT(4) จะออกมาได้ =24 เลย
กรณีมีตัวซ้ำที่เราไม่อยากจะนับ
อย่างไรก็ตามหากรูปแบบบางอย่างให้ผลลัพธ์เหมือนกันแล้วเราไม่อยากจะนับซ้ำ เราสามารถหารทิ้งเพื่อกำจัดตัวซ้ำได้
เช่น ตัวอักษรคำว่า SIRI สามารถนำมาสลับกันได้กี่รูปแบบ? (ไม่สนใจความหมาย)
ถ้าคิดแบบผิวเผิน เผลอคำนวณด้วยหลักการเดิมว่ามี 4 Slot จะได้ออกมาเป็น 4! คือ 24 รูปแบบ
แต่ถ้าดูผลลัพธ์แล้วจะพบเหตุการณ์เหล่านี้… ว่ามันมีข้อมูลซ้ำกันอยู่

รูปแบบมันซ้ำกันเพราะตัว i มี 2 ตัว ซึ่งสลับที่กันแล้วไม่มีความหมาย ทำให้หากลอง Remove Duplicates ใน Excel จะเห็นว่ามีรูปแบบผลลัพธ์แค่ 12 แบบเท่านั้น ไม่ใช่ 24
วิธีคำนวณที่ถูกต้อง ต้องเอาจำนวนรูปแบบการสลับของตัวที่ซ้ำไปหารทิ้ง คือ i ที่มี 2 ตัว ไปคำนวณรูปแบบการสลับได้ 2! (แฟคตอเรียล) แล้วเอาไปหารทิ้ง นั่นคือ
=4!/2! = FACT(4)/FACT(2) = 12 //โดยที่หารด้วย 2! เพราะมีตัว i ซ้ำกัน 2 ตัว ถ้าถามว่า คำว่า THEPEXCEL สลับกันได้กี่แบบ?
=9! /3! = FACT(9)/FACT(3) = 60480 วิธี //โดยที่หาร 3! เพราะมีตัว e ซ้ำกัน 3 ตัวถ้าถามว่าคำว่า GOOGLE สลับกันได้กี่แบบ?
=6!/2!2! = FACT(6)/(FACT(2)*FACT(2)) = 180 วิธี
//โดยที่หาร 2! 2รอบ เพราะมีตัว G ซ้ำกัน 2 ตัว และ O ซ้ำกัน 2 ตัว นั่นเองซึ่งกฎการนับนี้มันก็จะสามารถเอามาทำให้กลายเป็นสูตรสำเร็จรูปได้อีก 2 แบบใหญ่ๆ ก็คือ Permutation กับ Combination ซึ่งเอาจริงๆ แล้วเราใช้แต่กฎการนับก็ได้คำตอบแบบเดียวกันนั่นแหละ แต่สูตรสำเร็จรูปเหล่านี้มีให้ใช้ใน Excel ด้วย มันจึงง่ายกว่าปกติมากๆ
Permutation (เรียงสับเปลี่ยน)
คือการหาจำนวนรูปแบบที่เป็นไปได้ทั้งหมดจากการเลือกของ k สิ่งจาก n สิ่ง โดยที่ลำดับมีความสำคัญ มีสูตรคือ
nPk = n! / (n-k)! //โดยที่ลำดับมีความสำคัญเช่น มีของกิน 5 อย่าง เลือกกิน 2 อย่าง จะเลือกได้กี่แบบ โดยที่ลำดับในการกินมีความสำคัญ
จะได้ว่า
5P2 = 5!/(5-2)! = 5!/3! = 5*4 = 20 แบบใน Excel เราสามารถใช้ฟังก์ชัน PERMUT ได้เลย
=PERMUT(number,number_chosen)
=PERMUT(5,2) จะออกมาได้ 20 เลยแบบชิวๆจริงๆ ถ้ามองด้วยกฎการนับมันก็ Make Sense มากๆ อยู่แล้ว ตอนแรกมีของ 5 อย่างให้เลือก คือ 5 วิธี เมื่อเลือกไปแล้ว 1 อย่าง ทำให้เหลือให้เลือกในขั้นตอนต่อไปเพียง 4 วิธี ทำให้เป็น 5 * 4 = 20 แบบ นั่นเอง
ซึ่งถ้าหากมีของ 5 อย่าง เลือกกิน ทั้งหมด 5 อันเลย ก็จะมีลำดับการกิน = 5*4*3*2*1 หรือ 5! นั่นเอง
Combination (การจัดหมู่)
Combination นั้นจะเหมือนกับ Permutation แต่ว่าการเรียงลำดับไม่มีความหมาย ดังนั้น จำนวนวิธีในการจัดเรียงจึงต้องน้อยกว่า Permutation แน่นอน ทำให้ต้องหาร Permutation ด้วย k! (เพื่อกำจัดตัวซ้ำความหมาย คล้ายๆ กับตัวอย่างข้างบนที่เราหารตัวซ้ำ) ได้ว่า
nCk = n! / (n-k)!k! //โดยที่ลำดับไม่มีความสำคัญเช่น ถ้าคล้ายๆ ในตัวอย่างที่แล้วคือ มีของกิน 5 อย่าง เลือกกิน 2 อย่าง แต่คราวนี้ลำดับการกินไม่สำคัญ
เราจะได้ว่า
5C2 = 5!/(5-2)!2! = 10 แบบใน Excel เราสามารถใช้ฟังก์ชัน COMBIN ได้เลย
=COMBIN(number,number_chosen)
=COMBIN(5,2) จะออกมาได้ 10 เลยง่ายๆตัวอย่าง Permutation, Combination
ตัวอย่าง : เลือกคนมาเข้าขบวนการ 5 สี
จะมีวิธีในการเลือกคนมาเป็นขบวนการ 5 สี ที่มี 3 สีเป็นผู้ชาย อีก 2 สีเป็นผู้หญิง จากชายที่มีศักยภาพ 10 คน หญิง 7 คน ได้กี่วิธี
จะเห็นว่ามี 2 ขั้นตอน คือ ขั้นตอนการเลือกผู้ชาย กับ ขั้นตอนเลือกผู้หญิง ดังนั้นต้องเอารูปแบบคูณกัน
- ขั้นตอนการเลือกผู้ชาย = 10P3 ซึ่งใช้ Permutation เพราะลำดับของสีมีความสำคัญ =PERMUT(10,3)
- ขั้นตอนการเลือกผู้หญิง = 7P2 ซึ่งใช้ Permutation เพราะลำดับของสีมีความสำคัญ =PERMUT(7,2)
สรุป
=PERMUT(10,3)*PERMUT(7,2) = 30240 วิธีตัวอย่าง : เลือกดินสอสีมา 4 สี จากกล่องดินสอ 12 สี
ความต้องการ 1 : เลือกสีมา 4 สี สีอะไรก็ได้ จากดินสอ 12 สี
=12C4 =COMBIN(12,4) = 495 แบบความต้องการ 2 : เลือกสีมา 4 สี ต้องมีสีเขียวด้วยเสมอ จากดินสอ 12 สี
ให้มองเป็นเลือกสีเขียวมาก่อน แล้วค่อยเลือกสีอื่นอีก 3 สี
=1C1 * 11C3 = COMBIN(11,3) = 165 แบบคำนวณความน่าจะเป็น
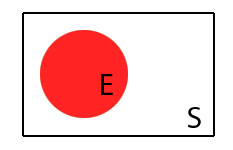
พอเราสามารถนับเหตุการณ์ทั้งหมดได้ (Sample Space) และนับเฉพาะเหตุการณ์ที่สนใจได้ (Event)
เราก็จะสามารถคำนวณความน่าจะเป็นของ Event E ได้ว่า
P(E) = จำนวน Event E / จำนวน Sample Space = E/S นั่นเองรูปแบบความสัมพันธ์ทางตรรกศาสตร์ของเหตุการณ์
ทีนี้เรื่องของเหตุการณ์ที่เราสนใจ มันอาจจะมีหลายเหตุการณ์ก็ได้ ซึ่งบางทีเหตุการณ์เหล่านั้นก็มีความสัมพันธ์เชิง Logic กัน ดังนี้ เช่น สมมติว่า
- S คือ คนในบริษัททั้งหมด (Sample Space คือ สิ่งที่เป็นไปได้ทั้งหมด)
- E คือ คนในบริษัทที่ใส่แว่น (Eye Glass)
- F คือ คนในบริษัทที่เป็นผู้หญิง (Female)
เราสามารถใช้ความรู้นี้ประยุกต์ใช้ได้กับทั้งกฏการนับ และ ความน่าจะเป็นเลย (เพราะจริงๆ ก็คือแนวคิดเดียวกัน)
Union การรวมเหตุการณ์ด้วยเงื่อนไขแบบ OR หรือ เขียนโดย E U F คือ เหตุการณ์ E หรือ F หรือ ทั้ง 2 อย่างเกิดขึ้น

ดังนั้น E U F คือ เหตุการณ์ที่เจอคนที่ใส่แว่น หรือ เป็นผู้หญิงก็ได้ ซึ่งรวมถึงคนเหล่านี้ทั้งหมด
- เป็นผู้ชายใส่แว่น
- เป็นผู้หญิงไม่ใส่แว่น
- เป็นผู้หญิงใส่แว่น
Intersection = เหตุการณ์ที่ซ้ำกัน E ∩ F คือ ต้องเกิดทั้งเหตการณ์ E และ F พร้อมกัน
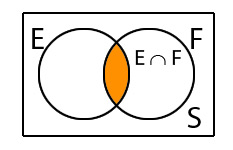
ดังนั้น E ∩ F คือ เหตุการณ์ที่ต้องเป็นเจอผู้หญิงใส่แว่นเท่านั้น
Complement = ~E คือ เหตการณ์ที่ไม่ใช่เหตการณ์ E

ดังนั้น ~E คือ เหตุการณ์ที่เจอคนไม่ใส่แว่นเท่านั้น
ซึ่ง P(E) + P(~E) = P(S) = 1 ประโยชน์ของกฎเรื่อง Complement
จาก P(E) + P(~E) = 1 เราสามารถเขียนได้ว่า
P(E)= 1 - P(~E) เช่น ถ้ารู้ความน่าจะเป็นคนที่ไม่ใส่แว่นว่าคือ 70% ดังนั้นความน่าจะเป็นของคนใส่แว่นคือ 30% นั่นเอง
ซึ่งแปลว่าบางทีเมื่อเราหาความน่าจะเป็น P(E) ตรงๆ ยาก เราก็หาตัวที่ไม่ใช่ E ที่เรียกว่า P(~E) แล้วค่อยเอา 1 มาลบจะง่ายกว่า อย่างเช่นตัวอย่างต่อไปนี้
ตัวอย่าง : วันเกิดตรงกัน
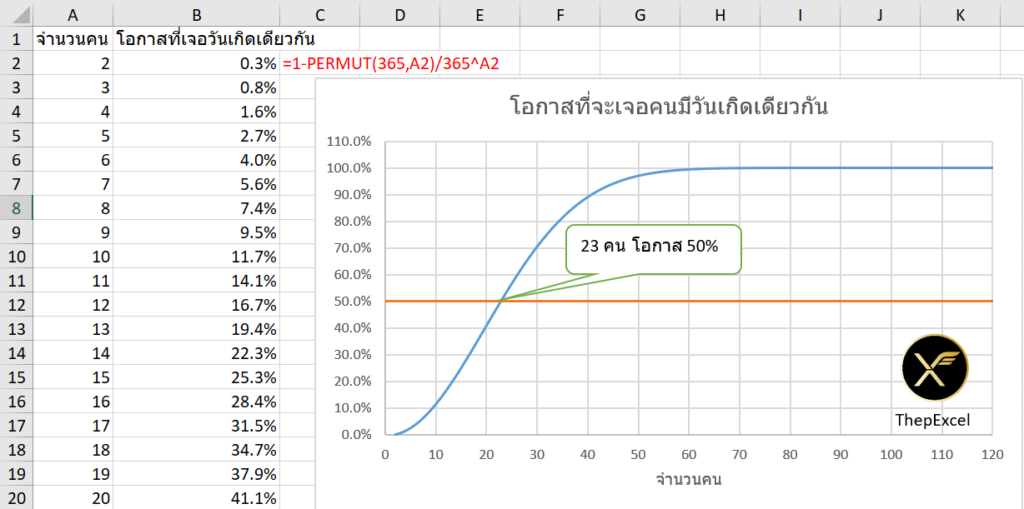
จงหาโอกาสที่กลุ่มคนจำนวน 30 คนจะมีอย่างน้อย 1 คู่ที่มีวันเกิดตรงกัน?
การจะหาอย่างน้อย 1 คู่ที่วันเกิดตรงกันตรงๆ นั้นยาก ให้หาโอกาสที่คน 30 คนจะมีวันเกิดไม่ตรงกันเลยดีกว่า (ผมขอ assume ว่าปีนึงมี 365 วันเสมอเพื่อความง่าย)
ให้คิดว่าวัน 365 วันในปีเป็นลูกบอลในโหลจำนวน 365 ลูก แล้วเราต้องสุ่มทั้งหมด 30 ครั้ง = 365^30 แบบ
กรณีที่คน 30 คนมีวันเกิดไม่ตรงกันเลย ก็คือ คนแรกเป็นไปได้ 365 แบบ แต่คนต่อไป เหลือ 364,363,362… ไปเรื่อยๆ
อยากให้คูณไล่จาก 365 ไปแค่ 30 รอบ ซึ่งมองได้ว่า= 365!/(365-30!) = ใช้สูตร Permutation ได้= 365P30 ก็ได้ =PERMUT(365,30)
ดังนั้นความน่าจะเป็น ที่คน 30 คนมีวันเกิดไม่ตรงกันเลย คือ
=PERMUT(365,30)/365^30
=29.368%โอกาสที่คน 30 คนจะมีอย่างน้อย 1 คู่ที่วันเกิดตรงกัน = 1 – ความน่าจะเป็น ที่คน 30 คนมีวันเกิดไม่ตรงกันเลย
=1-PERMUT(365,30)/365^30
=70.63 %ดังนั้นไม่ใช่เรื่องแปลกเลยที่นักเรียนในห้องเดียวกันมักจะมีอย่างน้อย 1 คนที่มีวันเกิดเดียวกันครับ
ถ้าลองเอาไป Plot กราฟใน Excel ก็จะได้ประมาณนี้
ความรู้เบื้องต้นเกี่ยวกับสำรับไพ่เพื่อเรียนรู้ความน่าจะเป็น
ในตัวอย่างหลายๆ อันในนี้จะมีการพูดถึงไพ่ โดยไพ่มาตรฐานจะมีลักษณะดังนี้ (แต่คิดว่าหลายๆ คนคงรู้จักไพ่อยู่แล้วเนอะ 555)
- ไพ่ 1 สำรับมี 52 ใบ (ไม่เอา Joker)
- ประกอบด้วย 4 ชุด คือ ดอกจิก (clubs) ,โพธิ์ดำ (spades), ข้าวหลามตัด (diamonds), โพธิ์แดง หรือหัวใจ (hearts)
- โดยที่ 2 ชุดแรกสีดำ, 2 ชุดหลังสีแดง (พูดง่ายๆ คือมีดำครึ่งนึง แดงครึ่งนึง)
- แต่ละชุดมีไพ่ 13 ใบ คือ Ace, เลข 2-10, และอีก 3 หน้า แจค (jack), แหม่ม (queen), คิง (king)
- ผมทำเป็นภาพสรุปไว้ให้ดังนี้

การคำนวนความน่าจะเป็น (หรือใช้กับกฎการนับก็ได้) เมื่อมีเหตุการณ์มากกว่า 1 เหตุการณ์
แบบเกิดอย่างน้อยเหตุการณ์ใดเหตุการณ์หนึ่ง (Union=OR)
- หลักการคือเอาความน่าจะเป็นมารวมกัน แค่ว่าระวังว่าการรวมนั้นจะทำให้เบิ้ลหรือไม่ เช่น
- กรณีที่เหตุการณ์ทั้งสองอย่างไม่สามารถเกิดพร้อมกันได้ (เรียกว่า Mutually Exclusive)
- เมื่อไม่มีส่วนซ้ำ ก็จะบวกกันตรงๆ ได้เลย
- P (E U F) = P(E) + P(F)
- กรณีเหตุการณ์ทั้งสองอย่าง สามารถเกิดพร้อมกันได้
- เพราะ E และ F มีส่วนซ้ำกัน ทำให้ถ้าบวกตรงแล้วเราจะนับเบิ้ลไป 1 ที จึงต้องเอาส่วนที่ซ้ำกันออกไป 1 ที (ให้หายเบิ้ล)
- P (E U F) = P(E) + P(F) – P(E ∩ F)
- ซึ่งจะเห็นว่า ถ้าเป็น Mutually Exclusive แล้ว P(E ∩ F) จะเท่ากับ 0 ทำให้ได้สูตรข้างบนนั่นเอง
แบบต้องเกิดทั้ง 2 เหตุการณ์ (Intersect=AND)
- หลักการคือเอาความน่าจะเป็นมาคูณกัน เหมือนกับกฏการนับทั่วไปเลย ซึ่งขึ้นกับว่าเมื่อเกิดเหตุการณ์แรกไปแล้วเหตุการณ์ที่ 2 ที่จะเกิดขึ้นนั้น มีความน่าจะเป็นเปลี่ยนไปหรือไม่ ? ถ้าไม่เปลี่ยนก็ใช้ตัวเดิม (เรียกว่า Independent) ถ้าเปลี่ยน (เรียกว่า Dependent) ก็ต้องแก้ความน่าจะเป็นให้สอดคล้องกับความเป็นจริงนั้นๆ
- กรณีเหตุการณ์ทั้งสองไม่ขึ้นต่อกัน (Independent)
- เช่น หาความน่าจะเป็นของการโยนเหรียญ 2 ครั้งแล้วออกหัวทั้ง 2 ครั้ง จะได้ว่า
- เรามีเหตุการณ์ที่เกิดขึ้น 2 อัน คือ E = การโยนเหรียญครั้งแรกได้หัว , F = การโยนเหรียญครั้งที่สองได้หัว
- P(E) = P(ออกหัว) = 0.5
- P(F) = P(ออกหัว) = 0.5
- P(E ∩ F) = ความน่าจะเป็นที่ครั้งแรกและครั้งที่สองออกหัว = P(E) × P(F) = 0.5 x 0.5 = 0.25
- กรณีที่เหตุการณ์นั้นขึ้นต่อกัน (Dependent) :
- เช่น หาความน่าจะเป็นที่จะจั่วไพ่ Q 2 ครั้งติดกัน โดยไม่มีการใส่ไพ่คืน (การจั่วครั้งแรกมีผลต่อครั้งที่สองแน่นอน)
- เรามีเหตุการณ์ที่เกิดขึ้น 2 อัน คือ E = การจั่วครั้งแรกได้ Q, F = การจั่วครั้งที่สองได้ Q
- ซึ่งความน่าจะเป็นของการจั่วได้ Q = 4/52 (เพราะในไพ่ 52 ใบ นั้นมี Q 4 ตัว)
- ดังนั้น P(E) = P(จั่วได้ Q) = 4/52 อันนี้ไม่มีอะไรแปลก
- แต่สำหรับการจั่วครั้งที่สอง เราจะใช้ P(จั่วได้ Q) ซึ่งคือ ความน่าจะเป็นของการจั่วได้ Q เฉยๆ ไม่ได้ เพราะในความเป็นจริงโอกาสในการได้ Q ในครั้งที่สองมันเปลี่ยนไปแล้ว เป็น 3/51 (เพราะเหลือ Q3 ใบ จากไพ่ที่เหลือ 51 ใบ)
- เราเรียกความน่าจะเป็นของการจั่ว Q ในครั้งที่สอง (ที่เปลี่ยนไปจากการจั่ว Q ไปครั้งแรกสำเร็จแล้ว)
ว่า P(จั่วQครั้งสอง | จั่ว Q ครั้งแรก) ซึ่งมีชื่ออย่างเป็นทางการว่า Conditional Probability นั่นเอง ในที่นี้ผมใช้ว่า P(F|E)
- สูตรคือ P(E ∩ F) = P(E) × P(F|E)
- สรุปแล้ว P(E ∩ F) = ความน่าจะเป็นที่จะจั่วไพ่ได้ Q 2 ครั้งติดกัน = P(E) × P(F|E) = 4/52 * 3/51 = 0.004525 หรือ 0.45% นั่นเอง
- หากจริงๆ แล้วเหตุการณ์ E กับ F ไม่ขึ้นต่อกัน จะทำให้ P(F|E) เท่ากับ P(F) เฉยๆ
- ทำให้ P(E ∩ F) = P(E) × P(F) เท่ากับกรณี Independent นั่นเอง
ตัวอย่าง 1 : จั่วไพ่ J Q K และสีดำ
ถ้าจั่วไพ่ออกมา 1 ใบจากสำรับ 52 ใบ จงหาโอกาสที่จะได้ไพ่ที่เป็นหน้า J Q K และมีสีดำ?
- trial = การจั่วไพ่ 1 ใบจากสำรับ 52 ใบ
- sample space = ไพ่ 52 ใบ ที่มีความน่าจะเป็นที่จะได้แต่ละใบเท่าๆ กัน
- event = ไพ่ J, Q, K ที่มีสีดำ (ดอกจิก ไม่ก็โพธิ์ดำ) จึงมีที่ตรงตามต้องการแค่ 6 ใบ
- probability = 6/52 = 0.1154 =11.54%
หรือจะคำนวนอีกวิธีได้ว่า
เนื่องจากทั้งสองอัน independent กัน P(JQK ∩ ดำ) = P(JQK) x P(ดำ)
= 12/52 x 1/2 = 6/52 = 0.1154 =11.54%ตัวอย่าง 2 : จั่วไพ่ J Q K หรือไพ่สีดำ
ถ้าจั่วไพ่ออกมา 1 ใบจากสำรับ 52 ใบ จงหาโอกาสที่จะได้ไพ่ที่เป็นหน้า J Q K หรือไพ่สีดำ?
- trial = การจั่วไพ่ 1 ใบจากสำรับ 52 ใบ
- sample space = ไพ่ 52 ใบ ที่มีความน่าจะเป็นที่จะได้แต่ละใบเท่าๆ กัน
- event = ไพ่ J, Q, K 12 ใบ หรือ ไพ่ที่มีสีดำ 26 ใบ ก็ตรงตามต้องการ เนื่องจากทั้ง 2 เหตุการณ์มีส่วนซ้ำกันได้ทำให้ต้องหัก ไพ่ JQK ที่มีสีดำออก (มี6 ใบจากที่คิดในคำถามแรก) ทำให้เหลือไพ่ที่ตรงความต้องการ = 12+26-6 = 32 ใบ
- probability = 32/52 = 0.615
หรือจะคำนวนอีกวิธีได้ว่า
กัน P(JQK U ดำ) = P(JQK) + P(ดำ) – P(JQK ∩ ดำ)
= 12/52 + 26/52 – 6/52 = 0.615สิ่งที่ได้จากการเขียนความสัมพันธ์ Conditional Probability
P(E ∩ F) = P(E) × P(F|E)หลักการของ Conditional Probability ข้างบนนี้ไม่มีอะไรเลย จริงๆ มันก็คือการบอกว่า
ความน่าจะเป็นของการเกิดทั้งเหตุการณ์ E และ F ทั้งคู่
= ความน่าจะเป็นของเหตุการณ์ E * ความน่าจะเป็นของเหตุการณ์ F หลังจากเกิด E ขึ้นแล้ว
ซึ่งมันก็คือการใช้ Common Sense ทั่วไปนั่นแหละ จริงมะ?
แต่เรื่องของเรื่องคือ เมื่อเรานำมันมาจัดเรียงใหม่ นำมาดัดแปลงมุมมองเล็กน้อย เราจะได้ทฤษฎีที่ทรงพลังมากที่สุดอันนึงของเรื่อง Probability นั่นก็คือ Bayes’s Theorem นั่นเอง
Bayes’ Theorem
ก่อนที่ผมจะอธิบายว่า Bayes’ Theorem คืออะไร? ผมจะยกตัวอย่าโจทย์ปัญหาที่ Bayes’ Theorem สามารถช่วยหาคำตอบได้ง่ายกว่าการใช้ Common Sense ทั่วไป
สถานการณ์ คือ
มีโหล 2 โหล คือ โหล ก กับ ข แต่ละโหลใส่ลูกบอลสีแดงกับเขียวปนกัน
- โหล ก มี 4 ลูก โอกาสได้บอลแดง 50%
- โหล ข มี 10 ลูก โอกาสได้บอลแดง 30%
มีคนสลับโหลไปๆ มาๆ แล้วให้คุณหลับตาแล้วหยิบลูกบอลมั่วขึ้นมาลูกนึง ปรากฏว่าได้บอลสีแดง ถามว่าโอกาสที่คุณหยิบบอลมาจากโหล ข เป็นกี่ %
คุณคิดด้วย Common Sense ได้หรือไม่?? ถ้าคุณเริ่มงง ลองมาดูต่อ
การตีโจทย์ หากเราสามารถวาดรูปออกได้จะทำให้เข้าใจง่ายขึ้นเยอะ
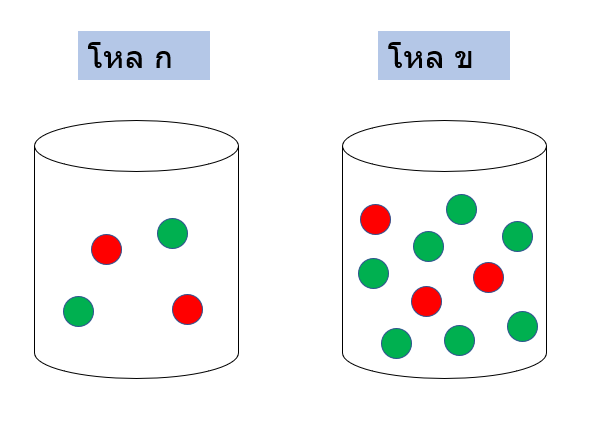
สิ่งที่ต้องการหา สามารถเขียนได้ในรูปของ Conditional Probability คือ P(หยิบจากโหล ข | ได้สีแดง) ซึ่งหายากกว่าในทิศกลับกันมาก นั่นคือ P(ได้สีแดง | หยิบจากโหล ข) ซึ่งรู้อยู่แล้วว่าคือ 30%
นี่แหละที่เจ้า Bayes’s Theorem เริ่มมีประโยชน์ในการเข้ามาช่วยครับ มันเจ๋งตรงที่มันใช้ความน่าจะเป็นในทิศกลับกันมาช่วยหาได้
ทฤษฎี
ทีนี้เรามาดูกันว่าเจ้า Bayes’s Theorem เค้าบอกว่ายังไง

ซึ่งจริงๆ แล้วเป็นสูตรที่ Make Sense มากๆ หากลอง พิจารณาจากความรู้เรื่อง Conditional Probability ที่ว่า
P(A ∩ B) = P(A) × P(B|A)
ดังนั้นสูตรข้างบนมันก็คือ
P(A | B) = P (A ∩ B) / P(B)หากพิจารณาจาก Venn Diagrams จะเข้าใจง่ายมาก ว่าทำไมสูตรถึงออกมาแบบนั้น
ซึ่งแปลว่า ความน่าจะเป็นของ A หลังจากเกิด B แล้ว เท่ากับ ความน่าจะเป็นของการเกิดทั้ง A และ B หารด้วย ความน่าจะเป็นของ B นั่นเอง

แก้โจทย์ปัญหา
P(หยิบจากโหล ข | ได้สีแดง) = P(ได้สีแดง | หยิบจากโหล ข) * P(หยิบจากโหล ข) / P (ได้สีแดง)
- P(ได้สีแดง | หยิบจากโหล ข) คือ 3/10 อันนี้ง่ายมาก
- P(หยิบจากโหล ข) = 10/14 เพราะมีบอลจากโหล ข 10 ลูก จากบอลทุกโหล 14 ลูก
- P(ได้สีแดง) = ถ้านับเอาเราจะได้ 5/14 ซึ่งง่ายๆ เนอะ
แต่ถ้าในความจริงเรานับชิ้นไม่ได้ เช่นโจทย์อาจบอกมาเป็น Portion แบบไม่ได้เป็นเลขดิบ ก็สามารถคิด P(ได้สีแดง) ได้อยู่ดี แต่เดี๋ยวไว้ดูแนวทางในตัวอย่างข้อหลังๆ นะ
สรุป : P(หยิบจากโหล ข | ได้สีแดง)
= (3/10) * (10/14) / (5/14) = ( 3/14 ) / (5/14) หรือ 3/5 นั่นเองซึ่งถ้าดูจากรูปนี่โคตร Make Sense เพราะจากสีแดงทั้งหมดที่มี 5 ลูก มันอยู่ที่ โหล ข 3 ลูก นั่นเอง!! (สูตรมันหมายความงี้เองเรอะ!)

ตัวอย่างโจทย์
ตัวอย่าง 1 : ผู้ติดเชื้อ Covid
จาก Data ของผู้ติดเชื้อ Covid-19 เมื่อวันที่ 13 มิย. 63 ผมลอง Pivot ข้อมูลออกมาได้ดังตาราง
| Count of no | Province | ||
| sex | กทม | ต่างจังหวัด | Grand Total |
| ชาย | 813 | 911 | 1724 |
| หญิง | 725 | 685 | 1410 |
| Grand Total | 1538 | 1596 | 3134 |
สมมติผมสุ่มคนออกมาคนนึงปรากฏว่าได้เป็นผู้ชาย จงหาความน่าจะเป็นที่คนคนนั้นจะเป็นคน กทม.
ถ้าเราเห็นเลขทุกตัวครบแล้ว จริงๆ มันง่ายมาก เพราะ P(กทม|ชาย) ก็คือ = 813/1724 = 47.16% ได้เลย (ก็ชายทั้งหมด 1724 คน เป็น กทม 813 คนไง)
แต่ถ้าจะใช้สูตรจาก Bayes ก็จะเป็นดังนี้
P(กทม|ชาย) = P(ชาย ∩ กทม) / P(ชาย)- P(ชาย ∩ กทม) = 813/3134
- P(ชาย) = 1724/3134
- P(กทม|ชาย) = 813/1724 นั่นเอง
หรือจะมองอีกแบบก็ยังได้
P(กทม|ชาย) = P(ชาย|กทม) * P(กทม) / P(ชาย)=(813/1538) * (1538/3134) / (1724/3134)
=813/1724 = 47.16% อยู่ดีถ้าเราได้ Data มาเป็น Portion ของ Grand Total แบบนี้ ก็สามารถคิดได้เช่นกัน
| Count of no | Province | ||
| sex | กทม | ต่างจังหวัด | Grand Total |
| ชาย | 25.94% | 29.07% | 55.01% |
| หญิง | 23.13% | 21.86% | 44.99% |
| Grand Total | 49.07% | 50.93% | 100.00% |
P(กทม|ชาย) = ภายในชาย ให้ดูเฉพาะ กทม.
= 25.94% / 55.01% = 47.16%ดังนั้นจะเห็นได้ว่าหากเราเห็นภาพของข้อมูลครบถ้วนด้วยตารางแบบนี้นะ ทุกอย่างมันจะง่ายขึ้นมากๆ เลย
ตัวอย่าง 2 : จั่วไพ่
ถ้าจั่วไพ่ออกมา 1 ใบจากสำรับ 52 ใบ แล้วเป็นสีดำ จงหาโอกาสที่มันจะเป็นไพ่ดอกจิก
- trial = การจั่วไพ่ 1 ใบจากสำรับ 52 ใบ
- sample space หลังจากการรู้ว่าเป็นสีดำ= ไพ่สีดำ มี 26 ใบ
- event = ได้ไพ่ดอกจิก
- probability = 13/26 = 0.5
หรือจะคำนวนอีกวิธีได้ว่า
P(ดอกจิก | ไพ่ดำ) = P(ดอกจิก ∩ ไพ่ดำ) / P(ไพ่ดำ)
= P(ดอกจิก) / P(ไพ่ดำ) = 0.25 / 0.5 = 0.5 = 50%ตัวอย่าง 3 : สาวสวยแปลงเพศ
สถานการณ์คือ คุณกับเพื่อนเดินไปเจอสาวสวยคนหนึ่ง ช่างเป็นสาวที่ตรง Spec ของคุณ จนอยากจะเข้าไปขอ ID Line เดี๋ยวนี้เลย แต่แล้วเพื่อนของคุณทักขึ้นมาว่า เดี๋ยวนี้ผู้หญิงสวยๆ อาจจะเป็นผู้ชายที่แปลงมาก็ได้… ตอนนี้คุณเริ่มลังเล และอยากจะหาความน่าจะเป็นที่สาวสวยที่คุณเจอจะเป็นผู้ชายแปลงเพศมา!
ความน่าจะเป็นที่คนที่คุณเจอจะเป็นผู้ชายแปลงเพศ เมื่อรู้แล้วว่าเป็นคนสวย สามารถเขียนได้ว่า = P(เจอผู้ชายแปลงเพศ|เจอคนสวย)
จาก Bayes จะได้ว่า
P(เจอผู้ชายแปลงเพศ|เจอคนสวย) = P(เจอคนสวย|เจอผู้ชายแปลงเพศ) * P(เจอผู้ชายแปลงเพศ) / P(เจอคนสวย)
สมองของคุณเริ่มเดาๆ ตัวเลขที่เกี่ยวข้องออกมาได้ ดังนี้ (เดาผิดอย่าว่ากัน assume ว่าไม่มีตัวเลขที่ดีกว่านี้แล้ว)
- โอกาสที่ผู้ชายแปลงเพศแล้วจะสวย = P(คนสวย|ผู้ชายแปลงเพศ) = 60%
- โอกาสที่จะเจอผู้ชายแปลงเพศ =P(ผู้ชายแปลงเพศ) = 5%
- โอกาสที่จะเดินเจอคนสวย = P(เจอคนสวย) = 20%
P(ผู้ชายแปลงเพศ|คนสวย) = 60% * 5% / 20% = 15% นั่นเองสรุปแล้ว คุณก็เลยตัดสินใจไปหาสาวสวยคนนั้น เพราะโอกาส 15% ก็ไม่ใช่น้อยๆ นะที่คุณจะได้เจอคนที่ตามหามานาน (อ้าว 555)
ตัวอย่าง 3 : ดักจับ Spam
อยากหาโอกาสที่ใน Email ที่ส่งมาจะเป็น Spam เมื่อเจอคำว่า Viagra อยู่ในข้อความ Email
นั่นคืออยากหา P(Spam|Viagra) ซึ่งเราเขียนสูตรได้ดังนี้
P(Spam|Viagra) = P(Viagra|Spam) * P(Spam) / P(Viagra)สมมติเราไปเก็บ Data มาแล้วได้ข้อมูลดังนี้
- โอกาสที่ข้อความที่รู้ว่าเป็น Spam จะมีคำว่า Viagra อยู่นั้นคือ 70%
- โอาสที่ข้อความที่รู้ว่าไม่ใช่ Spam จะมีคำว่า Viagra อยู่นั้นคือ 10%
- โอกาสที่จะเจอข้อความเป็น Spam =P(Spam) = 80%
P(Spam|Viagra) = 70%*80% / P(Viagra)แล้ว P(Viagra) จะหาได้ยังไง?
ถ้าวาดข้อมูลลงตารางและปรับฐานให้เท่ากันเป็น %of Grand Total ได้ จะทำให้เข้าใจง่ายขึ้นมากๆ
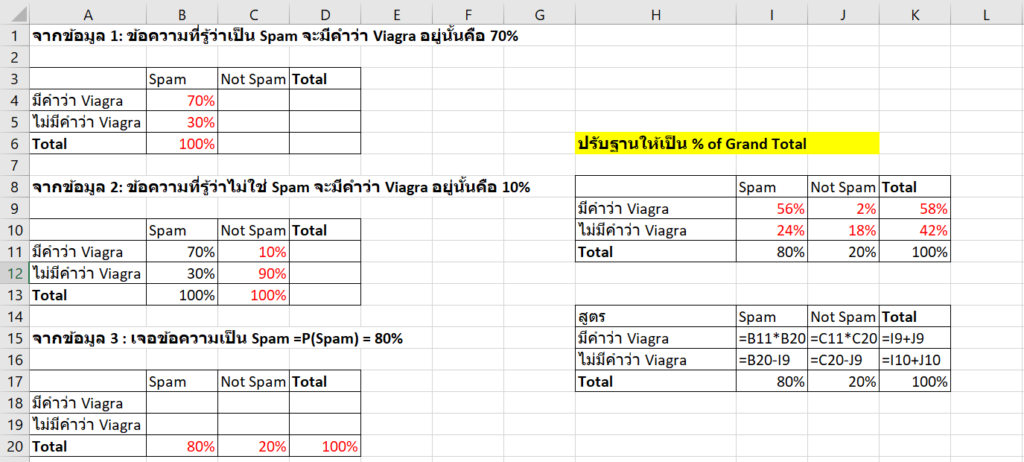
จริงๆ แล้วมันก็คือ ช่อง K10 จริงมะ ซึ่งคิดได้แบบนี้
P(Viagra) = P(Viagra|Spam) * P(Spam) + P(Viagra|Not Spam)*P(Not Spam)P(Viagra) = 70%*80% + 10%*(1-80%) = 58%สรุปแล้ว
P(Spam|Viagra) = 60%*80% / 58% = 82.7% นั่นเองและเรื่องแบบนี้แหละซึ่งเค้าเอาไปใช้ในการทำ Machine Learning เพื่อพัฒนา AI ที่ใช้ดัก Spam ด้วย แต่มันจะซับซ้อนกว่านี้เนอะ
แหล่งศึกษาความรู้เพิ่มเติม
- Math E-Book ( kanuay.com ) มีสรุปเนื้อหา math และแบบฝึกหัดให้โหลดฟรี
- https://www.youtube.com/results?search_query=probability
- เดี๋ยวมาเติมให้นะ
ตอนต่อไป
เป็นไงบ้างครับกับเนื้อหาความน่าจะเป็นที่ผมเตรียมไว้ให้ ผมพยายามเขียนให้เข้าใจง่ายที่สุดเท่าที่ทำได้แล้ว หวังว่าจะพอเข้าใจนะครับ แต่ถ้าไม่เข้าใจอะไรตรงไหนก็ Comment ถามมาได้เลยนะ
เดี๋ยวตอนต่อไปจะเป็นเรื่องของ Discrete Probability Distribution หรือการแจกแจงความน่าจะเป็นแบบที่เหตุการณ์ที่สนใจนั้นสามารถนับแยกเป็นชิ้นๆ ได้(ไม่ได้มีค่าต่อเนื่องกัน)