

ในตอนนี้เราจะเน้นเรื่องของ Normal Distribution ซึ่งเป็น Distribution ประเภท Continuous Probability Distribution ที่พบมากที่สุดในธรรมชาติเลย
แต่เราจะขอปูพื้นฐานเกี่ยวกับ Continuous Probability Distribution เบื้องต้นกันก่อนเล็กน้อยก่อนจะไปลงเรื่อง Normal Distribution กันจริงๆ ในครึ่งหลังของบทความ
Continuous Probability Distribution คือ การแจกแจงความน่าจะเป็นแบบที่เหตุการณ์ที่สนใจนั้นไม่สามารถนับเป็นชิ้นๆ ได้ เพราะเลขมีค่าต่อเนื่องกัน เช่น การแจกแจงของน้ำหนักของคนในบริษัท เพราะน้ำหนักของแต่ละคนมันอาจเป็น 63.43 kg ที่เป็นเศษแบบนี้ได้ ซึ่งเป็นค่าต่อเนื่อง ทำให้การอ่านความน่าจะเป็นของกราฟที่ Plot ออกมาต้องอ่านจาก “พื้นที่ใต้กราฟ” แทน ซึ่งมีอยู่หลายแบบด้วยกัน เช่น Uniform Distribution, Normal Distribution, T-Distribution, Chi-Square Distribution และอีกมากมาย
แต่ผมจะขอพูดถึง 2 แบบก่อน คือ Uniform Distribution และ Normal Distribution (รวมถึง แบบ Standard Normal ด้วย)
Uniform Distribution
Uniform แปลว่ามีแบบเดียวเหมือนกัน เช่น เครื่องแบบที่มีอันเดียว ดังนั้น Uniform Distribution ก็คือ Distribution ที่มีโอกาสเท่ากันหมดทุกค่านั่นเอง ถ้าลองทำเป็นกราฟจะเป็นแบบนี้

เนื่องจากพื้นที่ใต้กราฟต้องเป็น 1 เสมอ ทำให้
ความสูงของ distribution = 1/ ความกว้างซึ่งความกว้างก็แล้วแต่ว่าแกน x ของกราฟจะเริ่มจากเท่าไหร่ถึงเท่าไหร่ เช่น ถ้าเริ่มจาก 0 ถึง 1 แบบนี้ก็คือกว้าง 1 ทำให้สูง 1 ไปด้วย
ถ้าเริ่มตั้งแต่ 3 ถึง 5 แบบนี้กว้าง 2 ก็จะสูงแค่ =1/2 = 0.5 เพื่อให้พื้นที่ใต้กราฟเป็น 1 เสมอ เป็นต้น

ค่าที่สถิติของ Uniform Distribution ตั้งแต่ค่า x เป็น a ถึง b
- Mean = ค่าเฉลี่ยตรงกลาง = (a+b)/2
- Variance = 1/12 * (b-a)^2
ตัวอย่าง : หากเครื่องจักรของเราสามารถผลิตน้ำยาวิเศษได้วันละ 3-5 ลิตร โดย assume ว่าโอกาสของผลผลิตเป็น Uniform Distribution จงหาโอกาสที่จะผลิตได้ตั้งแต่ 3.5 ลิตร ขึ้นไป และ โอกาสที่จะผลิตได้ 3.5 ลิตรพอดีเป๊ะ
ความน่าจะเป็นนั้นสามารถคำนวณได้จากพื้นที่ใต้กราฟของส่วนที่สนใจ
ถ้าบอกว่าจะให้ผลิตได้ 3.5 ลิตรขึ้นไป ก็จะเป็นพื้นที่ส่วนที่ Highlight ในรูป

ดังนั้นโอกาสผลิตได้ตั้งแต่ 3.5 ลิตรขึ้นไป = (5-3.5) * 0.5 = 0.75 หรือ 75% นั่นเอง
และถ้าถามว่าโอกาสที่ได้ 3.50000000000 ลิตรพอดีเป๊ะๆๆๆๆๆๆๆ คือ เท่าไหร่? มันก็จะเป็นค่าที่น้อยมากกกกก (เข้าใกล้ 0) เนื่องจากความกว้างของสี่เหลี่ยมที่สนใจมันน้อยมากนั่นเอง
แต่ถ้าบอกว่าโอกาสที่ได้ตั้งแต่ 3.50-3.51 ลิตร แบบนี้ยังพอคำนวณได้ = (3.51-3.50)*0.5 = 0.005 = 0.5% นั่นเอง
สุ่มค่าจาก Uniform Distribution
ใน Excel เรามีฟังก์ชันที่สามารถสุ่มค่าจาก Uniform Distribution ที่เริ่มตั้งแต่ 0 ถึง 1 ได้โดยตรง นั่นคือ RAND นั่นเอง
=RAND()ผลลัพธ์จะออกมาเป็นค่าจำนวนจริงที่ละเอียดเป็นทศนิยม (แต่ excel รองรับ digit ทั้งหมดได้แค่ 15 digits) โดยมีค่าตั้งแต่ 0 ถึง 1
แต่ผลลัพธ์ออกมาแค่ 1 ค่า ถ้าอยากได้หลายค่าต้อง copy paste เอาเอง

- หากอยากจะ Random จาก Uniform Distribution ตั้งแต่ 0-2 ก็ใช้ RAND() *2 ได้
- หากอยากจะ Random จาก Uniform Distribution ตั้งแต่ 3-5 ก็ให้เลื่อนจาก 0-2 ไป 3 ค่า โดย RAND()*2 + 3 นั่นเอง
สรุปสูตรโดยทั่วไป ถ้าอยากจะ Random จาก a – b
=RAND()*(b-a) + a
อย่างไรก็ตามใน Excel 365 ที่รองรับ Dynamic Array สามารถใช้ฟังก์ชันใหม่ นั่นคือ RANDARRAY ได้ ซึ่งกำหนดให้ผลลัพธ์ออกมาหลายค่าได้เลย (ผลลัพธ์เป็น array) โดยกำหนดจำนวนแถว จำนวนคอลัมน์ค่ามากสุด น้อยสุด และกำหนดได้ว่าจะเอาเป็นจำนวนเต็มหรือไม่ก็ได้
=RANDARRAY(rows,columns,min,max,integer)
ใครอยากดูที่อธิบายแบบเป็นคลิปวีดีโอ ก็ดูได้ที่นี่
Normal Distribution
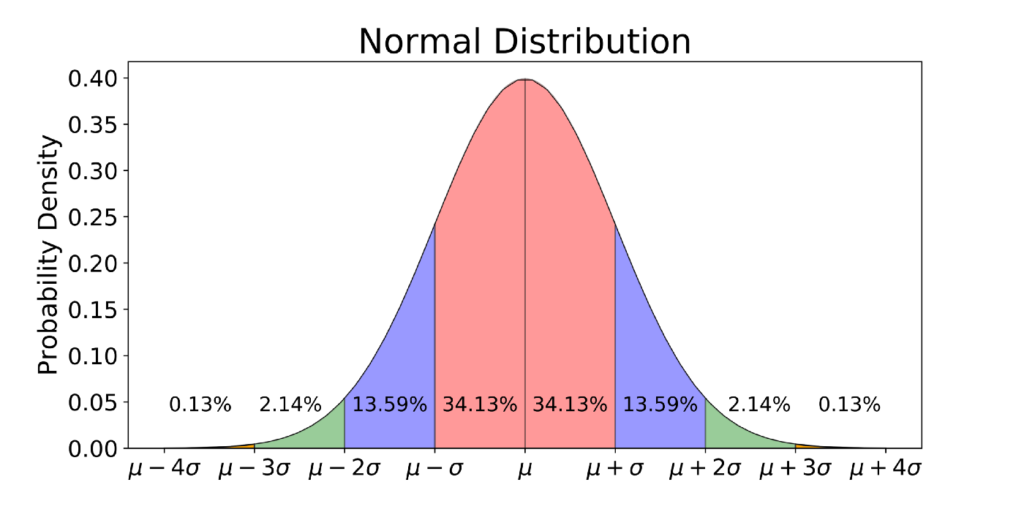
Normal Distribution มีอีกชื่อนึงว่า Gaussian distribution เป็น Distribution ที่พบมากที่สุดในธรรมชาติ (ก็เลยเรียกว่า Normal ไง) โดยมีลักษณะดังนี้
มีคุณสมบัติดังนี้
- กราฟของฟังก์ชั่นเป็นรูประฆังคว่ำ (ผมว่าชอบคิดว่ามันเหมือนภูเขามากกว่า 555 )
- มีจุดสูงสุดอยู่จุดเดียว (unimodal คือมี Mode เดียว ) ที่ x = µ
- มีลักษณะสมมาตรโดยมีสมการ x = µ เป็นแกนสมมาตร (แบ่งพื้นที่ฝั่งละ 50%)
- ค่า Mean = Median = Mode
- มีค่า x ตั้งแต่ – ∞ ถึง + ∞
- พื้นที่ใต้กราฟรวมกันทั้งหมด มีค่าเท่ากับ 1 (อันนี้เป็นจริงสำหรับกราฟ Continuous ทุกอันแหละ)
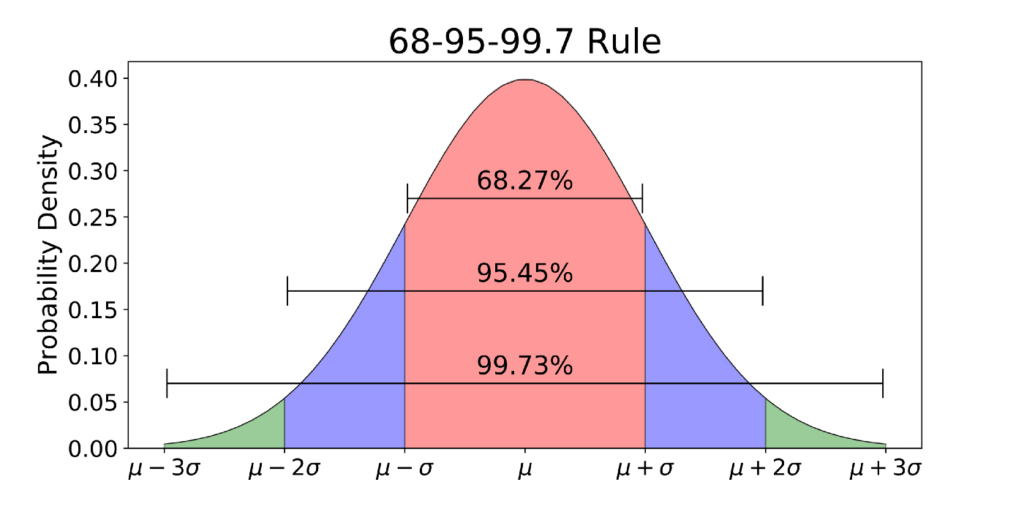
- หากเราขยายช่วงค่า x ออกมาจากแกนกลาง
- ข้างละ 1 sd จะกินพื้นที่รวมประมาณ = 68%
- ข้างละ 2 sd จะกินพื้นที่รวมประมาณ = 95%
- ข้างละ 3 sd จะกินพื้นที่รวมประมาณ = 99.7%
รูปร่างของ Normal Distribution จะขึ้นอยู่กับค่า Mean และ SD ของข้อมูล โดยที่ส่วนสูงสุดของภูเขาจะตรงกับค่า Mean ส่วนความกว้างของฐานจะขึ้นอยู่กับค่า SD โดยที่มักจะกินพื้นที่ไปถึงประมาณ Mean +- 3SD (แต่ในความเป็นจริงไปได้ถึง Infinity เลยนะ)
จะเห็นจากรูปว่ายิ่งฐานกว้าง ความสูงก็จะน้อยลง (เพราะพื้นที่ใต้กราฟต้องเป็น 100% เสมอไง )

ที่มาที่ไปของ Normal Distribution
จริงๆ แล้วถ้ายังจำ Binomial Distribution ในตอนที่แล้วได้ หากเราโยนเหรียญ 10 ครั้ง แล้ว Plot จำนวนครั้งที่ออกหัว จะได้ Distribution แบบนี้

ถ้าโยน 100 ครั้งล่ะ? ก็จะเห็นว่ากราฟมันหน้าตาเริ่มเป็นเส้นโค้งคล้ายๆ Normal ใช่มะ?

เรื่องของเรื่องคือ ไอ้ความน่าจะเป็นเนี่ย คนที่ให้ความสำคัญกับมันมากๆ ก็คือนักพนัน (เพราะเป็นความน่าจะเป็นที่เกี่ยวกับเรื่องเงินๆ ทองๆ โดยตรง) เค้าก็อยากจะให้นักคณิตศาสตร์ช่วยคำนวณความน่าจะเป็นให้ และจะให้คำนวณแบบ Binomial สำหรับจำนวนเยอะๆ ในสมัยที่ไม่มี Computer ก็ไม่ไหวหรอก ดังนั้นนักคณิตศาสตร์สมัยนั้นจึงคิดว่า ถ้าสามารถหาสมการที่อธิบายถึงเส้นโค้งของรูประฆังคว่ำที่เกิดขึ้นได้ ก็จะสามารถคำนวณความน่าจะเป็นของจำนวนที่เยอะมากๆ ได้ง่ายขึ้น
สุดท้ายคิดค้นไปมา ก็ได้ออกมาเป็นสูตรที่ดูแล้วโคตรน่ากลัวมากๆ ที่บอกว่า เส้นโค้งของ distribution ขึ้นกับค่า Mean และ SD (เพราะค่า Pi กับ e คือค่าคงที่) แบบนี้นั่นเอง

พอรู้ฟังก์ชันที่อธิบายเส้นโค้งของกราฟ Normal แล้วการจะหาพื้นที่ใต้กราฟก็สามารถทำได้ด้วยการคำนวณ Integrate นั่นเอง… (อ๊าก) แต่ถ้าจะให้คนธรรมดามานั่ง Integrate เอาก็คงยากเกินไป คนสมัยก่อนจึงพยายามทำให้กราฟเป็นมาตรฐานซึ่งเรียกว่า Standard Normal distribution แล้วสร้างตารางอ้างอิงสำเร็จรูปที่ได้คำนวณพื้นที่ใต้กราฟของจุดต่างๆ ไว้ให้แล้ว
Standard Normal Distribution
เราสามารถแปลงให้ กราฟ normal ที่มี µ (mean) และ σ (standard deviation) ใดๆ ก็ตามให้กลายเป็น การแจกแจงแบบปกติที่ µ (mean) = 0 และ σ = 1 และเปลี่ยนจากตัว x ให้กลายเป็นตัว z มันก็จะได้ผลลัพธ์เป็นกราฟ standard normal แทนครับ
โดยเราคำนวณค่า z ได้ดังนี้
z= (x-µ)/σ
คนสมัยก่อนก็เลยสามารถสร้างตารางอ้างอิงที่จะอธิบายได้ว่าค่า z แต่ละตัวเนี่ย มีความน่าจะเป็นเท่าไหร่บ้าง เช่น
ตัวอย่าง : สมมติการแจกแจงของคะแนนสอบปลายภาคของนักเรียนในโรงเรียนแจกแจงแบบ Normal โดยที่มี Mean = 60 SD =8 โดยที่ตัวเราได้คะแนน 70 ให้หาว่ามีนักเรียนกี่ % ที่คะแนนน้อยกว่าเรา
z = (x- mean / sd) = (70-60)/8
z = 1.25สมัยเด็กๆ เราต้องเปิดตารางเทียบแบบนี้

จะได้ว่าพื้นที่น้ำเงิน = 0.3944
แต่ว่าจะหาว่ามีกี่ % ที่ได้คะแนนน้อยกว่าเรา ต้องอย่าลืมบวกพื้นที่ใต้กราฟฝั่งซ้ายอีก 0.5 ด้วย
ดังนั้น % นักเรียนที่ได้คะแนนน้อยกว่าเรา = 0.3944+0.5 = 0.8944 = 89.44% นั่นเอง
ถ้าทำด้วย Excel
ในโจทย์เดียวกัน ถ้าทำด้วย Excel เราสามารถใช้ฟังก์ชัน NORM.DIST ได้เลยโดยไม่ต้องมาทำเป็น Standard Z ด้วยซ้ำ
=NORM.DIST(x,mean,standard_dev,cumulative)
=NORM.DIST(70,60,8,TRUE)
=0.89435 = 89.435% นั่นเองหรือจะใช้ NORMS.DIST เพื่อใช้ค่า z แทน x, mean, sd ก็ได้
=NORM.S.DIST(z,cumulative)
=NORM.S.DIST(1.25,TRUE)
=0.89435 = 89.435% เท่ากันเป๊ะนั่นแปลว่าถ้ามี Excel แล้วเราก็ไม่ต้องไปแปลงให้เป็น z ก็ได้ครับ ใช้ NORM.DIST ได้เลย 555
ในทางกลับกัน หากอยากรู้ว่า ความน่าจะเป็น 89.435% นั้น เมื่อมี Mean =60, SD =8 แล้ว เทียบเท่ากับ X เท่าใด ก็ใช้ NORM.INV ได้เลย ง่ายมากๆ (INV= Inverse แปลว่ากลับด้าน)
=NORM.INV(probability,mean,standard_dev)
=NORM.INV(0.89435,60,8)
=69.99999 หรือ 70 นั่นเองสุ่มค่าจาก Normal Distribution
เราสามารถใช้ความรู้ของ NORM.INV มาประยุกต์ได้ โดย Random probability ที่มีค่าได้ตั้งแต่ 0-1 ด้วย RAND() นั่นเอง
สรุป สามารถทำได้ด้วยวิธีนี้
=NORM.INV(probability,mean,standard_dev)
=NORM.INV(RAND(),mean,standard_dev)เช่นผมลองสุ่มดังรูป 500 ครั้ง ผลลัพธ์ออกมาค่อนข้างเป็น Normal สวยงามเลยล่ะ

ตัวอย่างเพิ่มเติม
ตัวอย่าง : ใครเทพกว่า

นายเอเรน สอบได้คะแนน 60 คะแนนในวิชาต่อสู้ด้วยมือเปล่า ส่วนแจนสอบได้ 65 คะแนนในวิชาบังคับเครื่องเคลื่อนย้ายสามมิติ ทำให้แจนมาข่มเอเรนว่าผลสอบห่วยกว่าตัวเอง อาร์มินเพื่อนอีกคนเห็นไม่อยากเห็นเพื่อนทะเลาะกัน เลยไปหาข้อมูลเพิ่มเติมมาว่า
- วิชาต่อสู้ด้วยมือเปล่า มีคะแนนเฉลี่ยอยู่ที่ 70 และมี SD ที่ 10
- วิชาบังคับเครื่องเคลื่อนย้ายสามมิติ มีคะแนนเฉลี่ยอยู่ที่ 80 และมี SD ที่ 15
อาร์มินเลยคิด Percentile ของคะแนนสอบเอเรน และแจน โดยใช้ NORM.DIST ดังนี้
=NORM.DIST(x,mean,standard_dev,cumulative)Percentile ของคะแนนสอบเอเรน
=NORM.DIST(60,70,10,TRUE)
=15.87%Percentile ของคะแนนสอบแจน
=NORM.DIST(65,80,15,TRUE)
=15.87%อาร์มินจึงสรุปให้ทั้งสองฟังได้ว่า ทั้งสองคนนั้นได้ Percentile เท่ากัน โดยที่กากเท่ากันทั้งคู่ ไม่ควรมาต้องทะเลาะกัน ดังนั้นเอเรนกับแจนจึงหยุดทะเลาะกัน (แล้วมาอัดอาร์มินแทน 555)
ตัวอย่าง : รู้แค่เลขขอบๆ ที่ 95%
สมมติน้ำหนักของพนักงานบริษัทจำนวน 95% อยู่ระหว่าง 50 kg และ 100 kg โดย assume ว่าเป็นการแจกแจงแบบ Normal Distribution ถ้าหากเรามีน้ำหนัก 70 kg จะหาว่าเราหนักเป็น Percentile ที่เท่าไหร่?
แบบนี้โจทย์ไม่ได้บอก Mean กับ SD มาตรงๆ แถมไม่ได้ให้ Data มาด้วย ดังนั้นต้องใช้ความรู้เรื่อง shape ของ normal มาช่วย
เรารู้ว่า Mean คือค่าที่อยู่ตรงกลางระหว่างขอบ 2 ตัว
- ดังนั้น Mean = AVERAGE(50,100) = 75 อันนี้ไม่ยากอะไร
SD นี่จะยากกว่า แต่ถ้าเอาแบบประมาณๆ ก็ยังง่าย เพราะเรารู้ว่า Normal Distribution พื้นที่ประมาณ 95% คือ Mean+- 2 SD ดังนั้น
- 75-2SD = 50
- SD = (75-50)/2 = 12.5
หา Probability ด้วย NORM.DIST
=NORM.DIST(x,mean,standard_dev,cumulative)
=NORM.DIST(70,75,12.5,TRUE)
=34.46% ซึ่งก็คือ Percentile ด้วยนั่นเองแต่ถ้าเอาแบบเป๊ะมากขึ้น (ซึ่งไม่รู้จะเป๊ะทำไม เพราะค่าพื้นที่ 95% ก็คงประมาณมา 555) หรือจำไม่ได้ว่าพื้นที่ 95% คือ Mean+กี่SD ก็ให้ใช้ NORM.S.INV มาช่วย
แต่เราจะใช้ NORM.S.INV(95%) ตรงๆ ก็ไม่ได้อีก เพราะมันจะสะสมตั้งแต่ 0 เราต้องพลิกแพลงเป็น 2.5% แทน เพื่อเอาค่า z ฝั่งซ้ายมา
=NORM.S.INV(2.5%) = -1.959963985 ซึ่งคือค่า z ซึ่งเป็นตัวที่บอกว่าเลื่อนไปกี่เท่าของ sd นั่นเอง
ดังนั้นข้อนี้เอาแบบเป๊ะๆ
SD = (75-50)/1.9599 = 12.7557 นะ
=NORM.DIST(70,75,12.7557,TRUE) = 34.75% นั่นเองตอนต่อไป
พอเรามีความรู้เกี่ยวกับกราฟ Normal Distribution แล้ว ตอนต่อไปเราจะมาทำความรู้จัก Central Limit Theorem ซึ่งเป็นทฤษฎีสุดเจ๋งเกี่ยวกับกับการสุ่มตัวอย่างกันในบทถัดไปครับ