


ใครเคยเห็น Code หน้าตาแบบ [A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,} แล้วช็อคบ้าง!? เพราะมันดูเหมือนมีแมวเดินบนคีย์บอร์ดมากกว่าจะเป็นโค้ด! ? 😂
เจ้านี่เรียกว่า Regex มันเป็นสิ่งที่เอาไว้หา Pattern ในข้อความ ซึ่งสามารถกำหนดเงื่อนไขได้ซับซ้อนได้ เช่น หา Email หรือเบอร์โทรศัพท์ที่ปนอยู่ในข้อความยาวๆ จนบางที Pattern ที่เขียนออกมานั้นน่ากลัวมากอย่างที่เห็น
ผมเคยพยายามจะเรียนรู้มัน แต่พอเห็นก็ท้อแล้ว คิดว่าคงไม่ค่อยได้ใช้เลยเลิกไป 😅 เพราะตอนสมัยก่อนนั้นมันมักใช้ในการเขียนโปรแกรมเป็นหลัก ไม่ได้ใช้ใน Excel
แต่ตอนนี้ Excel 365 และ Google Sheets ก็ต่างมีฟังก์ชัน Regex ให้ใช้กันครบแล้ว ผมก็เลยคิดว่าน่าจะต้องกลับมาเรียนรู้ใหม่…
พอตั้งใจเรียนรู้ไป… เฮ้ย! มันก็ไม่ยากเท่าที่คิดนี่นา? 😲
บทความนี้ผมจะพาเพื่อนๆ เริ่มจากศูนย์ ค่อยๆ เพิ่มความยากทีละขั้น เหมือนเล่นเกม RPG ไต่ Level
ไม่ต้องจำทั้งหมดในวันเดียวนะครับ แค่เข้าใจทีละส่วน แล้วมันจะค่อยๆ ลงตัวเอง
เดี๋ยวก่อน… ใช้ COPILOT ไม่ได้เหรอ?
พอพูดถึงการดึงข้อมูล หลายคนอาจจะถามว่า “ทำไมไม่ใช้ฟังก์ชัน COPILOT ล่ะ? มันก็ทำได้เหมือนกันนิ”
จริงครับ! ฟังก์ชัน =COPILOT() ใหม่ใน Excel สามารถทำอะไรได้หลายอย่าง:
=COPILOT("Extract the email from this text", A2)
=COPILOT("ดึงเบอร์โทรจากข้อความนี้", A2)มันเจ๋งมากครับ ใช้ภาษาธรรมชาติสั่งได้เลย ไม่ต้องจำ syntax อะไร
แต่… ผมลองใช้จริงแล้วเจอปัญหาหลายอย่าง จนต้องกลับมาหา Regex อยู่ดี ด้วยเหตุผลนี้ครับ
- มี Rate Limit : COPILOT function ต้องส่งข้อมูลไปให้ AI ประมวลผลบน Cloud ทุกครั้ง ซึ่งมันติด limit (ให้พยายามส่งเป็น array จะนับแค่ 1 call ซึ่งช่วยได้มาก)
- ผลลัพธ์ไม่แน่นอน (อันนี้เจ็บมาก) : LLM ทุกตัวสามารถให้ผลลัพธ์ที่ผิดพลาดได้ งานที่ต้องการความแม่นยำนี่จบเลยครับ 😭
- ต้องมี Internet + Copilot Subscription : COPILOT function ต้องใช้ Internet และ License สำหรับ Copilot features (เสียตังค์เพิ่มจาก Microsoft 365 ปกติ)
พูดตรงๆ นะครับ ผมใช้ COPILOT สำหรับงาน exploratory – ลองดูก่อนว่าข้อมูลมีอะไรบ้าง หรืองานที่ทำครั้งเดียวแล้วจบ ไม่กี่สิบแถว
แต่พอต้องทำจริงจัง ทำซ้ำหลายพันแถว หรือใส่ใน template ที่ใช้ทุกเดือน… Regex ดีกว่าเยอะครับ ไม่ต้องลุ้นว่า AI จะมีอารมณ์ยังไงวันนี้ 555
เอาล่ะ พอเข้าใจแล้วว่าทำไมต้องเรียน Regex บ้าง มาเริ่มกันเลย!
ความเห็นของผมเกี่ยวกับการเรียนรู้ RegEx ในยุค AI
ผมเชื่อว่า หากเราได้ลองเรียนรู้พื้นฐาน Regex ในบทความนี้แล้ว ในชีวิตจริงแม้เราสามารถสั่ง AI ให้ช่วยคิด Regex Pattern ได้ แต่ถ้ามันตอบมาแล้วเราอ่านไม่เข้าใจเลย เวลาเอาไปใช้งานจริงอาจจะผิดพลาดได้
.
แต่ถ้าเรามีความรู้พื้นฐานด้วย เราก็จะเข้าใจคำตอบของ AI ได้ง่ายขึ้นแล้ว ถ้าเราสงสัยก็ถามเพิ่มได้ อันนี้แหละวิธีการเรียนรู้ในยุคใหม่ที่แท้จริง
.
ซึ่ง Regex เป็น Skill ที่ใช้ได้ทุกที่นะ!
ไปเขียน Python, JavaScript, รวมถึง n8n หรือแม้แต่ใช้ VS Code หา text…
Regex ที่เรียนวันนี้ใช้ได้หมดเลย syntax เกือบเหมือนกัน 99%
ถือว่าลงทุนเรียนครั้งเดียว ใช้ได้ตลอดชีวิตการทำงานเลยครับ 😎
เรียนรู้ไว้เถอะ เชื่อผม อิอิ
ฟังก์ชัน Regex ใน Excel
Excel 365 มีฟังก์ชัน Regex ตรงๆ โดยเฉพาะ 3 ตัว ทำหน้าที่ต่างกัน:
- REGEXTEST – ตรวจว่ามี pattern นี้ไหม? ได้ TRUE/FALSE กลับมา (เช่น มี email ในข้อความไหม?)
- REGEXEXTRACT – ดึงส่วนที่ match ออกมาเลย (เช่น ดึง email ออกจากข้อความยาวๆ)
- REGEXREPLACE – หาแล้วแทนที่ (เช่น เปลี่ยนรูปแบบเบอร์โทร)
Syntax พื้นฐาน
=REGEXTEST(text, pattern, [case_sensitivity])
=REGEXEXTRACT(text, pattern, [return_mode], [case_sensitivity])
=REGEXREPLACE(text, pattern, replacement, [occurrence], [case_sensitivity])case_sensitivity: 0 = ตัวพิมพ์เล็ก/ใหญ่ต่างกัน (default), 1 = ไม่สนใจ
return_mode (สำหรับ REGEXEXTRACT):
- 0 = ผลลัพธ์แรก (default)
- 1 = ทุกผลลัพธ์ (เป็น array)
- 2 = ดึงแต่ละ group ออกมา (จะอธิบายทีหลังครับ)
ฟังก์ชันพวกนี้ใช้ PCRE2 flavor ของ Regex ซึ่งเป็นมาตรฐานที่ใช้กันแพร่หลาย ถ้าไปหาตัวอย่างในเน็ตก็ใช้ได้เลยส่วนใหญ่
ฟังก์ชันอื่นที่รองรับ Regex Mode
นอกจาก 3 ฟังก์ชันหลักแล้ว ยังมีฟังก์ชันอื่นที่รองรับ Regex Mode ผ่าน parameter พิเศษ:
| ฟังก์ชัน | วิธีใช้ Regex | ตัวอย่าง |
|---|---|---|
| XLOOKUP | ใช้ match_mode = 3 | =XLOOKUP("pattern",A:A,B:B,,3) |
| XMATCH | ใช้ match_mode = 3 | =XMATCH("pattern",A:A,3) |
match_mode parameter ของ XLOOKUP และ XMATCH:
- 0 = exact match (default)
- -1 = exact match หรือค่าที่เล็กกว่าถัดไป
- 1 = exact match หรือค่าที่ใหญ่กว่าถัดไป
- 2 = wildcard match (ใช้
*และ?) - 3 = regex match ✨ ใหม่!
ตัวอย่าง: XLOOKUP กับ Regex
สมมติมีข้อมูลประเทศที่เขียนไม่เหมือนกัน บ้างก็ “USA” บ้างก็ “United States” เราใช้ | (หรือ) ใน regex ได้เลย:
=XLOOKUP("USA|United States", A2:A100, B2:B100, , 3)หรือหารหัสสินค้าที่ขึ้นต้นด้วยตัวอักษร 3 ตัว ตามด้วยเลข:
=XLOOKUP("^[A-Z]{3}[0-9]+", A2:A100, B2:B100, , 3)ตัวอย่าง: XMATCH กับ Regex
หาตำแหน่งแถวที่มีเบอร์โทรในคอลัมน์ A:
=XMATCH("\d{10}", A2:A100, 3)หมายเหตุสำคัญ:
- Regex ใน XLOOKUP/XMATCH เป็น case-sensitive โดย default ถ้าอยากไม่สนใจตัวพิมพ์เล็ก/ใหญ่ ให้เติม
(?i)หน้า pattern เช่น(?i)usa|united states - Regex จะ match กับ ส่วนใดก็ได้ ของ cell ถ้าต้องการ match ทั้ง cell ให้ใช้
^และ$ครอบ เช่น^ABC123$
สรุปฟังก์ชันที่ใช้ Regex ได้ใน Excel 365
| ฟังก์ชัน | หน้าที่ | รองรับ Regex |
|---|---|---|
| REGEXTEST | ตรวจว่า match ไหม | ✅ (หลัก) |
| REGEXEXTRACT | ดึงข้อความที่ match | ✅ (หลัก) |
| REGEXREPLACE | หาแล้วแทนที่ | ✅ (หลัก) |
| XLOOKUP | ค้นหาและคืนค่า | ✅ (match_mode=3) |
| XMATCH | หาตำแหน่งใน array | ✅ (match_mode=3) |
| SUMIF/COUNTIF | นับ/รวมตามเงื่อนไข | ❌ (ใช้ได้แค่ wildcard) |
| FILTER | กรองข้อมูล | ❌ (ใช้ร่วมกับ REGEXTEST ได้) |
เคล็ดลับ: ถ้าต้องการใช้ Regex กับ FILTER ให้ใช้ร่วมกับ REGEXTEST แบบนี้:
=FILTER(A2:B100, REGEXTEST(A2:A100, "\d{10}"))สูตรนี้จะกรองเอาเฉพาะแถวที่คอลัมน์ A มีเลข 10 หลัก (เบอร์โทร)
เริ่มต้นการผจญภัย: 8 Levels สู่การเข้าใจ Regex
ผมจะพาเพื่อนๆ ไต่ Level ทีละขั้น เหมือนเล่นเกม RPG 🎮
- Level 1-3: พื้นฐานที่ใช้ได้เลย – แค่นี้ก็ทำงานได้ 70% แล้ว
- Level 4-6: เริ่มเข้าใจลึกขึ้น – ทำให้ pattern สั้นลง แม่นยำขึ้น
- Level 7-8: ขั้นสูง – Greedy/Lazy และ Lookahead
ไม่ต้องอ่านจบในวันเดียวนะครับ อ่าน Level 1-3 แล้วลองใช้จริงก่อนก็ได้ พอติดปัญหาค่อยกลับมาอ่านต่อ
พร้อมแล้วก็ไปกันเลย!
Level 1: หาคำตรงๆ (Literal Match)
เริ่มจากง่ายที่สุดก่อนเลยครับ – หาคำที่เขียนตรงๆ
=REGEXTEST(A2, "Excel")ถ้า A2 มีคำว่า “Excel” อยู่ → TRUE
=REGEXEXTRACT("ติดต่อ: sira@thepexcel.com", "thepexcel")ผลลัพธ์: thepexcel
ตอนนี้ยังไม่ต่างจาก FIND หรือ SEARCH เท่าไหร่หรอกครับ แต่เดี๋ยว Level ถัดไปจะเริ่มเห็นพลัง 😎
Level 2: กลุ่มตัวอักษร (Character Classes)
ที่เจ๋งคือ เราสามารถบอกได้ว่า “ตัวอักษรตรงนี้ เป็นอะไรก็ได้ในกลุ่มนี้”
ใช้ [ ] ครอบกลุ่มตัวอักษรที่ต้องการ
ตัวอย่างที่ใช้บ่อย:
[0-9]= ตัวเลข 0 ถึง 9 ตัวใดก็ได้[a-z]= ตัวอักษรเล็ก a ถึง z[A-Z]= ตัวอักษรใหญ่ A ถึง Z[A-Za-z]= ตัวอักษรอะไรก็ได้ ไม่สนใจเล็กใหญ่[aeiou]= สระภาษาอังกฤษ[^0-9]= ไม่ใช่ตัวเลข (เครื่องหมาย ^ ข้างใน [] แปลว่า “ยกเว้น”)
ลองดูตัวอย่าง
ตรวจว่ามีตัวเลขในข้อความไหม:
=REGEXTEST("ABC123", "[0-9]") → TRUE
=REGEXTEST("ABCDEF", "[0-9]") → FALSEดึงตัวอักษรตัวแรกที่เป็นตัวใหญ่:
=REGEXEXTRACT("dylanWilliams", "[A-Z]") → "W"วิธีจำ: ลองนึกภาพว่า [0-9] คือ “ช่องว่าง” ที่มีป้ายเขียนว่า “ใส่เลขได้” เหมือนแบบฟอร์มที่มีช่องให้กรอก แต่ละช่องบอกว่ากรอกอะไรได้บ้าง
Level 3: บอกจำนวน (Quantifiers)
Level ที่แล้วหาได้ทีละตัว ถ้าอยากหาหลายตัวล่ะ?
สมมติอยากดึงเบอร์โทรจากข้อความ “โทร 0891234567 ด่วน” ถ้าเขียน [0-9] จะได้แค่ 0 ตัวเดียว! 😅
=REGEXEXTRACT("โทร 0891234567 ด่วน", "[0-9]") → "0" (ได้แค่ตัวเดียว!)ถ้าไม่มี Quantifiers เราต้องเขียนแบบนี้:
[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]😭 นับดีๆ นะ 10 ตัว… ใครจะไปนั่งเขียนแบบนี้ทุกครั้ง!
แต่ถ้ามี Quantifiers เขียนแค่นี้จบ
[0-9]{10}นี่แหละประโยชน์ที่ Quantifiers เข้ามาช่วย
Quantifiers บอกว่า “ตัวก่อนหน้านี้ ต้องมีกี่ตัว”
+= 1 ตัวขึ้นไป (ต้องมีอย่างน้อย 1)*= 0 ตัวขึ้นไป (จะไม่มีก็ได้)?= 0 หรือ 1 ตัว (มีหรือไม่มีก็ได้){3}= ตรงๆ 3 ตัวเป๊ะ{2,4}= 2 ถึง 4 ตัว{2,}= 2 ตัวขึ้นไป
⚠️ ระวังสับสน: เดี๋ยวเราจะได้เรียนรู้ว่า . = อะไรก็ได้ 1 ตัว (ยกเว้นขึ้นบรรทัดใหม่ อันนี้ไม่ใช่ quantifier นะ)
ดังนั้นถ้าเทียบกับ Wildcard ของ Excel จะได้แบบนี้:
| Wildcard (Excel เดิม) | Regex |
|---|---|
? = อะไรก็ได้ 1 ตัว | . = อะไรก็ได้ 1 ตัว |
* = อะไรก็ได้กี่ตัวก็ได้ | .* = อะไรก็ได้กี่ตัวก็ได้ |
ใน Wildcard ของ Excel (ที่ใช้กับ COUNTIF, SUMIF, VLOOKUP พวกนั้น) ? หมายถึง “ตัวอักษรอะไรก็ได้ 1 ตัว” แต่ใน Regex ? หมายถึง “มีหรือไม่มีก็ได้” ซึ่งต่างกันเลย!
ตัวอย่าง: ดึงเลขทั้งหมดออกมา

=REGEXEXTRACT("สินค้า ABC-12345 555", "[0-9]+") → "12345" เจอแค่ตัวแรก=REGEXEXTRACT("สินค้า ABC-12345 555", "[0-9]+",1) → {"12345","555"}ใส่ Return Mode เป็น 1 เพื่อเอาทุกผลลัพธ์ที่ Match เจอออกมาเป็น array
ตัวอย่าง: ดึงรหัสสินค้า 2 ตัวอักษร + 4 ตัวเลข
=REGEXEXTRACT("Order: XY1234 shipped", "[A-Z]{2}[0-9]{4}") → "XY1234"วิธีจำ: Quantifier คือ “ป้ายบอกจำนวน” ติดท้ายช่อง
[0-9]= ช่องใส่เลข 1 ช่อง[0-9]+= ช่องใส่เลข ต้องมีอย่างน้อย 1 ช่อง จะมีกี่ช่องก็ได้[0-9]{4}= ช่องใส่เลขพอดี 4 ช่อง
Level 4: ตัวแทนพิเศษ (Special Characters)
พิมพ์ [0-9] บ่อยๆ ก็เมื่อยครับ 555 Regex เลยมี shortcut ให้!
\d= ตัวเลข (digit) เท่ากับ[0-9]\D= ไม่ใช่ตัวเลข\w= ตัวอักษร/เลข/underscore (word) เท่ากับ[A-Za-z0-9_]\W= ไม่ใช่ word character\s= ช่องว่าง/tab/ขึ้นบรรทัดใหม่ (space)\S= ไม่ใช่ช่องว่าง.= อะไรก็ได้ 1 ตัว (ยกเว้นขึ้นบรรทัดใหม่)
💡 ทำไมต้องมี \ ข้างหน้า?
Backslash (\) ใน Regex ทำงาน 2 แบบ:
- เปิดพลังพิเศษ:
dเป็นแค่ตัว d ธรรมดา แต่\dแปลว่า “ตัวเลขอะไรก็ได้” - ปิดพลังพิเศษ:
.แปลว่า “อะไรก็ได้” แต่\.แปลว่า “จุดจริงๆ”
ลองนึกว่า \ คือสวิตช์เปิด/ปิดความหมายพิเศษ ถ้าตัวนั้นปกติไม่มีพลัง → \ เปิดพลัง ถ้าตัวนั้นมีพลังอยู่แล้ว → \ ปิดพลัง
ตัวอย่าง: ดึงเลข 10 หลัก (เบอร์โทร)
=REGEXEXTRACT("โทร 0891234567 ด่วน", "\d{10}") → "0891234567"สั้นกว่าเขียน [0-9]{10} มากเลยใช่มั้ยครับ 😎
ที่ต้องระวังคือ: Escape Special Characters
ถ้าอยากหาจุด . จริงๆ (ไม่ใช่ “อะไรก็ได้”) ต้องใส่ \ ข้างหน้า
# หา .com
=REGEXTEST("google.com", "\.com") → TRUE
# ถ้าไม่ escape
=REGEXTEST("googleXcom", ".com") → TRUE (ผิด! เพราะ . แปลว่าอะไรก็ได้)ตัวที่ต้อง escape: . * + ? ^ $ { } [ ] \ | ( )
ผมก็จำไม่ได้หมดหรอกนะ 555 ถ้าไม่แน่ใจก็ใส่ \ ไปก่อนเลย หรือใช้ Regex101 ช่วยเช็ค ซึ่งเดี๋ยวจะแนะนำตอนท้าย
Level 5: จุดเริ่มและจุดจบ (Anchors)
บางทีเราอยากระบุว่า “ต้องอยู่ตรงนี้เท่านั้น”
^= จุดเริ่มต้นของข้อความ$= จุดจบของข้อความ\b= ขอบของคำ (word boundary)
ตัวอย่าง: ต้องขึ้นต้นด้วยตัวเลข
=REGEXTEST("123ABC", "^\d") → TRUE
=REGEXTEST("ABC123", "^\d") → FALSEตัวอย่าง: ต้องลงท้ายด้วย .xlsx
=REGEXTEST("report.xlsx", "\.xlsx$") → TRUE
=REGEXTEST("report.xlsx.bak", "\.xlsx$") → FALSEตัวอย่าง: หาคำ “cat” แบบไม่ติดคำอื่น
อันนี้ใช้บ่อยมากครับ เพราะบางทีเราไม่ได้อยากได้ “category” ด้วย
=REGEXTEST("category", "\bcat\b") → FALSE (cat อยู่ในคำ category)
=REGEXTEST("my cat is cute", "\bcat\b") → TRUE💡 ทำไมไม่ใช้ \s แทน \b?
ถ้าเขียน \scat\s (มี space ล้อมรอบ) จะมีปัญหา:
"cat is cute"→ ❌ ไม่ match เพราะไม่มี space ก่อน cat (อยู่ต้นข้อความ)"my cat"→ ❌ ไม่ match เพราะไม่มี space หลัง cat (อยู่ท้ายข้อความ)"my cat, dog"→ ❌ ไม่ match เพราะหลัง cat เป็น comma ไม่ใช่ space
\b ฉลาดกว่า – มันหมายถึง “ขอบระหว่างตัวอักษรกับสิ่งที่ไม่ใช่ตัวอักษร” ไม่ว่าจะเป็น space, comma, จุด, หรือแม้แต่ต้น/ท้ายข้อความ
💡 ใช้ ^ กับ $ ด้วยกันได้ไหม?
ได้ครับ! และมันเป็น AND logic – ทั้งสองเงื่อนไขต้องเป็นจริง
^\d{5}$ = ข้อความทั้งหมดต้องเป็นตัวเลข 5 หลักพอดี| ข้อความ | \d{5} | ^\d{5}$ |
|---|---|---|
"12345" | ✅ TRUE | ✅ TRUE |
"รหัส 12345" | ✅ TRUE (เจอ 12345) | ❌ FALSE (ไม่ได้ขึ้นต้นด้วยเลข) |
"123456" | ✅ TRUE (เจอ 12345) | ❌ FALSE (มี 6 หลัก ไม่ใช่ 5) |
เหมาะมากสำหรับ validation – เช็คว่าข้อมูลทั้งหมดตรงตาม format ไหม เช่น รหัสไปรษณีย์ต้องเป็นเลข 5 หลักเท่านั้น ไม่ใช่แค่ “มีเลข 5 หลักอยู่ในนั้น”
Level 6: จัดกลุ่มและเลือก (Groups & Alternation)
Level นี้เริ่มยากขึ้นหน่อยแล้วนะครับ แต่พอเข้าใจแล้วจะใช้บ่อยมากกกก
Groups: ใช้ ( ) จัดกลุ่ม
Groups มีประโยชน์ 2 อย่าง:
1. ใช้ quantifier กับกลุ่ม
# หาคำว่า "na" ซ้ำหลายครั้ง
=REGEXTEST("banana", "(na)+") → TRUE2. ดึงเฉพาะส่วนที่ต้องการ (return_mode = 2)
นี่คืออันที่ผมบอกไว้ตอนแรกครับ – ใช้ () ครอบส่วนที่อยากดึง แล้วใส่ return_mode = 2
# ข้อมูล: "John Smith"
# อยากได้: ชื่อกับนามสกุลแยกกัน
=REGEXEXTRACT("John Smith", "(\w+)\s(\w+)", 2)
→ ได้ array: ["John", "Smith"] (spill ออกมา 2 เซลล์!)ตัวอย่างที่ผมใช้บ่อยมากกก:
# แยกวัน/เดือน/ปี จาก "25/12/2024"
=REGEXEXTRACT("25/12/2024", "(\d+)/(\d+)/(\d+)", 2)
→ ได้ array: [25, 12, 2024]
# ถ้าไม่ใส่ () จะเป็นยังไง?
=REGEXEXTRACT("25/12/2024", "\d+/\d+/\d+")
→ ได้: "25/12/2024" (ได้ทั้งก้อน ไม่แยก!)
# ดึง area code จากเบอร์โทร "(02) 123-4567"
=REGEXEXTRACT("(02) 123-4567", "\((\d+)\)", 2)
→ ได้: "02"ที่เจ๋งคือ ผลลัพธ์จะ spill ออกมาเป็น array เลย เอาไปใช้ต่อกับสูตรอื่นได้ทันที ไม่ต้องมานั่งแยกทีละอันเอง
Alternation: ใช้ | แปลว่า “หรือ”
# หา jpg หรือ png หรือ gif
=REGEXTEST("photo.png", "\.(jpg|png|gif)$") → TRUE
# หา http หรือ https
=REGEXTEST("https://example.com", "^https?://") → TRUELevel 7: Greedy vs Lazy (โลภ vs ขี้เกียจ)
อันนี้สำคัญมากกกครับ ถ้าไม่เข้าใจจะงงว่า “ทำไม pattern ดึงมาเยอะกว่าที่คิด?”
ปัญหา: Greedy (โลภ)
สมมติมีข้อมูล HTML: Hello and World
อยากดึงแค่ Hello ออกมา:
=REGEXEXTRACT(A2, "<b>.*</b>")
→ ได้: "<b>Hello</b> and <b>World</b>" ← เฮ้ย ได้ทั้งหมดเลย!ทำไมถึงเป็นแบบนี้? เพราะ .* มันโลภมาก – มันจะกินให้ได้มากที่สุดเท่าที่ยังคง match อยู่
<b>Hello</b> and <b>World</b>
←────────── .* กินทั้งหมดนี่ ──────────→วิธีแก้: Lazy (ขี้เกียจ)
ใส่ ? ต่อท้าย * หรือ + เพื่อบอกว่า “เอาแค่น้อยที่สุดที่พอ match ได้”
=REGEXEXTRACT(A2, "<b>.*?</b>")
→ ได้: "<b>Hello</b>" ← ถูกต้อง!<b>Hello</b> and <b>World</b>
←──── .*? หยุดตรงนี้พอ ────→สรุป
| Quantifier | ชื่อ | พฤติกรรม |
|---|---|---|
* | Greedy | กินให้มากที่สุด |
*? | Lazy | กินให้น้อยที่สุด |
+ | Greedy | กินให้มากที่สุด (อย่างน้อย 1) |
+? | Lazy | กินให้น้อยที่สุด (อย่างน้อย 1) |
วิธีจำ: ใส่ ? ต่อท้าย quantifier = ขี้เกียจ ไม่อยากทำมาก หยุดเร็วที่สุดที่ทำได้ 😅
Level 8: Lookahead (มองไปข้างหน้า)
บางทีเราอยาก match ตัวอักษร “ที่มีอะไรบางอย่างตามหลัง” แต่ไม่อยากรวมสิ่งที่ตามหลังในผลลัพธ์
Syntax
(?=...)= Positive Lookahead – ต้องมี … ตามหลัง (แต่ไม่รวมในผลลัพธ์)(?!...)= Negative Lookahead – ต้องไม่มี … ตามหลัง
ตัวอย่าง: ซ่อนเลขบัตรเครดิต
อยากแทนเลขทุกตัว ยกเว้น 4 ตัวท้าย:
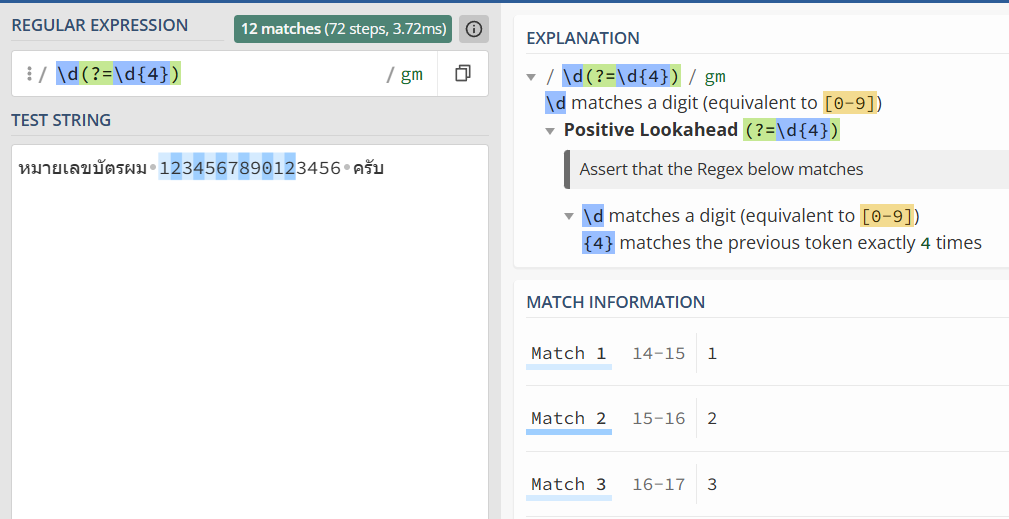
=REGEXREPLACE("หมายเลขบัตรผม 1234567890123456 ครับ", "\d(?=\d{4})", "*")
→ ได้: "หมายเลขบัตรผม ************3456 ครับ"แปล: จับตัวเลข \d ที่มีเลขอีก 4 ตัวตามหลัง (?=\d{4}) แล้วแทนด้วย *
หมายเลขบัตรผม 1234567890123456 ครับ
ห → ไม่ใช่ \d → ข้าม
ม → ไม่ใช่ \d → ข้าม
า → ไม่ใช่ \d → ข้าม
ย → ไม่ใช่ \d → ข้าม
...
(รวมถึงเว้นวรรคด้วย)
↑ เลข "1" มีตัวเลขติดกันอย่างน้อย 4 ตัว (มากกว่านี้ก็ได้) → จับ! แทนด้วย *
...
↑ เลข "2" (ตัวที่ 12) มีเลขตามหลัง 4 ตัวพอดี → จับ! แทนด้วย *
↑ เลข "3" (ตัวที่ 13) มีเลขตามหลังแค่ 3 ตัว → ไม่จับ!4 ตัวท้ายรอด เพราะมันมีเลขตามหลังไม่ถึง 4 ตัว 😎
ลองเช็คด้วยเว็บ https://regex101.com/ ดู อาจจะเข้าใจง่ายขึ้น ว่าทำไมส่วนนั้นถึงถูกแทนที่ด้วย * จากการสั่ง replace
ตัวอย่าง: หาราคาที่ตามด้วย “บาท”
=REGEXEXTRACT("ราคา 599 บาท รวม VAT 42 บาท", "\d+(?= บาท)", 1)
→ ได้ array: ["599", "42"]แปล: จับตัวเลข \d+ ที่มี ” บาท” ตามหลัง แต่ไม่รวม ” บาท” ในผลลัพธ์
ตัวอย่าง: Negative Lookahead
หาตัวเลขที่ไม่ตามด้วย “px”:
=REGEXEXTRACT("width: 100px, height: 50, margin: 20px", "\d+(?!px)", 1)
→ ได้: "50" (เพราะ 100 และ 20 ตามด้วย px)💡 เมื่อไหร่ใช้ Lookahead?
- อยาก match บางอย่าง “ที่มีบริบทแบบนี้” แต่ไม่อยากรวมบริบทในผลลัพธ์
- ตัวอย่างใช้จริง: ซ่อนข้อมูลบางส่วน, ดึงตัวเลขที่ตามด้วยหน่วยเฉพาะ, validate password ที่ต้องมีตัวใหญ่และตัวเลข
สูตรสำเร็จสำหรับงานจริง
ส่วนตัวผมใช้ pattern พวกนี้บ่อยมากกก เลยรวบรวมไว้ให้ copy ไปใช้ได้เลย
ผมก็ยังไม่ได้จำได้ทั้งหมดหรอกนะ มาเปิดดูเอาทุกครั้ง 555
ดึง Email
=REGEXEXTRACT(A2, "[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}")อันนี้ครอบคลุม email ส่วนใหญ่ แต่ก็ไม่ได้ 100% นะครับ email มันมี edge case เยอะมาก ถ้าต้องการ strict มากๆ อาจต้องหา pattern ที่ยาวกว่านี้ ซึ่งผมก็ไม่รู้เหมือนกันว่ามันหน้าตายังไง 😅
ดึงเบอร์โทรไทย (10 หลัก)
=REGEXEXTRACT(A2, "0\d{9}")หรือถ้ามีหลายรูปแบบ (มี – หรือ space ปน):
=REGEXEXTRACT(A2, "0\d[\d\s\-]{7,12}\d")ดึงวันที่ DD/MM/YYYY
=REGEXEXTRACT(A2, "\d{1,2}/\d{1,2}/\d{4}")ทำความสะอาดเบอร์โทร (ลบ -, ช่องว่าง, วงเล็บ)
=REGEXREPLACE(A2, "[^\d]", "")อันนี้เจ๋งมากครับ – [^\d] แปลว่า “อะไรก็ตามที่ไม่ใช่ตัวเลข” แล้วแทนที่ด้วย "" (ว่าง) เหลือแต่ตัวเลขล้วนๆ
ซ่อนเลขบัตรเครดิต (เหลือ 4 ตัวท้าย)
=REGEXREPLACE(A2, "\d(?=\d{4})", "*")ผลลัพธ์: 1234567890123456 → ************3456
(ใช้ Lookahead – ดูคำอธิบายละเอียดใน Level 8)
ดึงตัวเลขแรกจากข้อความ
=VALUE(REGEXEXTRACT(A2, "\d+"))หมายเหตุ: REGEXEXTRACT คืนค่าเป็น text เสมอ ใช้ VALUE() ครอบเพื่อแปลงเป็นตัวเลขถ้าจะเอาไปคำนวณต่อ
ตรวจรหัสไปรษณีย์ไทย (5 หลัก)
=REGEXTEST(A2, "^\d{5}$")ข้อผิดพลาดที่พบบ่อย
กว่าผมจะเข้าใจ Regex ได้ ก็ต้องเจ็บตัวมาหลายรอบครับ 😅 เลยเอามาเตือนไว้
ใช้ Greedy แทน Lazy
ดึงข้อมูลมาเยอะกว่าที่ต้องการ → ดูวิธีแก้ใน Level 7: Greedy vs Lazy
ลืม Escape ตัวพิเศษ
# อยากหา 3.14
=REGEXTEST("3.14", "3.14")
# match "3X14" ด้วย! เพราะ . แปลว่าอะไรก็ได้
# แก้:
=REGEXTEST("3.14", "3\.14")ไม่ใช้ Word Boundary
# อยากหาคำว่า "cat"
=REGEXTEST("category", "cat") → TRUE ← ไม่ใช่สิ่งที่ต้องการ
# แก้:
=REGEXTEST("category", "\bcat\b") → FALSEPattern ซับซ้อนเกินไป
ถ้า pattern ยาวมากกกก จนอ่านไม่ออกเลย… บางทีอาจจะใช้ผิดเครื่องมือแล้ว
ลองแยกทำหลายขั้นตอน หรือใช้ Power Query แทน บางทีมันเหมาะกว่า ไม่ต้องฝืนใช้ Regex ทุกอย่าง (หรือจะใช้ AI LLM ช่วยเลยก็ได้)
Cheat Sheet
ตารางอ้างอิงด่วน
| หมวด | Pattern | ความหมาย |
|---|---|---|
| ตัวอักษร | \d | ตัวเลข [0-9] |
\w | ตัวอักษร/เลข/_ | |
\s | ช่องว่าง | |
. | อะไรก็ได้ 1 ตัว | |
| จำนวน | + | 1 ขึ้นไป |
* | 0 ขึ้นไป | |
? | 0 หรือ 1 | |
{n} | พอดี n ตัว | |
{n,m} | n ถึง m ตัว | |
| ตำแหน่ง | ^ | เริ่มต้น |
$ | จบ | |
\b | ขอบคำ | |
| กลุ่ม | [abc] | a หรือ b หรือ c |
[^abc] | ไม่ใช่ a, b, c | |
(...) | จัดกลุ่ม | |
| a|b | a หรือ b | |
| Greedy/Lazy | * / + | Greedy (กินมากสุด) |
*? / +? | Lazy (กินน้อยสุด) | |
| Lookahead | (?=...) | ต้องมี…ตามหลัง |
(?!...) | ต้องไม่มี…ตามหลัง |
Pattern ที่ใช้บ่อย
| งาน | Pattern |
|---|---|
[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,} | |
| เบอร์โทรไทย | 0\d{9} |
| วันที่ DD/MM/YYYY | \d{1,2}/\d{1,2}/\d{4} |
| URL | https?://[^\s]+ |
| รหัสไปรษณีย์ไทย | \d{5} |
| เลขบัตรประชาชน | \d{13} |
| ลบอักขระพิเศษ | [^A-Za-z0-9\s] |
เครื่องมือฝึกซ้อม
ส่วนตัวผมแนะนำให้ใช้เครื่องมือพวกนี้ช่วยครับ ไม่ต้องจำทุกอย่าง แค่รู้ว่าไปหาที่ไหน
AI Chatbot ตัวไหนก็ได้
การฝึกหรือทำความเข้าใจ Regex นั้น ในยุคนี้ไม่มีอะไรง่ายไปกว่าการถาม AI แล้วครับ มันจะช่วยอธิบายละเอียดได้เลยว่า แต่ละ code ใช้ทำอะไร ทำไมถึงใส่แบบนั้น ซึ่งเราน่าจะพอจะเข้าใจคำตอบของ AI ได้ง่ายขึ้นแล้ว (ถ้าเรามีความรู้พื้นฐานจากบทความนี้แล้ว 😝) ถ้าเราสงสัยก็ถามเพิ่มได้ อันนี้แหละวิธีการเรียนรู้ในยุคใหม่
Regex101
เจ้านี่เป็นเครื่องมือ Interactive ช่วยได้มากครับ 😎 ก่อนใส่ pattern ในสูตร Excel หรือใน Code เราสามารถทดสอบที่นี่ได้
- พิมพ์ pattern แล้วเห็นผลทันที
- อธิบายแต่ละส่วนของ pattern (อันนี้เจ๋งมาก!)
- สำคัญ: เลือก flavor เป็น PCRE2 ให้ตรงกับ Excel
- มี cheat sheet ในตัว
RegexLearn
บทเรียนแบบ interactive เริ่มจากง่ายไปยาก เหมาะกับคนเริ่มต้นที่อยากเรียนรู้อย่างเป็นระบบ
Regexper
แปลง pattern เป็น diagram เห็นภาพชัดเจนว่า pattern ทำงานยังไง ช่วยมากตอน debug pattern ยากๆ
สรุป
Regex อาจดูน่ากลัวตอนแรก (ผมก็เคยกลัวมากกก เหมือนกัน 555)
แต่ถ้าเริ่มจากง่ายๆ แล้วค่อยๆ เพิ่มทีละ Level จะพบว่ามันช่วยประหยัดเวลาได้เยอะมาก
ที่สำคัญคือ อย่าพยายามจำทั้งหมดในวันเดียว ยิ่งใช้บ่อย มันก็จะค่อยๆ ติดมือไปเอง
หลักการจำ 7 ข้อ:
[ ]= กลุ่มตัวอักษร (เลือกตัวใดตัวหนึ่ง)+,*,{n}= บอกจำนวน\d,\w,\s= shortcut ที่ใช้บ่อย^,$,\b= ระบุตำแหน่ง( ),|= จัดกลุ่มและเลือก*?,+?= Lazy (หยุดเร็วที่สุด)(?=...)= Lookahead (ดูข้างหน้าแต่ไม่กิน)
เมื่อไหร่ใช้ Regex แทน COPILOT:
- ข้อมูลเยอะ (พันแถวขึ้นไป)
- ต้องการผลลัพธ์แน่นอน 100%
- งาน routine ทำซ้ำทุกวัน/สัปดาห์
- ไม่อยากพึ่ง internet หรือ subscription
ลองเปิด https://regex101.com/ แล้วทดลองพิมพ์ pattern ต่างๆ ดูเลยครับ
ใครมีคำถามหรือติดปัญหาตรงไหน มาถามได้นะครับ 😎
แหล่งอ้างอิง
- Microsoft: REGEXTEST Function
- Microsoft: REGEXEXTRACT Function
- Microsoft: REGEXREPLACE Function
- Microsoft: COPILOT Function
หมายเหตุ: ฟังก์ชัน REGEX ใช้ได้ใน Excel 365 (Windows, Mac, Web) เท่านั้น ไม่รองรับ Excel ที่เก่ากว่า