


ในบทความตอนนี้ผมจะมาพูดถึงเรื่องที่เคยเป็นจุดอ่อนสำคัญของ Excel ในสมัยก่อน นั่นก็คือ Regular Expression หรือที่เรียกสั้นๆ ว่า RegEx นั่นเอง แต่ตอนนี้จุดอ่อนนั้นได้หายไปแล้วจากการมาของ Python ใน Excel (จริงๆ ใช้ VBA หรือ Power Query ก็ใช้ RegEx ได้ แต่ไม่สะดวกเท่าไหร่)
ผมได้เคยพูดถึง RegEx ไปแล้วบ้างใน 2 บทความนี้
- ค้นหาข้อความที่มีลักษณะตามต้องการ ด้วย Regular Expression (Regex)เบื้องต้น https://www.thepexcel.com/regular-expression-regex-basic/
- วิธีใช้ Regular Expression (RegEx) ใน Power Query
https://www.thepexcel.com/power-query-regex/
แต่ถ้าขี้เกียจอ่าน ผมก็จะสรุปให้เลยว่า
Regular Expression (Regex) จะช่วยเพิ่มความสามารถในการหาข้อความที่มี Pattern ตามต้องการ แบบที่กำหนดได้ละเอียดสุดๆ ได้ (ดีว่า wildcard ของ excel ล้านเท่า) เพราะมันจะมี Syntax พิเศษของมันเองที่เราจะต้องเรียนรู้เหมือนกับการเรียนภาษาย่อมๆ อีกอันนึงเลยที่จะช่วยหาสิ่งที่ต้องการได้
เช่น เราสามารถที่จะหา email, เบอร์โทรศัพท์, ชื่อ นามสกุล หรืออะไรก็ตามในกองข้อความมหาศาลที่อาจไม่เป็นระเบียบเลยก็ได้ ขอแค่มันมี Pattern ที่แน่นอนก็พอ
ใช้ Regular Expression ใน Python ของ Excel
ก่อนอื่นเราต้อง Import Library ที่ชื่อว่า re (Regular Expression) ซะก่อน ดังนี้ (ใน 1 workbook ทำครั้งเดียวก็พอ)
import reซึ่ง re จะมี Method หลายอันที่เป็นประโยชน์ เช่น
- findall = หาผลลัพธ์ที่เจอทั้งหมดตาม Pattern ที่กำหนด กลับมาเป็น List
- search = ได้ผลลัพธ์ที่เจออันแรก ตาม Pattern ที่กำหนด กลับมาเป็น Match Object (จะมีลูกเล่นเพิ่มเติม โดยเฉพาะการจัดการกับ group)
- finditer = ได้ Match Object เหมือน search แต่ว่าได้ครบทุกการ Match เลย (ใช้กับ for loop ได้ดี)
- split = แยกคำด้วยการหาตัวคั่นที่ตรงกับ Pattern ที่กำหนด
- sub = แทนที่คำเฉพาะคำที่ตรงกับ Pattern ที่กำหนด
แต่เดี๋ยวผมจะใช้ตัวที่ชื่อว่า findall ให้ดูก่อนว่าผลลัพธ์เป็นยังไง? เพราะน่าจะเข้าใจง่ายสุด
ใช้ re.findall หาทุกตัวที่เจอ
สมมติผมมีข้อความแบบนี้
โปรดติดต่อ 02-987-6543 หรือ 081-123-4567 สำหรับ Info เพิ่มเติมแล้วผมอยากได้เบอร์โทรศัพท์แต่ละอัน วิธีที่ง่ายที่สุดอันนึงหากคุณยังใช้ RegEx ไม่เป็นเลยก็คือ การถาม AI เช่น ChatGPT (เพราะมันเก่ง Python มาก)
ผมถามไปก็ได้คำตอบแบบนี้เลย

แถมมันอธิบายด้วยว่า pattern แต่ละอันแปลว่าอะไร
โดยที pattern จริงๆ ที่ใช้ในตัวอย่างนี้ คือ \d{2,3}-\d{3}-\d{4} นะ
(ส่วน r คือตัวที่บอกว่าเป็น raw string ใช้เพื่อให้ python ตีความอักขระ \ ให้เป็นข้อความจริงๆ ไม่ใช่อักษรพิเศษ มันจะได้ใช้งาน Regex ได้ไม่มีปัญหา)
\dmatches any digit. = ตัวเลขอะไรก็ได้{2,3}specifies that the preceding element (in this case,\d) must occur at least 2 and at most 3 times. = มีจำนวน 2-3 ครั้ง (ในที่นี้ก็คือเลข 2-3 ตัว)-matches the dash character literally. = เครื่องหมาย –
ทีนี้วิธีใช้ใน Excel ก็คือตามมันแนะนำเลย แค่เรา Link กับ Text ใน Cell ได้ และเราไม่จำเป็นต้อง Print หากว่าผลออกมาเป็น List เราสามารถเอาออกมาเป็น Excel Value ได้เลย เช่น
import re
text = xl("B1")
pattern = r'\d{2,3}-\d{3}-\d{4}'
result = re.findall(pattern, text)
เราจะเห็นว่า re.findall จะสามารถให้ผลเป็น List ที่เก็บผลลัพธ์ทั้งหมดที่ Match เจอกับ Pattern เราได้เลย
อย่างไรก็ตาม การพึ่งพาแต่ AI โดยไม่เข้าใจอะไร Syntax อะไรเองเลย ก็อาจทำให้ได้ผลลัพธ์ที่ไม่ถูกต้อง เช่น Pattern ที่เราระบุไปจริงงๆ แล้วเป็น Pattern ที่ไม่ค่อยมีความยืดหยุ่นเท่าไหร่นัก เนื่องจากมีการบังคับว่าสิ่งที่ต้องการ Match ต้องมี – ด้วยเสมอ
แปลว่าถ้าผมแก้เบอร์โทร ให้ไม่มี – มันก็จะหาไม่เจอเลย
เช่น แก้ตัวหลังให้เป็น 081-1234567 (แบบไม่มีขีด) มันก็หาไม่เจอแล้ว เพราะว่าใน pattern เรากดหนดว่าจะต้องเจอขีดด้วย!

ดังนั้นเราควรจะเรียนรู้ Syntax ของมันไว้ด้วย ว่าแต่ละตัวหมายถึงอะไร เราจะได้แก้ไขให้มันถูกต้องได้ ซึ่งผมสรุปให้แล้วเร็วๆ ดังนี้
ความเข้าใจ Syntax พื้นฐานนั้นสำคัญ
Literals
=========
abcกขค… ตัวหนังสือ(ที่ระบุ)
123… ตัวเลข(ที่ระบุ)
Special Characters
===================
. อักขระอะไรก็ได้ (ยกเว้นขึ้นบรรทัดใหม่)
^… เริ่มด้วย…
…$ จบด้วย…
* มีอย่างน้อย 0 ตัวขึ้นไป
+ มีอย่างน้อย 1 ตัวขึ้นไป
? มี 0 หรือ 1 ตัว
\ escape character สำหรับอักขระพิเศษ เช่น \. ก็จะแปลว่าเครื่องหมายจุด หรือ \* ก็จะแปลว่าเครื่องหมาย *
Character Classes (Alternation ระดับ Character)
==================
[abc] a, b, หรือ c
[^abc] ไม่ใช่ a, b, c
[a-z] a ถึง z ตัวไหนก็ได้
[A-Z] A ถึง Z ตัวไหนก็ได้
[0-9] เลข 0 ถึง 9
Predefined Character Classes
=======================
\d ตัวเลขอะไรก็ได้ เทียบเท่า [0-9]
\D อักขระอะไรก็ได้ที่ไม่ใช่ตัวเลข
\w อักขระภาษาอังกฤษหรือตัวเลข เทียบเท่า [a-zA-Z0-9_]
\W ไม่ใช่อักขระภาษาอังกฤษหรือตัวเลข
\s whitespace character (space, tab, newline)
\S อะไรก็ได้ที่ไม่ใช่ whitespace character
Quantifiers
========================
* มีอย่างน้อย 0 ตัวขึ้นไป
+ มีอย่างน้อย 1 ตัวขึ้นไป
? มี 0 หรือ 1 ตัว
{n} มีจำนวน n ครั้ง
{n,} มีจำนวน n ครั้งขึ้นไป
{n,m} มีจำนวน n-m ครั้ง
Grouping and Capturing
========================
(…) capturing group
(?:…) non-capturing group
Anchors
================
^… เริ่มด้วย…
…$ จบด้วย…
\b word boundary
\B non-word boundary
| หรือ (Alternation ระดับ Pattern)
============
(abc|def) หา abc หรือ def
a(|b)c หาเจอทั้ง ac หรือ abc เลย
Flags พิเศษ
=======
i ไม่สนใจพิมพ์เล็กพิมพ์ใหญ่
g global search (หาทุกตัว ไม่ใช่แค่ตัวแรก).
m multiline matching เช่น ทำให้ ^ and $ เจอทั้ง start และ end of a line ไม่ใช่ข้อความรวมกันทั้งหมดตัวอย่าง Pattern และความหมาย
- thep = มีคำว่า thep ตรงไหนก็ได้ในข้อความ
- ^thep = ขึ้นต้นด้วย thep (คำว่า thep ต้องอยู่หน้าสุด)
- thep$ = จบด้วยคำว่า thep (คำว่า thep ต้องอยู่หลังสุด)
- ^thep$ = เป็นคำว่า thep เป๊ะๆ ห้ามมีคำอื่น
- [thep] = มีตัว t h e หรือ p
- thep[1-5] = มีคำว่า thep ตามด้วยเลข 1-5 (ตัวเดียว)
- thep\d = มีคำว่า thep ตามด้วยเลข 0-9 (ตัวเดียว)
- thep\d{5} = มีคำว่า thep ตามด้วยเลข 0-9 (5 digit)
- thep\d{5,7} = มีคำว่า thep ตามด้วยเลข 0-9 (5-7 digit)
- thep\d{5,} = มีคำว่า thep ตามด้วยเลข 0-9 (5 digit ขึ้นไป)
- thep\D = มีคำว่า thep ตามด้วยอะไรก็ได้ที่ไม่ใช่ตัวเลข 1 ตัว
- thep. = มี thep ตามด้วยตัวอะไรก็ได้ 1 ตัว
- thep\. = มีคำว่า thep. (thepตามด้วยจุด) อยู่ในข้อความ
- th.p = มี th ตามด้วยตัวอะไรก็ได้ 1 ตัว แล้วตามด้วย p
- th.+p = มี th ตามด้วยตัวอะไรก็ได้อย่างน้อย 1 ตัว แล้วตามด้วย p
- th.?p = มี th ตามด้วยตัวอะไรก็ได้ 0 หรือ 1 ตัว (มีหรือไม่มีก็ได้) แล้วตามด้วย p
- th.*p = มี th ตามด้วยตัวอะไรก็ได้กี่ตัวก็ได้ (มีหรือไม่มีก็ได้) แล้วตามด้วย p
- thep? = มีคำว่า the ตามด้วย p หรือไม่ก็ได้
- thep+ = มีคำว่า the ตามด้วย p อย่างน้อย 1 ตัว
- th(ep)+ = มีคำว่า th ตามด้วย ep อย่างน้อย 1 ชุด
- (thep|inw)excel = มีคำว่า thepexcel หรือ inwexcel
- \bthep\b = เจอ thep เมื่อไม่ได้ติดกับคำอื่นเท่านั้น แต่ดีกว่า \sthep\s เพราะ \bthep\b จะเจอ thep ตอนขึ้นต้นประโยคเลยด้วย
ทดสอบ Pattern ได้ที่ regexr.com
แล้วสามารถลองนำคำที่เราต้องการ Match ไปลองใส่ในเว็บ https://regexr.com/ แล้วลองใส่ pattern ต่างๆ ลงไปดูว่ามันเจออะไรบ้าง ข้อดีคือนอกจากมันจะตอบอย่างรวดเร็วว่าเจออะไรบ้าง ตรงไหน มันยังอธิบาย Pattern ที่เราเขียนให้ด้วยว่าหมายความว่ายังไง
เช่น ถ้าเราใส่ ? เพิ่มไป ก็จะหมายถึงมี – ได้ 0 หรือ 1 ตัว ซึ่งก็จะทำให้เจอได้ดีขึ้นเป็นต้น

แต่เราใช้เลขโทรศัพท์ในรูปแบบอื่น เราก็อาจจะหาไม่เจอ เช่น
โปรดติดต่อ 02-987-6543 หรือ 081-123-4567 086-9876543 08-9123-4561 สำหรับ Info เพิ่มเติมเราอาจต้องปรับ pattern เป็นแบบนี้เผื่อๆ ไว้เลย
\d{1,3}-?\d{1,4}-?\d{1,4}-?\d{0,2}ก็จะเจอครบ 4 ตัวแบบนี้

ใช้ re.search เพื่อหารายละเอียดการ Match
ถ้าเปลี่ยนจาก findall เป็น search จะให้ผลกลับมาเป็น Match Object ซึ่งจะได้ผลลัพธ์แค่ข้อมูลเกี่ยวกับตัวแรกที่เจอเท่านั้น
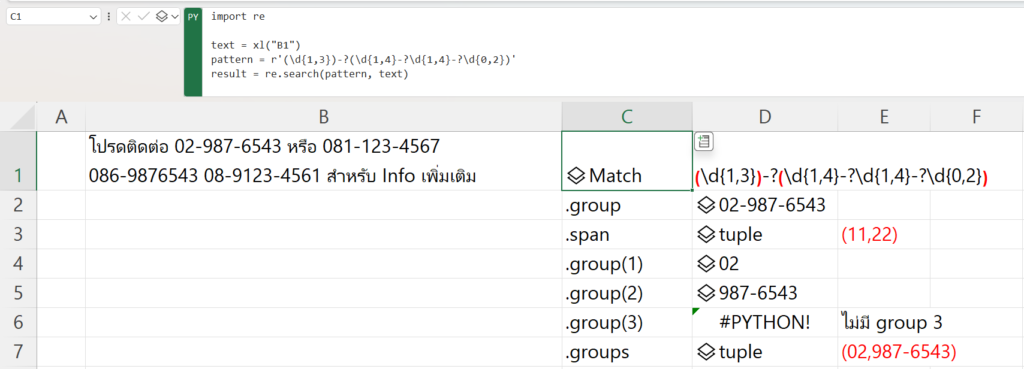
แต่ข้อดีของมันคือ มีลูกเล่นเยอะ เช่น เล่นกับการจับ Group ภายใต้การเจอครั้งเดียวนั้นได้ ดังนั้นผมจะขอแก้ Pattern ให้จับกลุ่ม 2 ก้อนแยกกัน ด้วยการใส่วงเล็บครอบ คือ
ตัวก่อนขีดอันแรก กับหลังขีดอันแรก เช่น
(\d{1,3})
-?
(\d{1,4}-?\d{1,4}-?\d{0,2})
import re
text = xl("B1")
pattern = r'(\d{1,3})-?(\d{1,4}-?\d{1,4}-?\d{0,2})'
result = re.search(pattern, text)แล้วเราสามารถใช้ Method เหล่านี้ดึงข้อมูลที่เจอได้ เช่น
.group()คืนค่าข้อความที่มีการจับคู่เจอ (match) ตัวแรก.span()คืนค่าเป็น tuple ที่มีตำแหน่งเริ่มต้นและตำแหน่งสิ้นสุดของข้อความแรกที่เจอ.groups()คืนค่าข้อความที่มีการจับคู่เจอ (match) group ทั้งหมดเป็น tuple
ผลเป็นดังนี้
กรณีที่อยากได้ข้อมูลเหล่านี้จากทุก Match ที่เจอเลย เราอาจใช้ re.finditer มาช่วย
ใช้ re.finditer ได้ Match Object ครบทุกอันที่เจอ

ซึ่งเราสามารถใช้ ใน for loop หรือ list comprehension ได้ เช่น
[match.group() for match in result]แต่ว่าหลังจากใช้ object result เพื่อวน loop ไปแล้ว เราจะต้องทำการใช้ finditer ใหม่ มันถึงจะดึงค่าออกมาได้ (อันนี้ผมไม่แน่ใจว่าทำไม ใครรู้ช่วยบอกด้วย)
result = re.finditer(pattern, text)
[match.groups() for match in result]result = re.finditer(pattern, text)
[match.span() for match in result]
ใช้ re.split เพื่อแยกคำ
ผมจะลองเปลี่ยนตัวอย่างบ้าง สมมติว่าผมจะแยกรายชื่อสมาชิกในกลุ่มออกจากกัน โดยมีข้อความดังนี้
สมชาย, สมหญิง มานี ;ชูใจ | ปิติ ผมต้องการแยกด้วย comma, space, semicolon, pipe ผมสามารถใส่ pattern แบบนี้ได้
[, |;]โดยที่ทุก character ใน [ ] ก็คือเจอตัวไหนก็ได้นั่นเอง
import re
text = xl("B1")
pattern = r'[, |;]'
result=re.split(pattern,text)
แบบนี้ผมก็จะได้ว่า

ซึ่งเนื่องจากเรามี space หลายที มันก็อาจมีการแยกหลายรอบ ซึ่งเราก็แค่หาทางจัดการ item ใน list นี้ให้เรียบร้อย เช่น อาจใช้ list comprehension แบบนี้ก็ได้ คือคัดเลือกเฉพาะ item ที่ไม่ใช่ blank text
import re
text = xl("B1")
pattern = r'[, |;]'
result = re.split(pattern, text)
[x for x in result if x != '']
ใช้ re.sub เพื่อแทนที่คำ
สมมติโจทย์เปลี่ยนเล็กน้อย แทนที่จะให้ split คราวนี้อยากจะแทนเครื่องหมาย ,;| ด้วย space ก็จะได้แบบนี้ (มี parameter เพิ่มนิดนึงคือ จะแทน pattern ด้วยอะไร)
import re
text = xl("B1")
pattern = r'[,|;]'
result = re.sub(pattern," ",text)
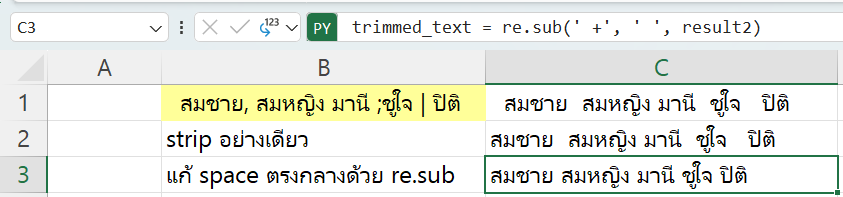
อย่างไรก็ตาม จะเห็นว่ามันมี Space เกินๆ อยู่ ซึ่งจะเอาออกด้วย TRIM ของ Excel ก็ได้แหละ แต่คราวนี้เราอยากจะลองใช้ Python ดูบ้าง
วิธีเอา Space หัวท้ายออกของ Python ก็คือ String Method ที่ชื่อว่า .strip() มาช่วย
result2=result.strip()ซึ่งมันเอาออกแค่หัวท้าย ไม่ได้เอาตรงกลางออก เช่นเดียวกับ Trim ของ Power Query เลย
กรณีที่มี space ตรงกลางซ้อนกันเยอะเกินไปแล้วอยากจะเอาให้เหลือ space เดียวสวยๆ แบบ TRIM ของ Excel ก็สามารถใช้ re.sub มาช่วยได้ดังนี้
trimmed_text = re.sub(' +', ' ', result2)pattern ‘ +’ แปลว่า เราจะหา space อย่างน้อย 1 ตัว (เพราะตามด้วย+)
แล้วแทนด้วย ‘ ‘ ซึ่งก็คือ space 1 ตัว นั่นเอง
สรุปแล้วจะได้เป็นแบบนี้
ซึ่งตอนนี้ก็แปลว่าเรามีเครื่องมือที่จะใช้ค้นหา หรือจัดการข้อความตาม pattern ที่เราต้องการได้แล้ว ซึ่งจะเพิ่มความสามารถในการจัดการข้อมูลอย่างมหาศาลเลย
ตอนต่อไป
ในตอนต่อไปเราจะมาเรียนรู้วิธีการสร้างฟังก์ชันขึ้นมาใช้เองบ้างครับ