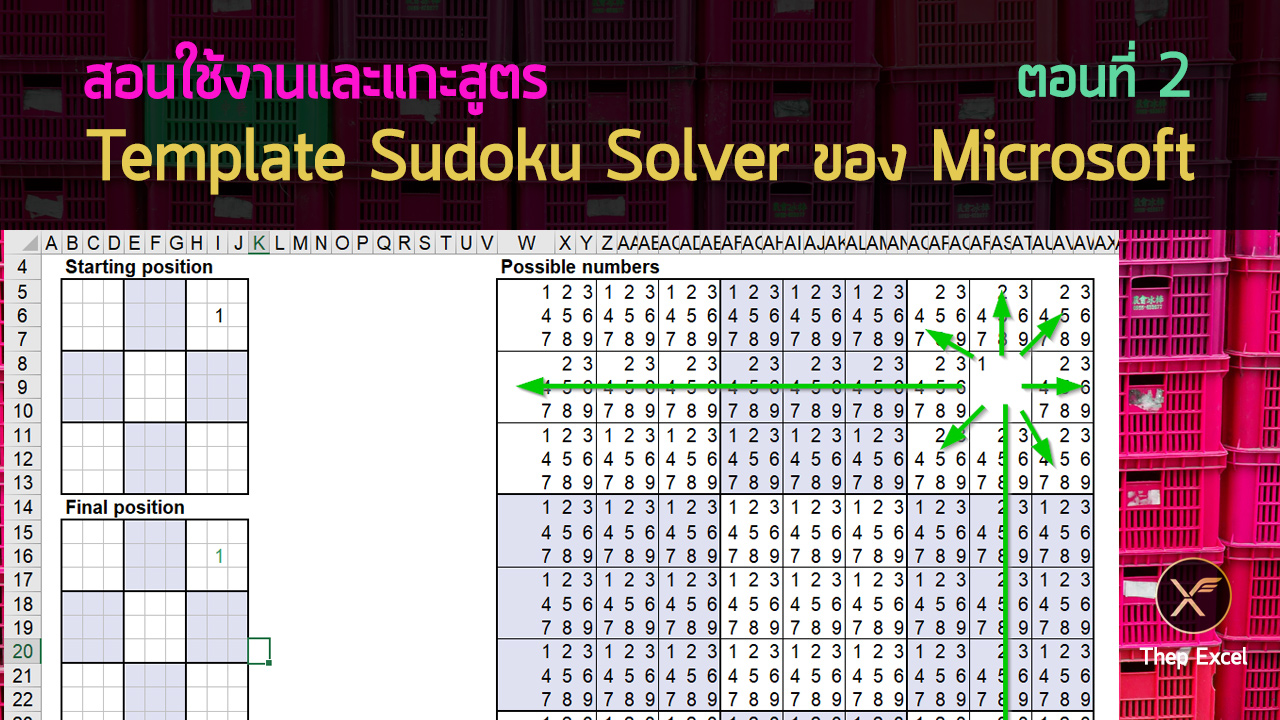
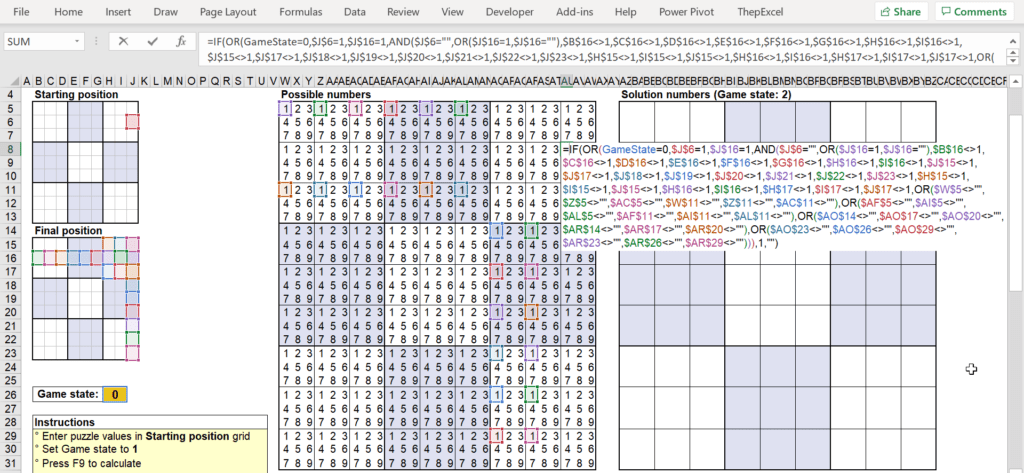
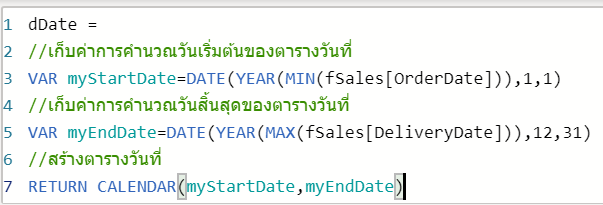
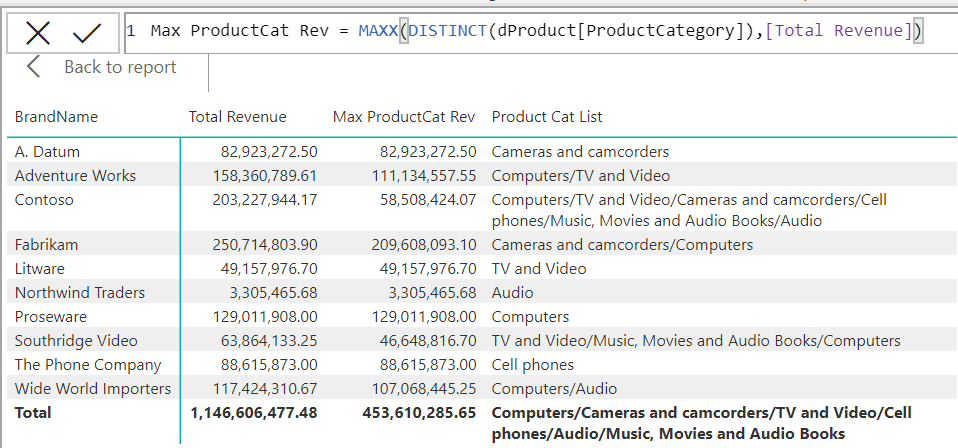
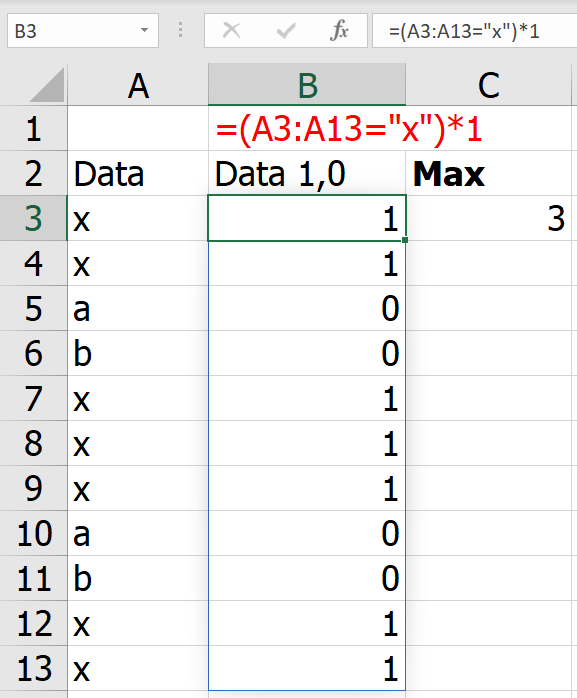
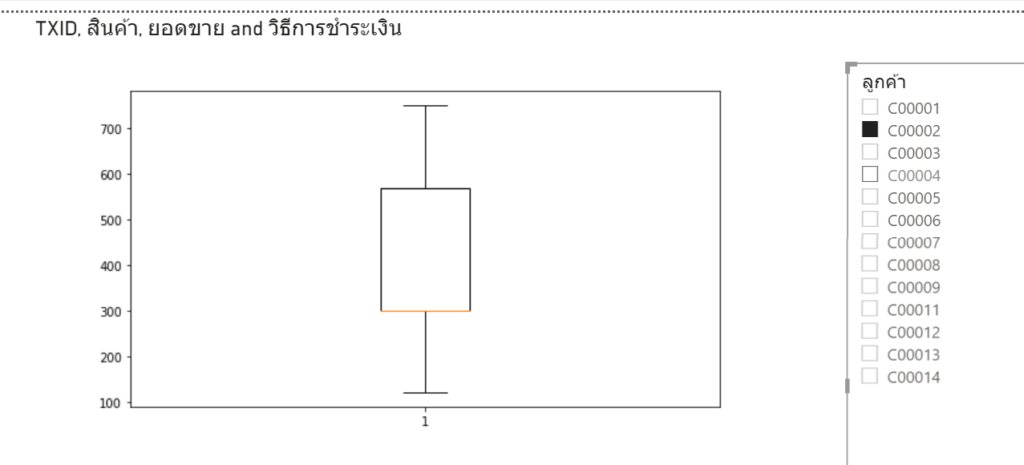
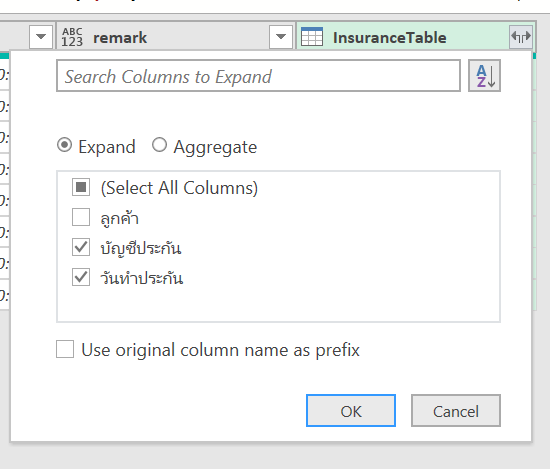
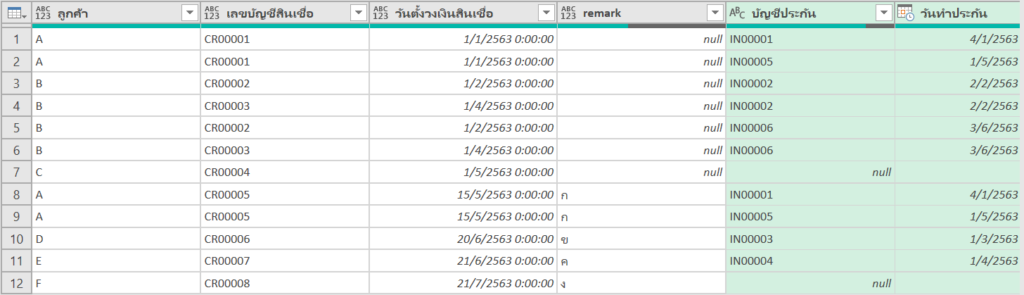
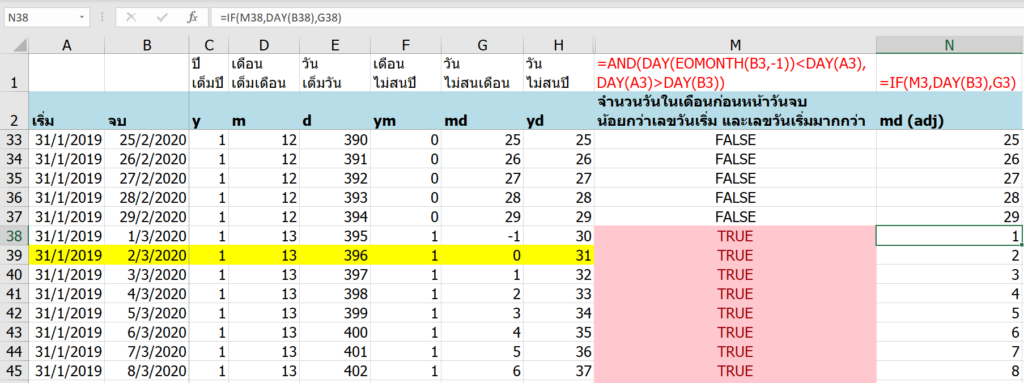
การเช็คว่าตัวใดตัวหนึ่งไม่ว่าง มันก็คือ การมองว่าในแต่ละ block 3×3 มีการลงเลข possible number นั้นๆ ไปแล้วในแนวอื่นที่ไม่ตรงกับตัวมันนั่นเอง เรียกได้ว่าถ้ามีการลงเลข 1 ในแนวอื่นแล้ว แสดงว่าช่องมันเองยังเป็นไปได้ที่จะเป็นเลข 1 อยู่นั่นเองครับ
สูตรทั้งหมดเป็นสูตรแบบงูกินหาง
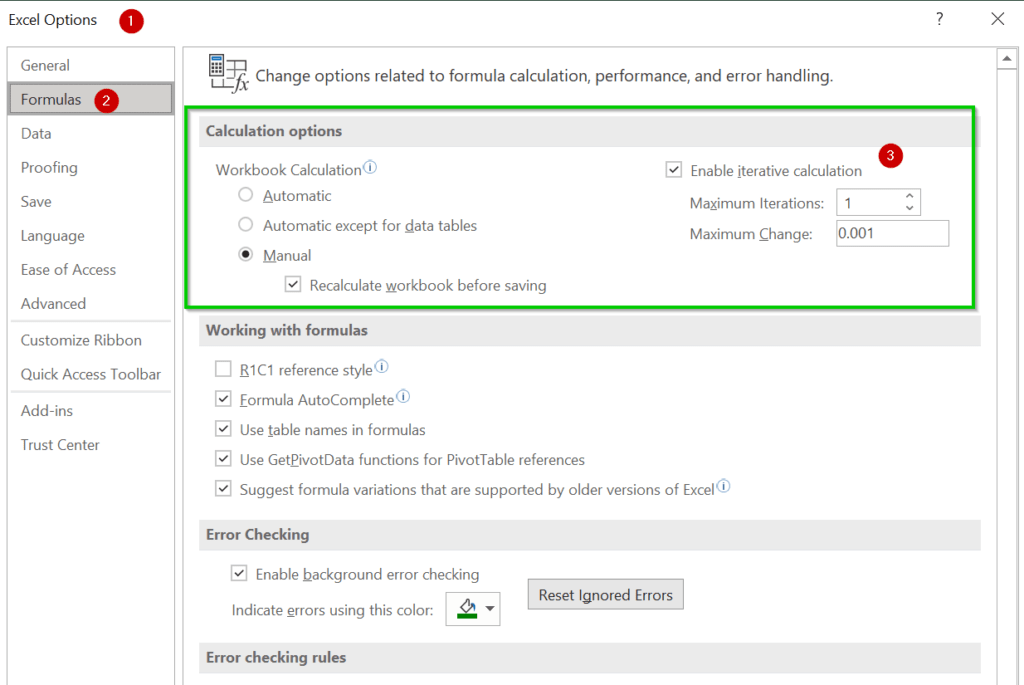
ถ้าสังเกตดู สูตรใน Final Position มีการอ้างอิงจาก Possible Number และสูตรใน Possible Number ก็มีการคำนวณจาก Final position ด้วย แถม Possible Number ก็อ้างอิงกันเองพันกันมั่วไปหมดอีก ถ้าเราใช้สูตรพวกนี้ในโหมดการทำงานปกติ มันจะด่าเราว่าเราเขียนสูตรแบบ Circular Reference ทันที
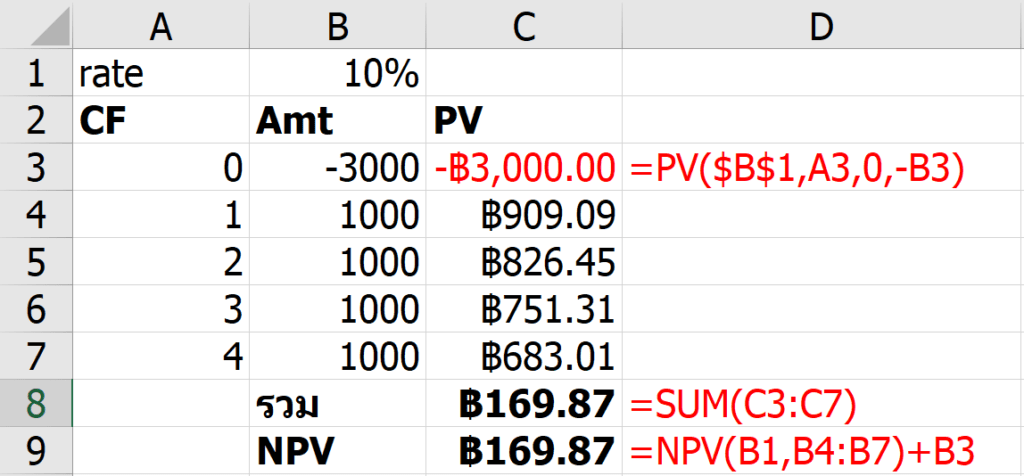
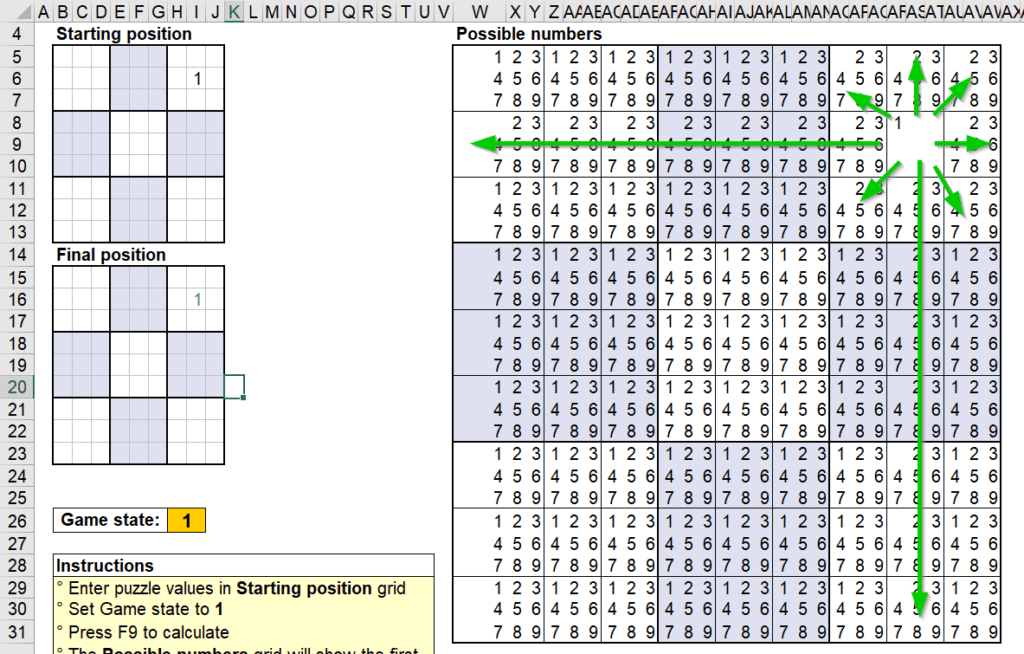
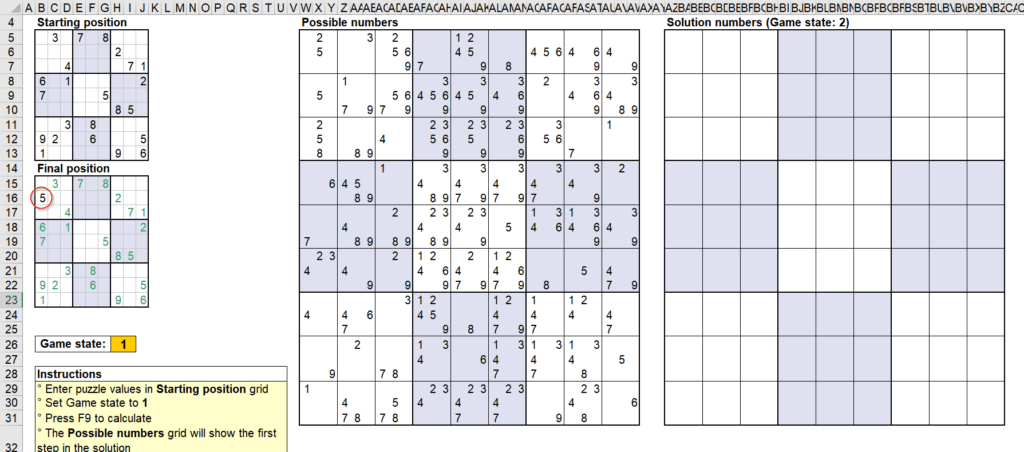
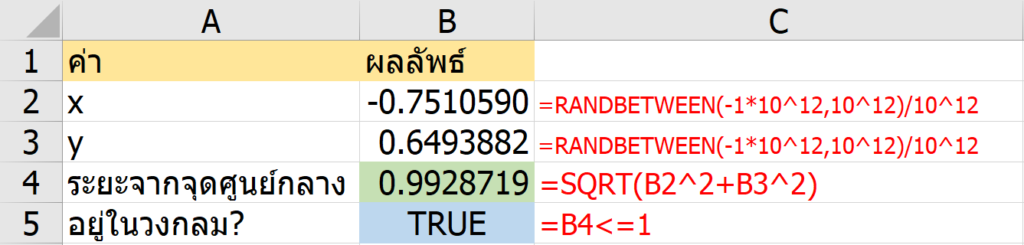
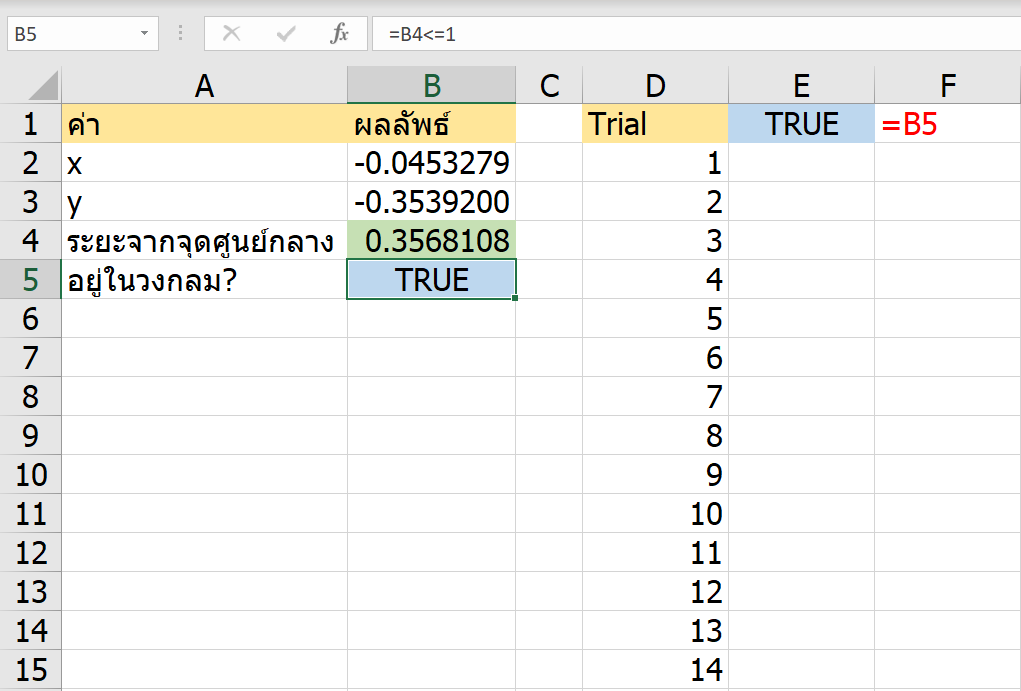
ลองทดสอบการทำงานของสูตร โดยใส่ Starting Position เป็น 1 ลงไปช่องนึง แล้วปรับ Game Stage เป็น 1 แล้ว F9 รัวๆ
จะเห็นว่าการกด F9 ทีแรก จะทำให้ Possible Number ในพื้นที่ AR8:AT10 นั้นมีเลข 1 โผล่มาตัวเดียวเลย (เพราะเงื่อนไขช่อง Starting Position ยังว่าง $I$6=”” นั้นเป็นเท็จไปแล้ว) ทำให้ Final Position สามารถมีเลข 1 โผล่ออกมาได้เพราะ COUNT ได้ตัวเดียวในที่สุด
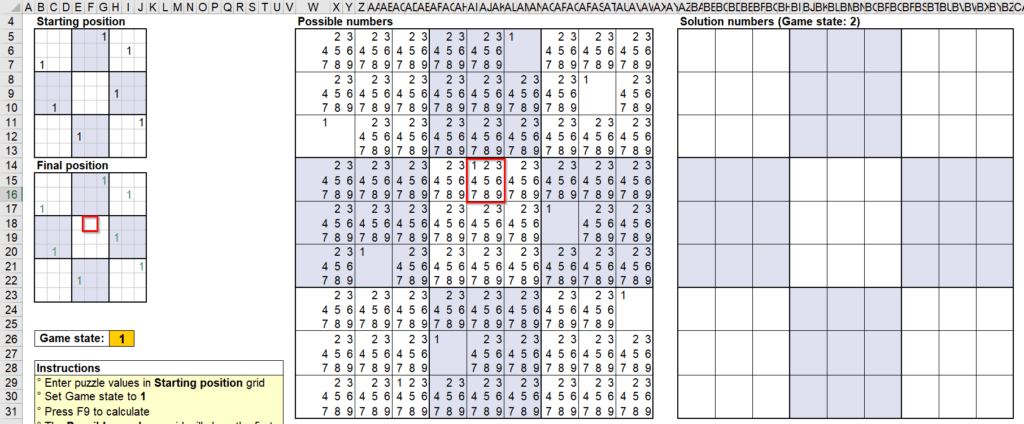
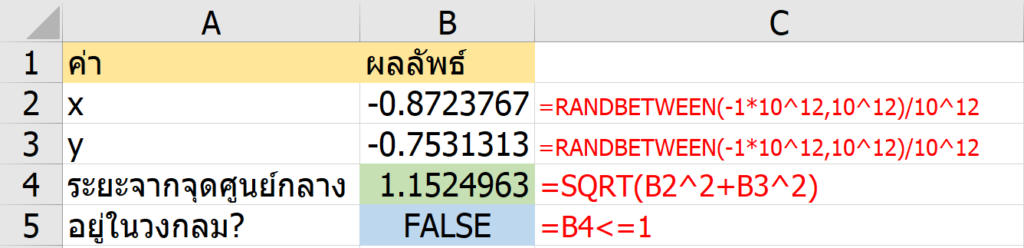
พอกด F9 ครั้งต่อๆ ไปจะทำให้ Possible Number ได้มีการตัดเลข 1 ในแนวเดียวกันออกจนหมดอีกด้วย อันนี้เป็นเพราะว่่าใน Final Position มีการลงเลข 1 ไปแล้วในแนวเดียวกัน ทำให้เงื่อนไขพิเศษที่เช็คใน Final Position เป็น FALSE นั่นเอง พอเป็น FALSE ทำให้ได้ค่า “” ออกมาในที่สุด
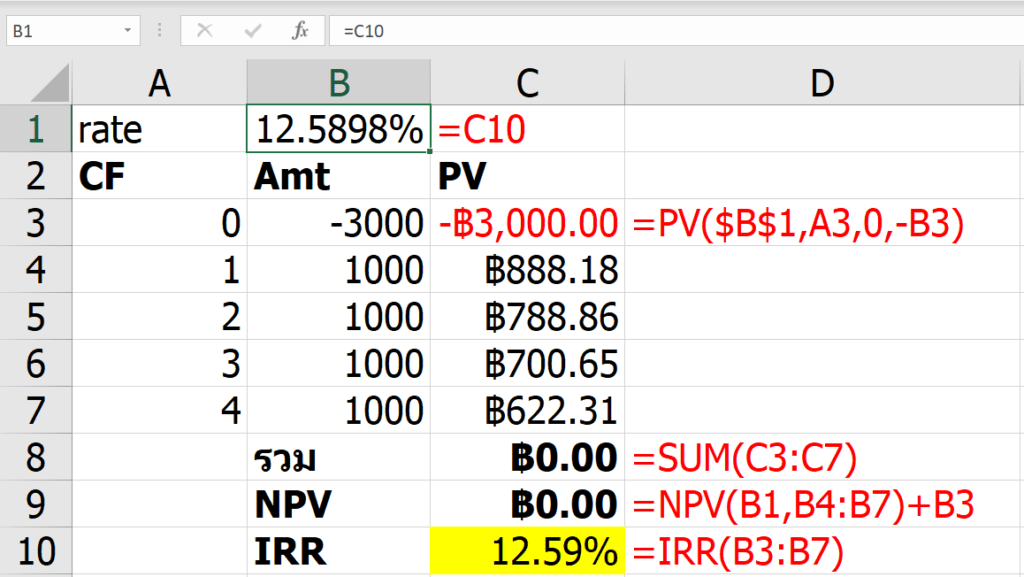
ผมลองใส่เลข 1 เพิ่ม ในระดับที่มันควรตอบได้แล้วว่าเลข 1 ตัวสุดท้ายอยู่ที่ไหน แต่มันก็ดันไม่ให้คำตอบออกมา เพราะ Possible Number ยังคงมีหลายเลขอยู่ แสดงว่า Logic เท่านี้ยังไม่เพียงพอ
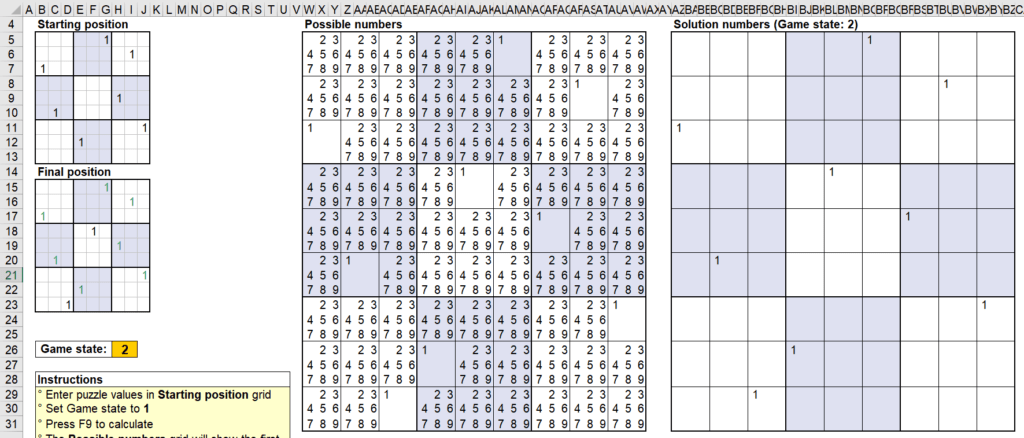
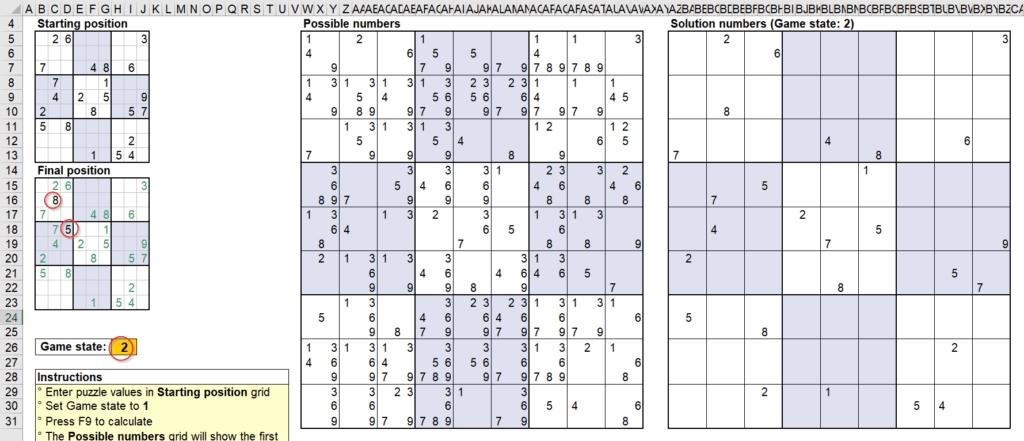
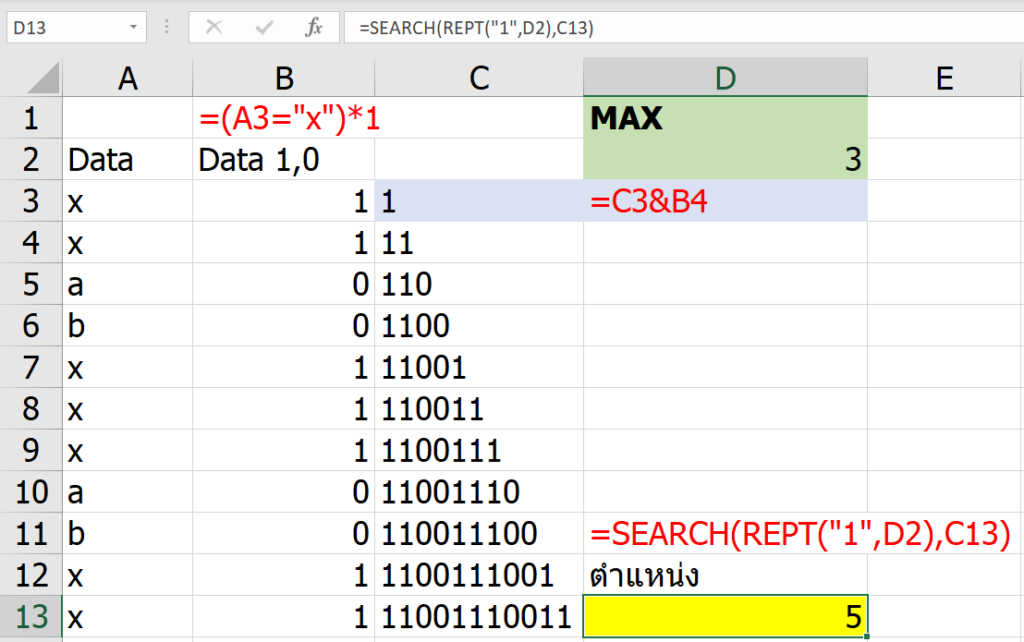
ในทีุ่ดก็ถึงเวลาของ Solution Numbers ที่เป็น Game Stage 2 ซักที
นี่คือสาเหตุที่ว่าพอเราปรับ Game Stage เป็น 2 แล้วกด F9 มันจึงมีเลขโผล่มาที่ Solution Numbers ซึ่งทำให้เลขโผล่ที่ Final Position ได้ในที่สุด (Game Stage2 ก็ยังสามารถคำนวณ Possible Numbers เพิ่มได้อยู่นะ)
สรุป
และนี่ก็คือหลักการคิดของตัว Sudoku Solver นี้ครับ ซึ่งสูตรที่แสดงออกมาใน Template ล่าสุดที่เราใช้กันอยู่นี้นั้นดูถึกอย่างมาก ซึ่งจริงๆ แล้วในอดีต Template นี้สูตรไม่ได้ถึกขนาดนี้ แต่เกิดจากการเขียนสูตรพวก INDEX ผสมกับ ROW/COLUMN/MOD ที่ซับซ้อนผสมอยู่ใน Defined Name ต่างหาก (ไม่แน่ใจเหมือนกันว่าทำไมถึงมาแก้สูตรให้กลายเป็นแบบถึก)
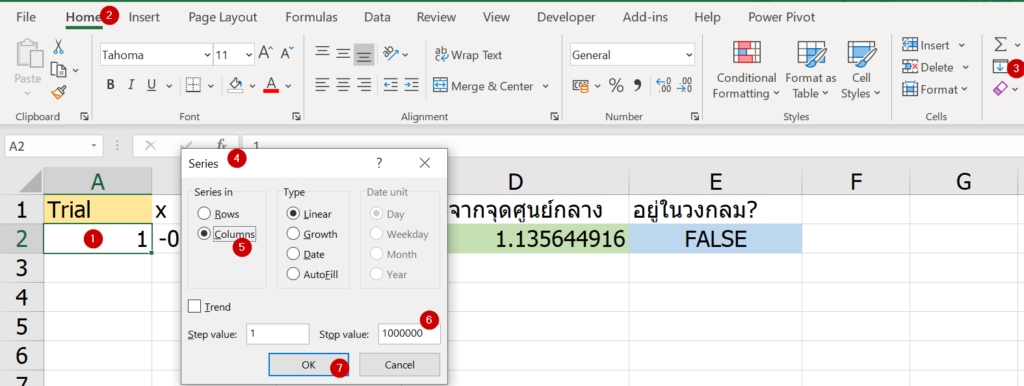
ก่อนอื่นให้กรอกตัวโจทย์ลงใน Starting Position ให้ครบ แล้วแก้ Game State ให้เป็นเลข 1 แล้วกด F9 เพื่อ Calculate จะเห็นว่าตัวเลขใน Possible Numbers นั้นหายไปบางส่วน ก็ให้กด F9 เพื่อ Cal ต่อไป
ให้ลบค่าใน Starting Position ออกให้หมด (ลากคลุมแล้วกดปุ่ม Del บน Keyboard ได้เลย) จากนั้นเลือก Game Stage เป็น 0 แล้วกดปุ่ม F9 เพื่อ Cal ใหม่ไปรัวๆ จนกว่าค่าจะหายหมด
Sub Macro1()
'
' Macro1 Macro
'
'
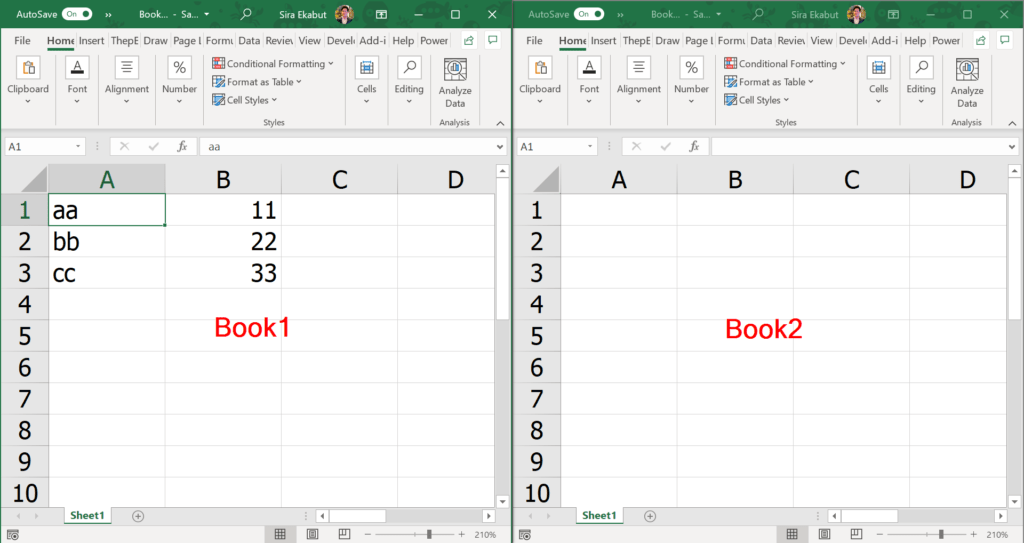
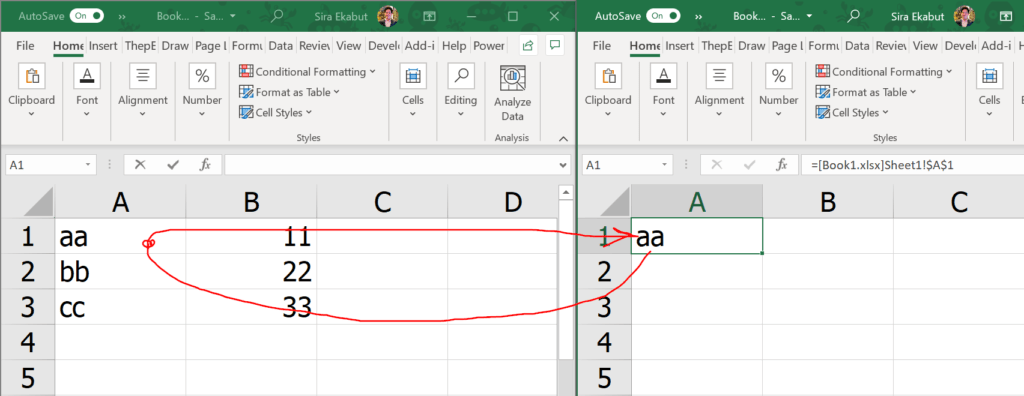
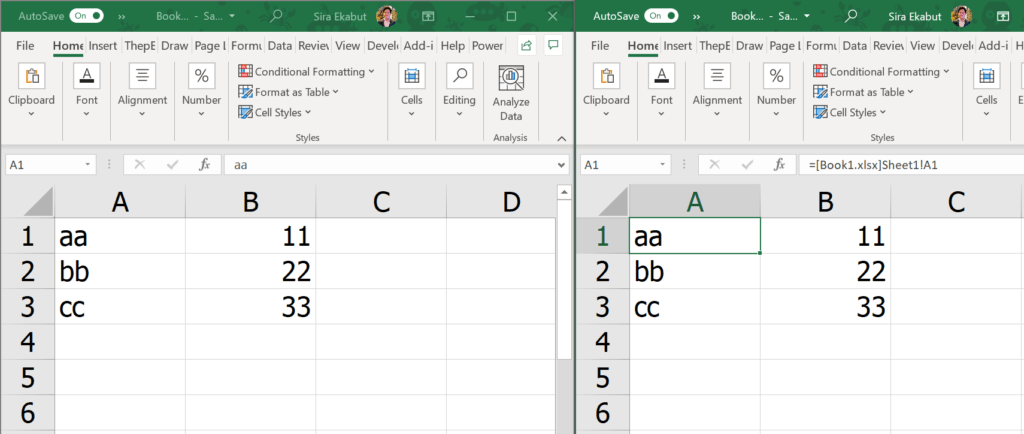
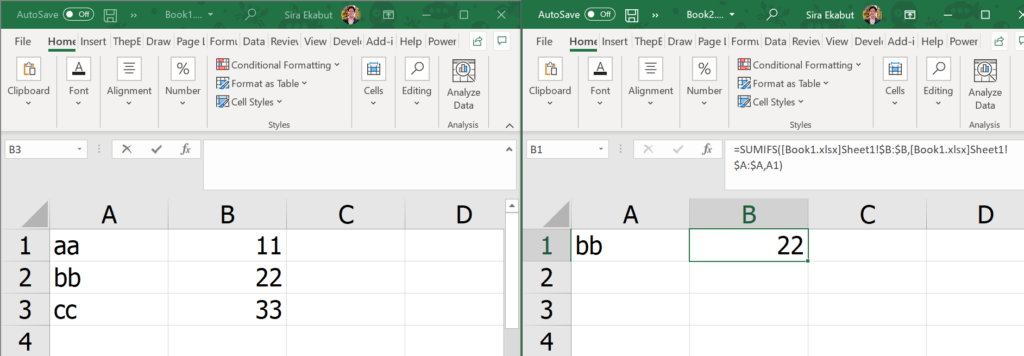
Windows("Book1.xlsx").Activate
Range("A1:B3").Select
Selection.Copy
Windows("Book2.xlsx").Activate
Range("A1").Select
ActiveSheet.Paste
End Sub
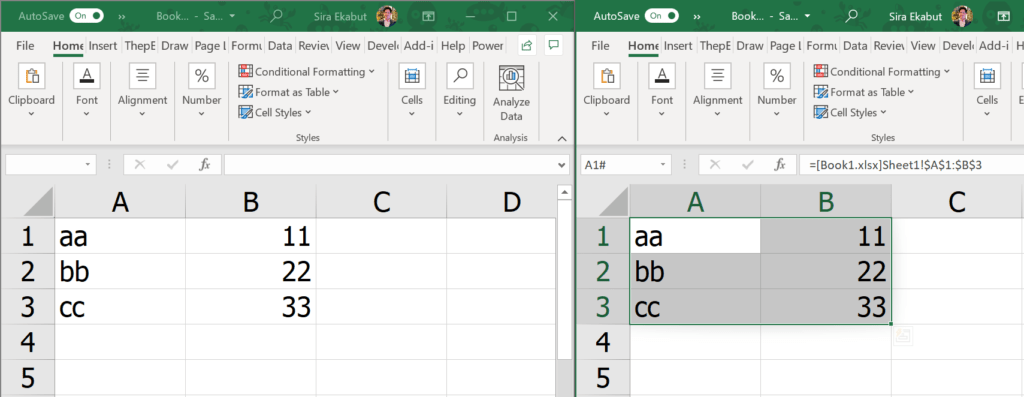
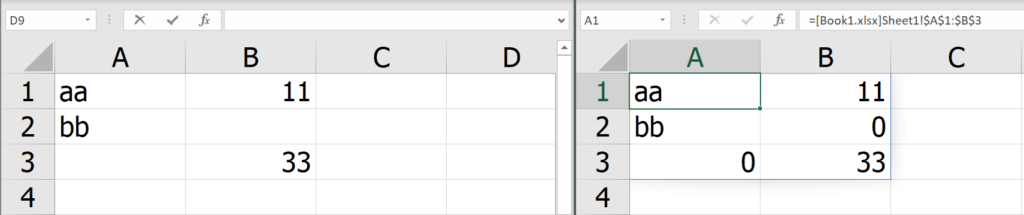
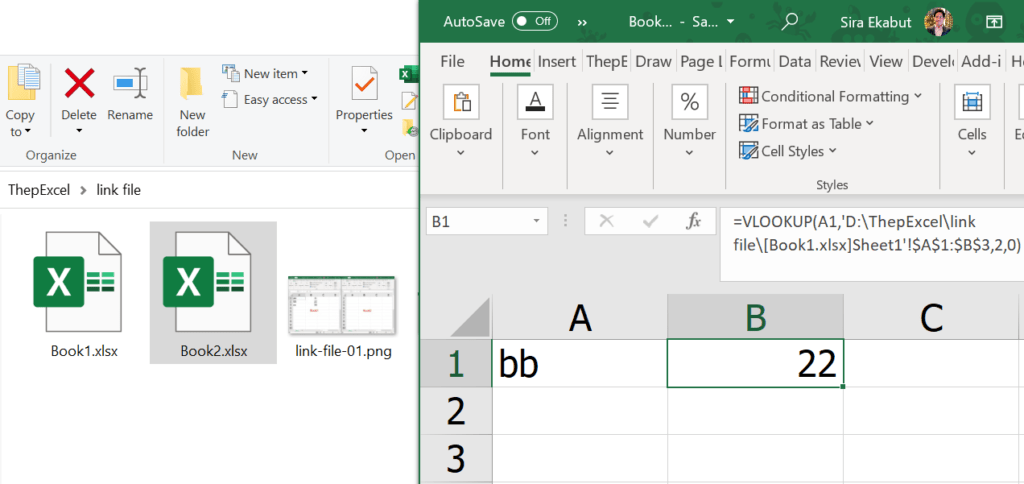
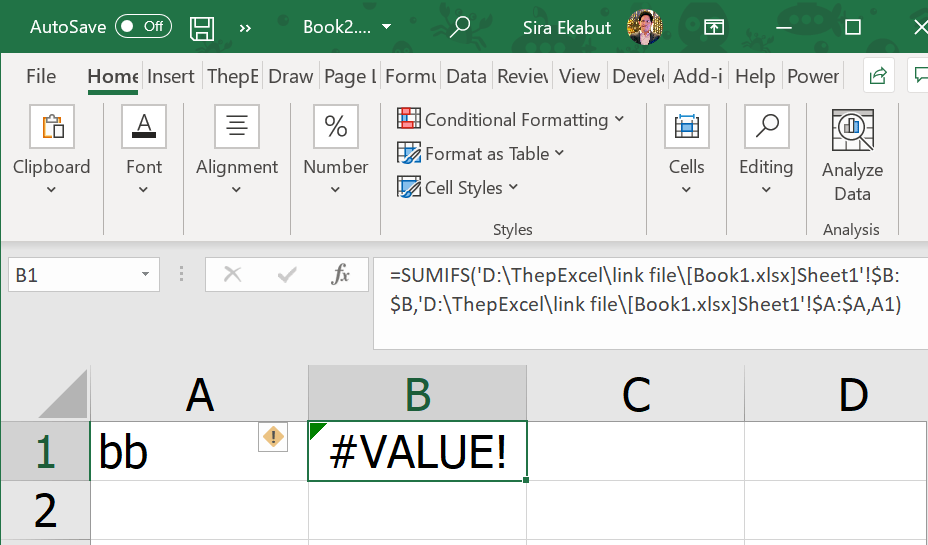
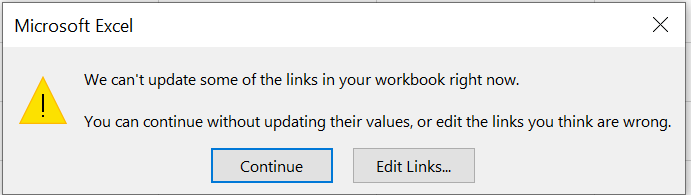
แต่ code ทั้งบนจะใช้ได้ก็ต่อเมื่อเปิดไฟล์ค้างไว้ทั้งคู่ ดังนั้นเวลาเรา Record Macro ควรจะปิดไฟล์ต้นทางไว้ก่อน มันจะได้บันทึกการเปิดไฟล์ต้นทางไว้ด้วย ดังนี้
Sub Macro2()
'
' Macro2 Macro
'
'
Workbooks.Open Filename:="D:\ThepExcel\link file\sub\Book1.xlsx"
Range("A1:B3").Select
Selection.Copy
Windows("Book2.xlsx").Activate
Range("A1").Select
ActiveSheet.Paste
End Sub
จากนั้นเราค่อยเอา Macro2 นี้ไปสั่ง Run เมื่อกดปุ่ม หรือมี event บางอย่างอีกทีก็ได้
ใช้ Power Query
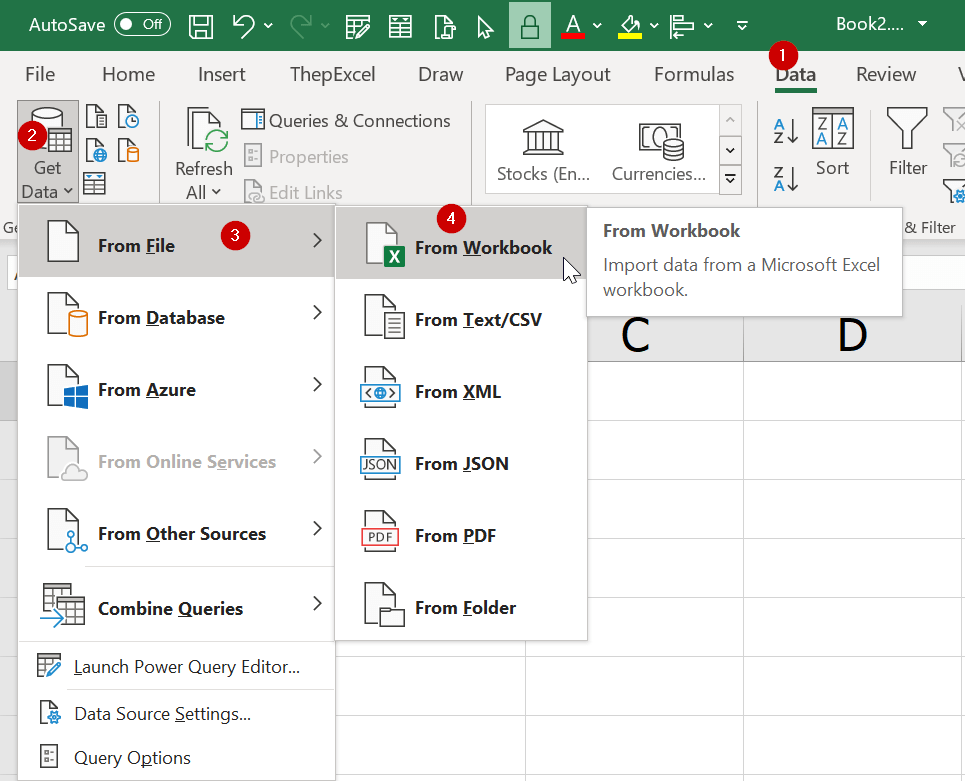
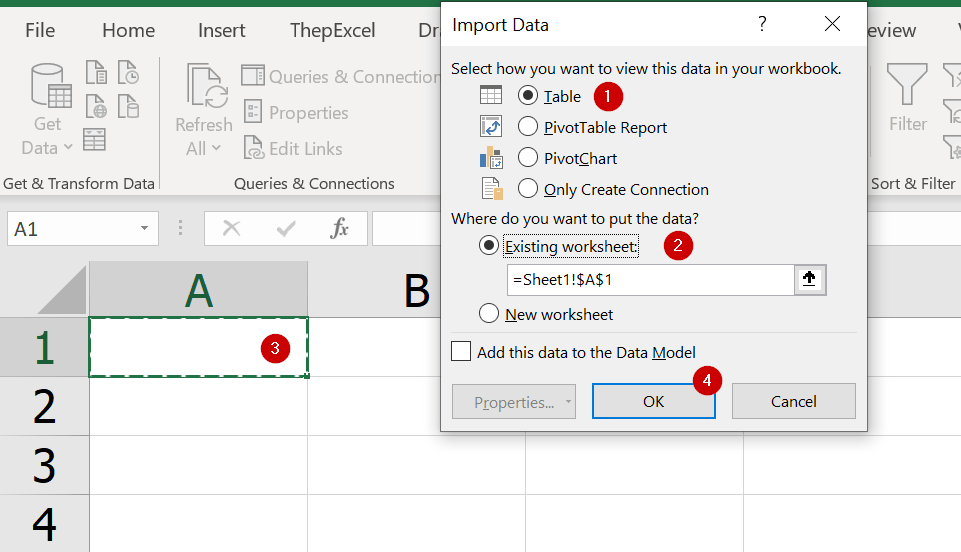
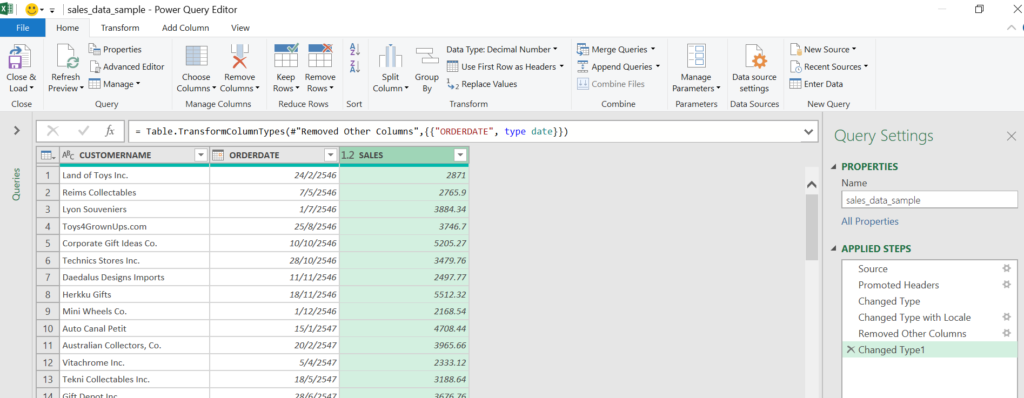
วิธีสุดท้ายที่จะแนะนำคือ Power Query ซึ่งทำงานได้ดีขณะที่ไฟล์ต้นทางปิดอยู่ครับ (ถ้าเปิดอยู่ ก็ต้อง save ก่อน จึงจะเห็นข้อมูลล่าสุด) ให้เลือก Get Data จากไฟล์ Excel แล้วเลือกไฟล์ต้นทางที่เราต้องการ
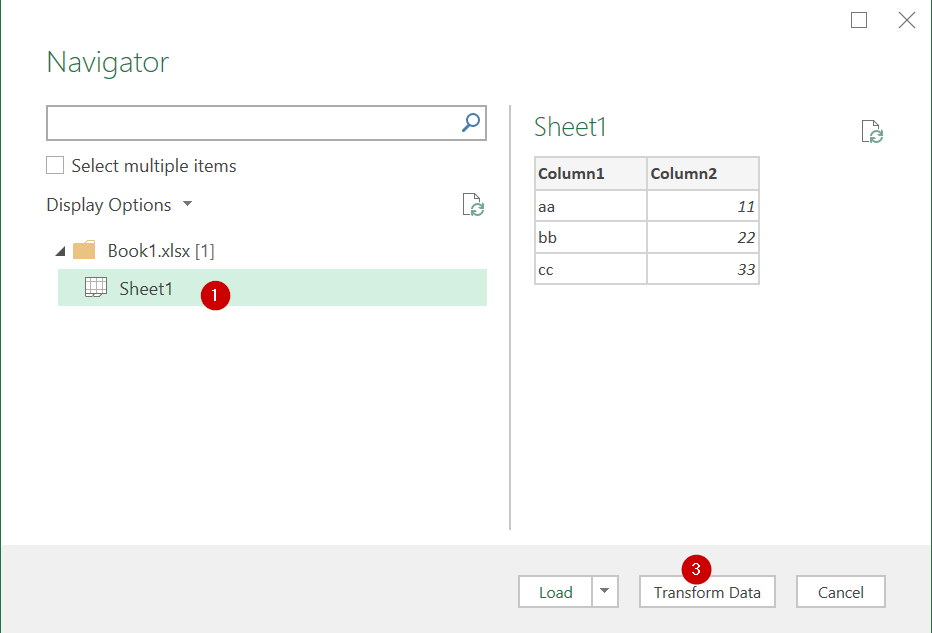
จากนั้นเลือก sheet หรือ table ที่ต้องการ และถ้าอยากตรวจสอบหรือดัดแปลงข้อมูลก่อนก็ให้กด Transform Data แต่ถ้ามั่นใจว่าข้อมูล ok ก็จะกด Load Data ออกมาเลยก็ได้
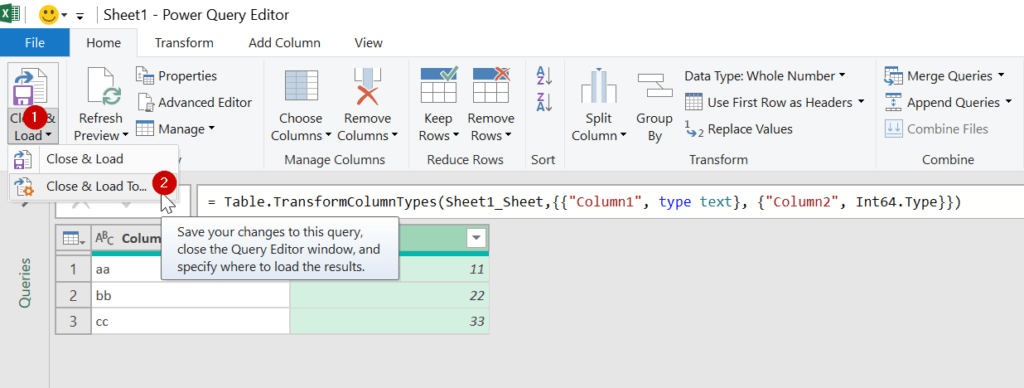
พอกด Transform Data ก็จะเปิด Power Query Editor ขึ้นมา ซึ่งในนี้เรายังทำอะไรได้อีกมาก เช่น ลบคอลัมน์ที่ไม่ต้องการ หรือ Filter ให้เหลือเฉพาะข้อมูลที่ต้องการได้เลย
ถ้าข้อมูลดู ok แล้วกดกด Close & Load to… ได้เลย
จากนั้นก็เลือกได้ว่า จะเอา Data ออกมาเป็นอะไร เช่น Table และจะไว้ตรงไหนก็ได้
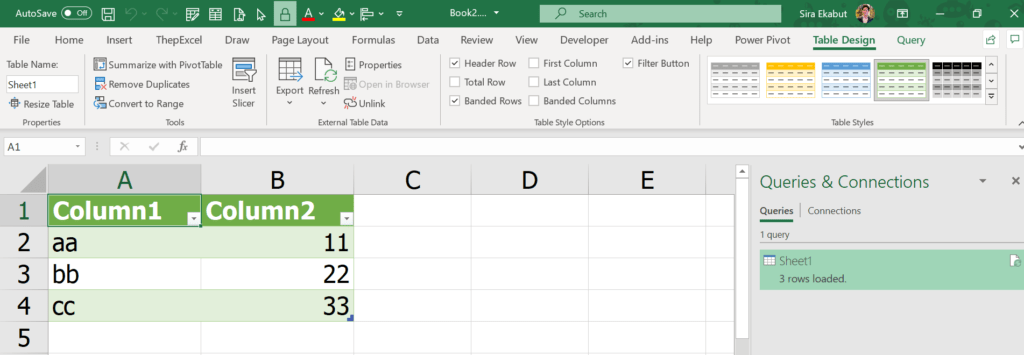
จะได้ผลลัพธ์ออกมาเป็น Table แบบนี้
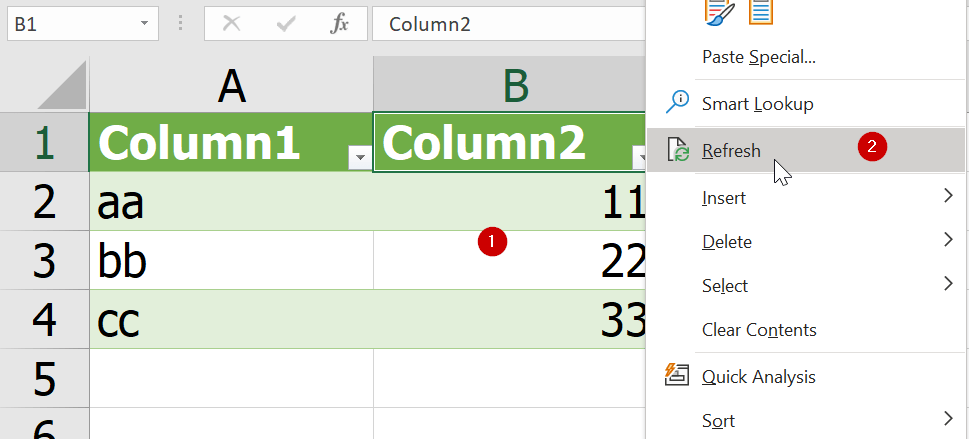
ถ้ามีแก้ข้อมูลต้นทาง แล้ว Save แล้ว ให้มาที่ข้อมูลปลายทางแล้วกด คลิ๊กขวาที่ตารางปลายทาง แล้ว Refresh ได้เลย
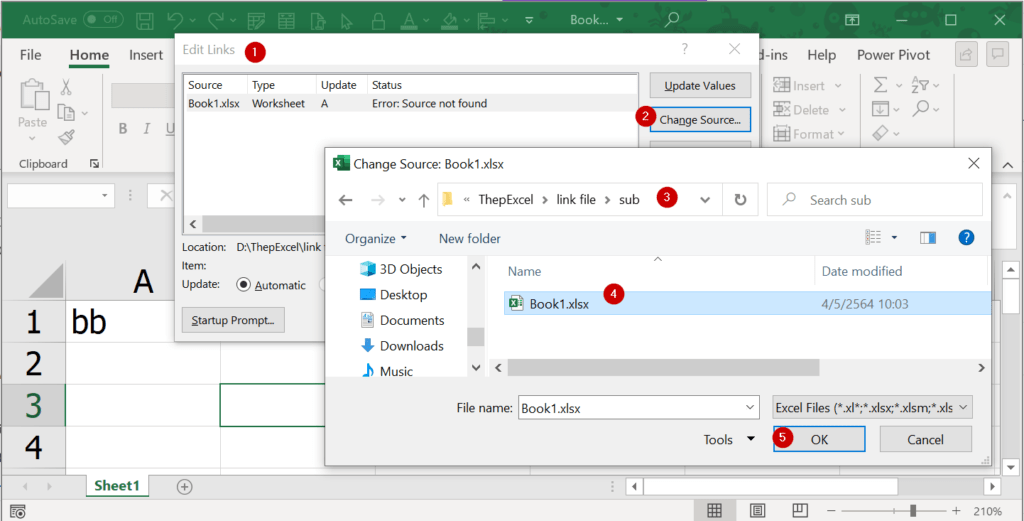
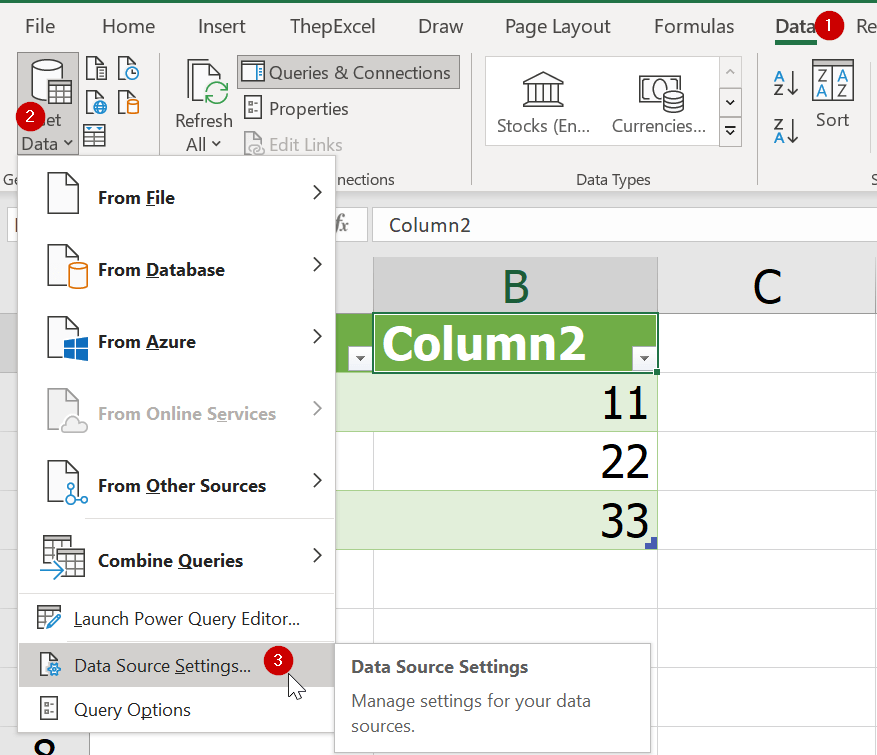
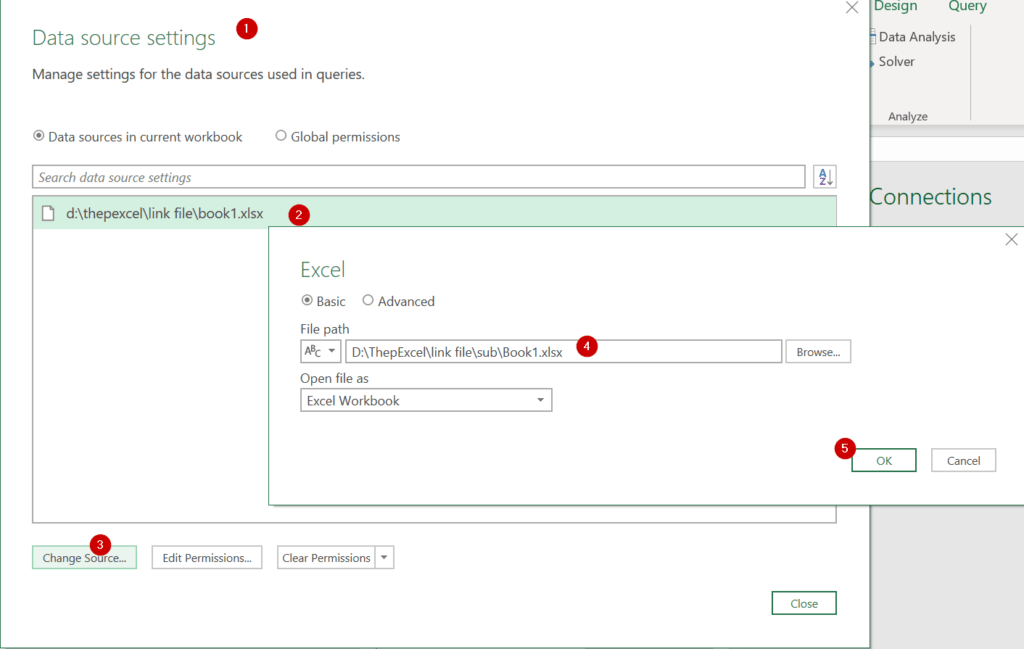
ถ้ามีการย้ายตำแหน่งไฟล์ต้นทาง ให้ไปแก้ที่อยู่ได้ที่ Data Source Setting ตามรูปได้เลย
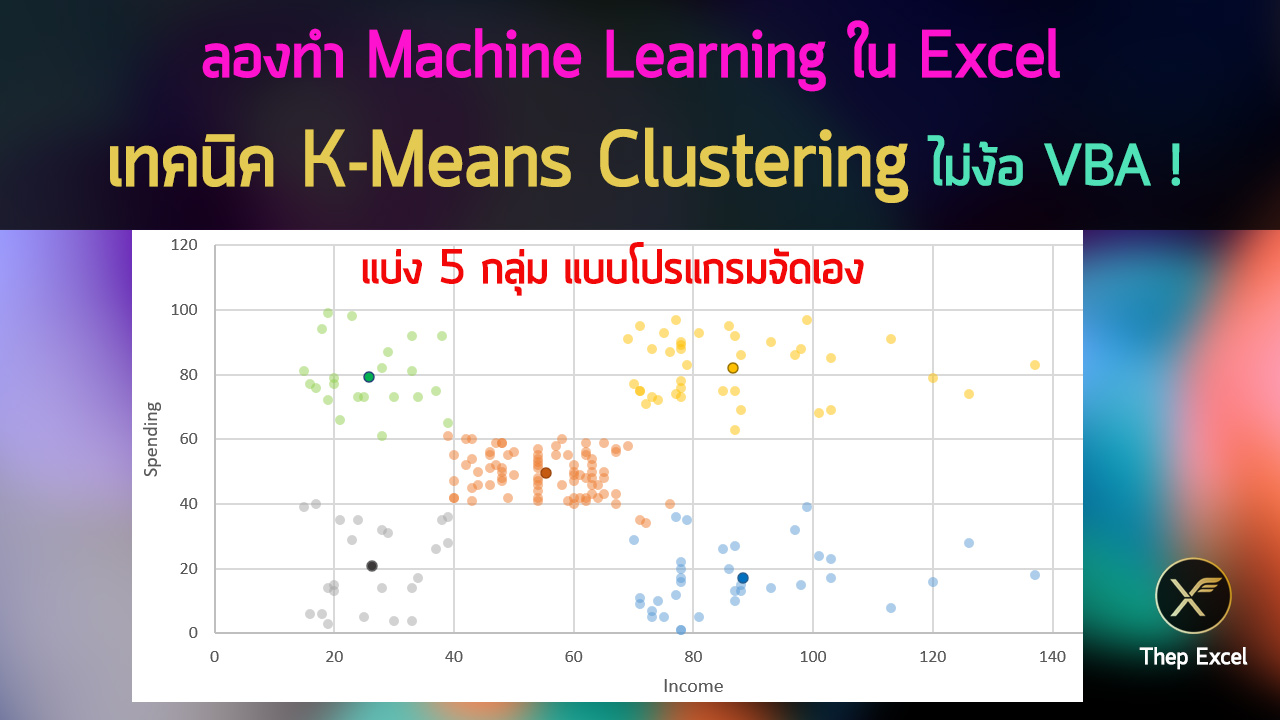
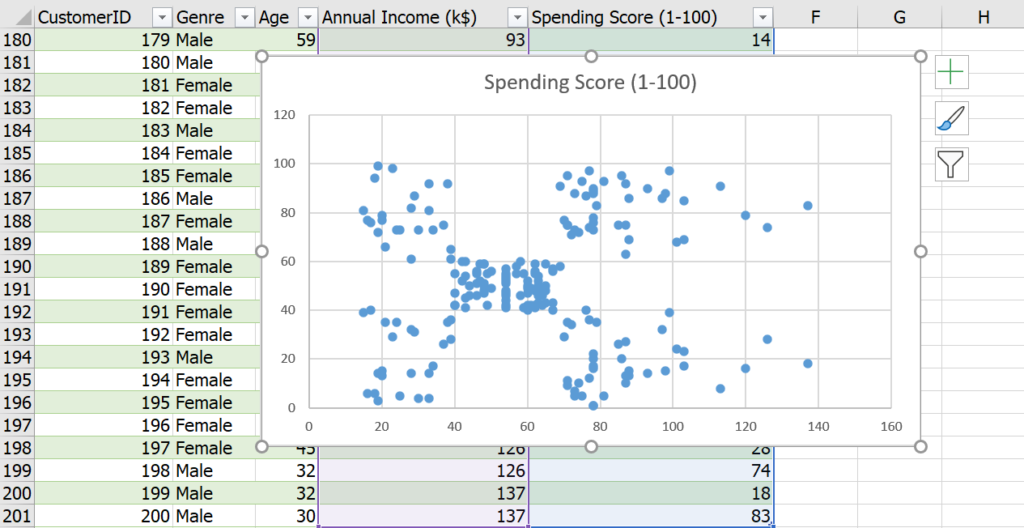
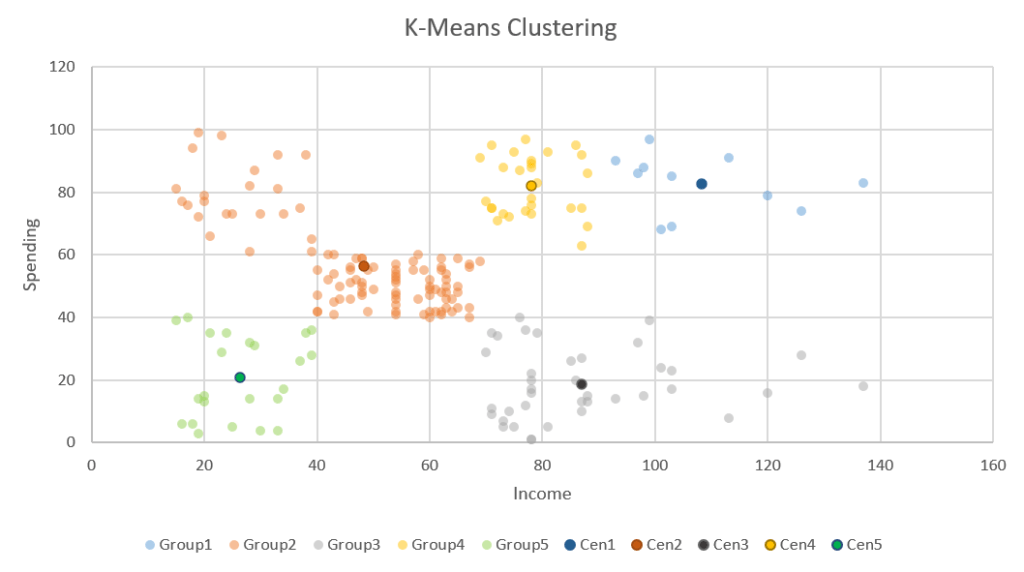
ขั้นตอนต่อไป ผมสร้าง sheet ใหม่แล้วเราจะ random สร้างจุดขึ้นมา 5 จุดจาก Range ของข้อมูลที่มี เสร็จแล้วทำให้กลายเป็น Value ไว้ด้วย จะได้ไม่เปลี่ยนอีก (x คือ Income, y คือ spending)
จากนั้นคำนวณว่าแต่ละจุดอยู่ใกล้ Point กลางอันไหนเท่าไหร่ ด้วยสูตรระยะห่างระหว่างจุด จากความสัมพันธ์เพื่อคำนวณด้านตรงข้ามสามเหลี่ยมมุมฉากสมัยเด็กๆ (ผมมีเปลี่ยนชื่อคอลัมน์เป็น Income กับ spending ด้วยจะได้ง่ายๆ)
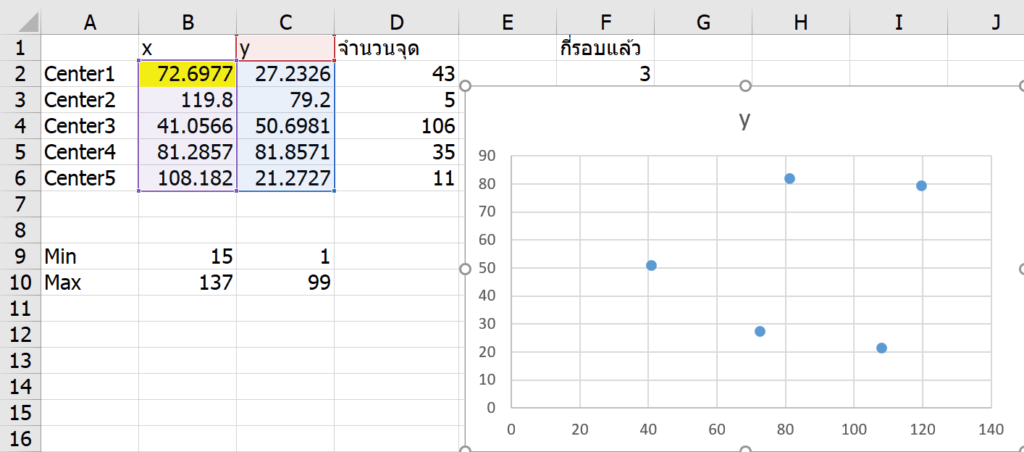
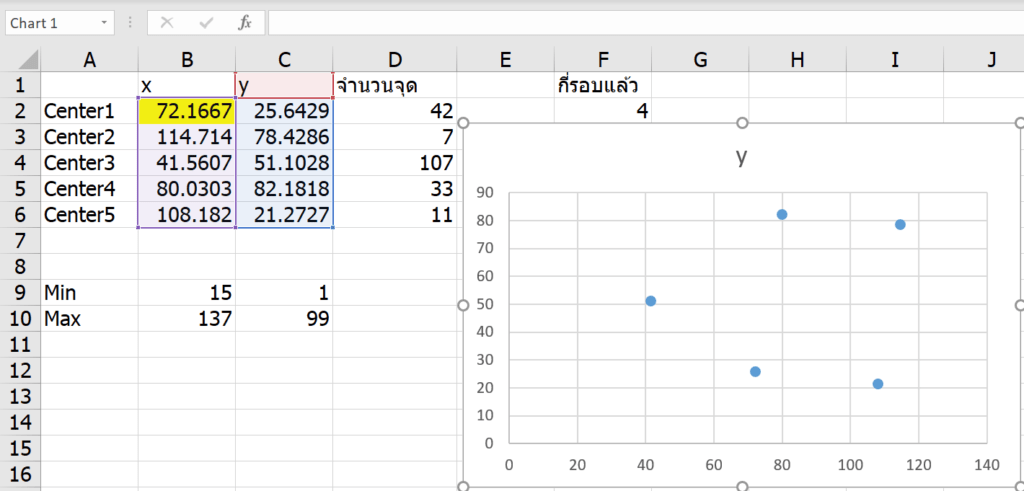
เราก็มาแก้สูตรของ Center แต่ละตัว ให้เป็นการเฉลี่ยภายในกลุ่มตัวเอง ซึ่งผมจะใช้ AVERAGEIFS มาช่วยครับ (สูตรนี้เป็นสูตรงูกินหาง เพราะกลุ่มก็คิดจากจุด Center แล้วจุด Center ดันคิดจากกลุ่มอีก)
คำนวณค่า X (ลาก B2:B6 ใส่สูตรแล้วกด Ctrl+Enter เพื่อใส่สูตรพร้อมกัน)
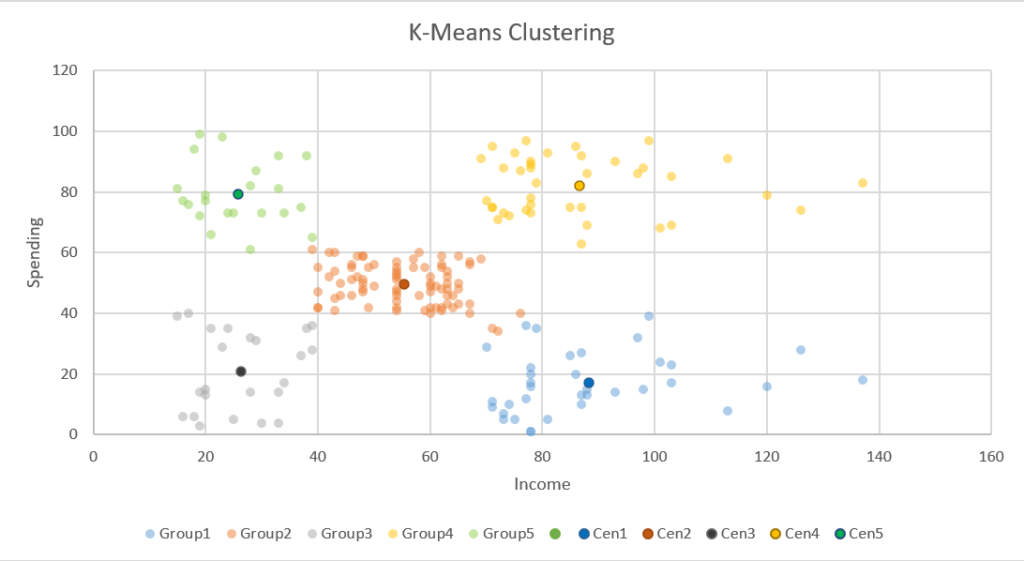
จากนั้นเราก็จะสามารถคำนวณ Group ต่างๆ ได้แล้ว ด้วยการ Add Column ดังนี้
คำนวณกลุ่มเรื่อง Recency
R Group =
VAR P20value=PERCENTILE.INC(customer_table[CustLastOrderDateNum],0.2)
VAR P40value=PERCENTILE.INC(customer_table[CustLastOrderDateNum],0.4)
VAR P60value=PERCENTILE.INC(customer_table[CustLastOrderDateNum],0.6)
VAR P80value=PERCENTILE.INC(customer_table[CustLastOrderDateNum],0.8)
RETURN SWITCH(TRUE(),
customer_table[CustLastOrderDateNum]<=P20value,1,
customer_table[CustLastOrderDateNum]<=P40value,2,
customer_table[CustLastOrderDateNum]<=P60value,3,
customer_table[CustLastOrderDateNum]<=P80value,4,
5)
Tips : จะเห็นว่าผมใช้ VAR มาช่วยประกาศตัวแปร เพื่อแบ่งสูตรออกเป็นส่วนๆ จะได้ลดความมึนงงลงได้ ตอนอ่านสูตรจะง่ายขึ้น นอกจากนี้ยังใช้ SWITCH + TRUE มาช่วยเขียนเงื่อนไขหลายเงื่อนไขแทนการใช้ IF ซ้อน IF ได้ด้วย
คำนวณกลุ่มเรื่อง Frequency
F Group =
VAR P20value=PERCENTILE.INC(customer_table[CustOrderCount],0.2)
VAR P40value=PERCENTILE.INC(customer_table[CustOrderCount],0.4)
VAR P60value=PERCENTILE.INC(customer_table[CustOrderCount],0.6)
VAR P80value=PERCENTILE.INC(customer_table[CustOrderCount],0.8)
RETURN SWITCH(TRUE(),
customer_table[CustOrderCount]<=P20value,1,
customer_table[CustOrderCount]<=P40value,2,
customer_table[CustOrderCount]<=P60value,3,
customer_table[CustOrderCount]<=P80value,4,
5)
คำนวณกลุ่มเรื่อง Monetary
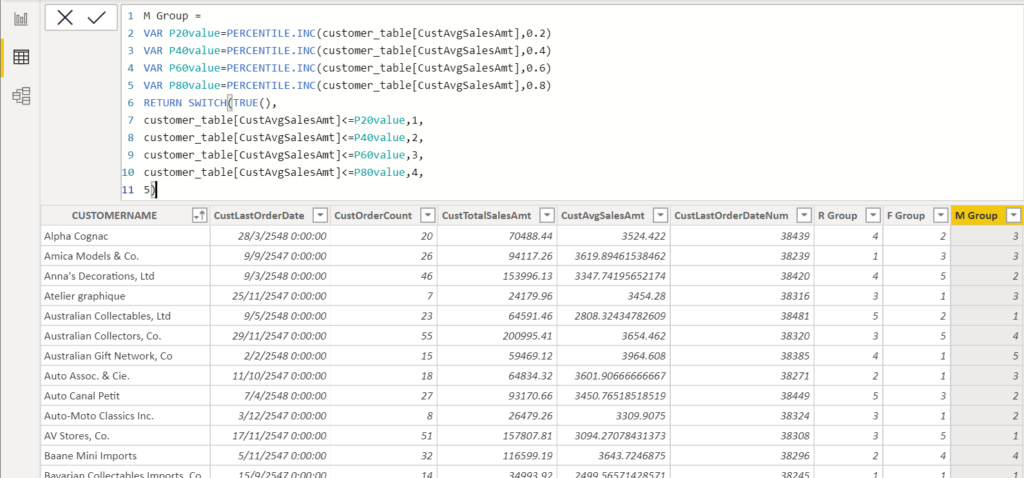
M Group =
VAR P20value=PERCENTILE.INC(customer_table[CustAvgSalesAmt],0.2)
VAR P40value=PERCENTILE.INC(customer_table[CustAvgSalesAmt],0.4)
VAR P60value=PERCENTILE.INC(customer_table[CustAvgSalesAmt],0.6)
VAR P80value=PERCENTILE.INC(customer_table[CustAvgSalesAmt],0.8)
RETURN SWITCH(TRUE(),
customer_table[CustAvgSalesAmt]<=P20value,1,
customer_table[CustAvgSalesAmt]<=P40value,2,
customer_table[CustAvgSalesAmt]<=P60value,3,
customer_table[CustAvgSalesAmt]<=P80value,4,
5)
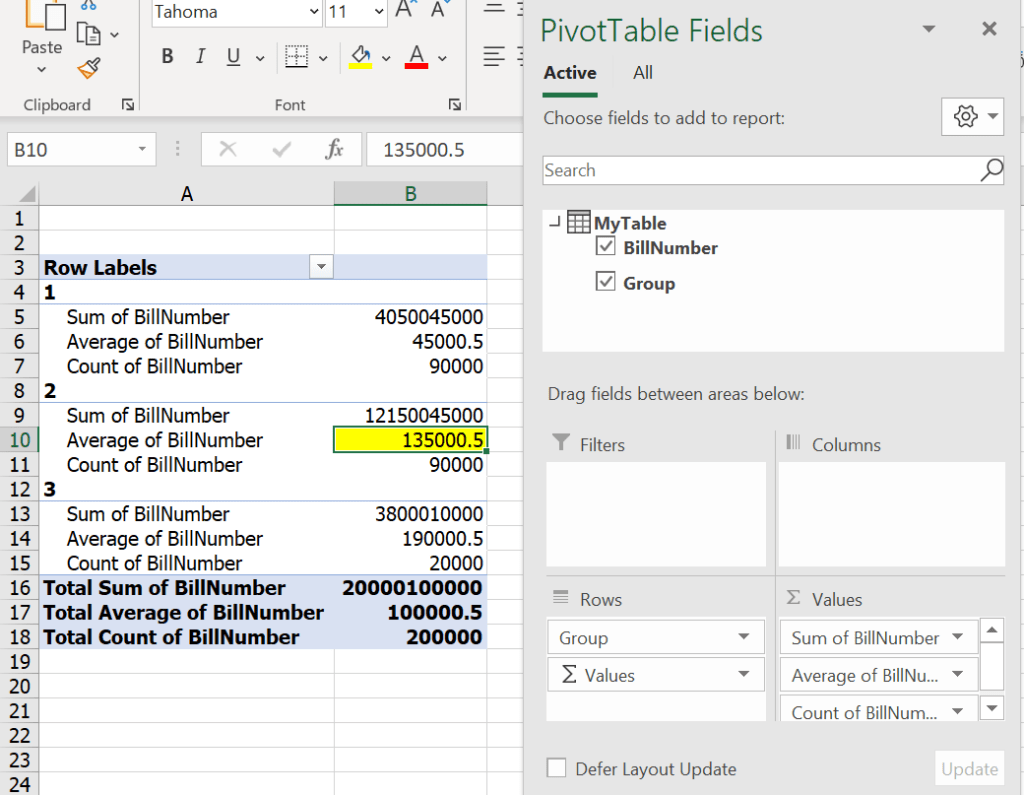
จะได้ผลลัพธ์ดังรูป
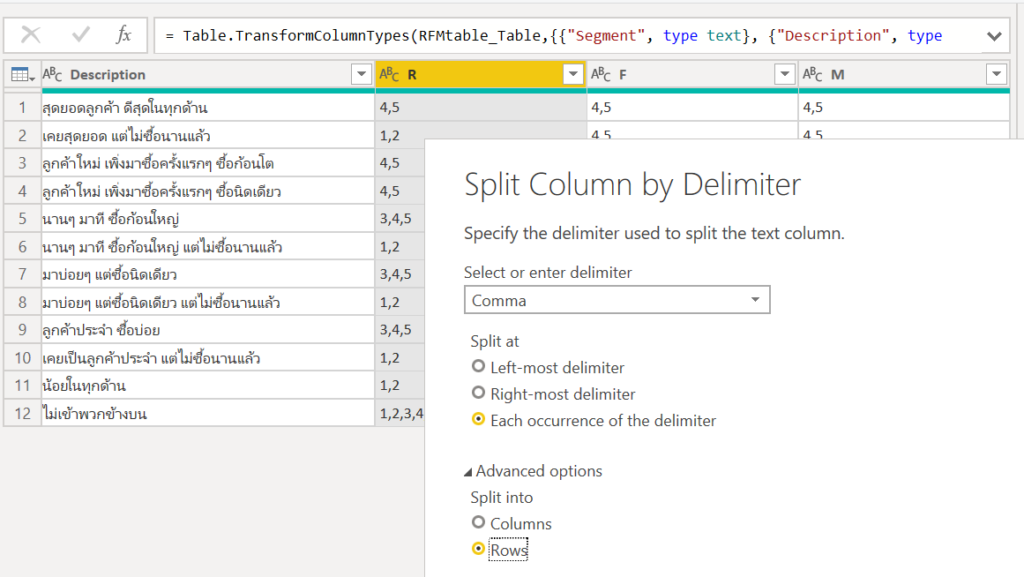
เตรียมตารางเกณฑ์การจัด RFM Segment
ต่อไปเราก็สร้างตารางอ้างอิงว่าคะแนนอะไรจะอยู่กลุ่มไหน โดยจะ Get Data จาก Excel ที่ทำไว้ในตอนที่แล้วก็ได้ ซึ่งหน้าตาใน Excel เป็นแบบนี้
หลักการคือ เราจะเอาข้อมูล r f m group ของลูกค้าแต่ละคน ไป Filter ตาราง RFMtable แล้วเอาผลลัพธ์ตัวบนสุดมา ซึ่งเราจะใช้ CACULATETABLE ในการ Filter เงื่อนไขก่อน (ใช้ FILTER ก็ได้ แต่ CALCULATETABLE จะคำนวณเร็วกว่า) แล้วใช้ TOPN เพื่อคัดมาแค่บนสุดแถวเดียวโดยยึดตาม index จากน้อยไปมาก จากนั้นค่อยเลือกเอาคอลัมน์ segment ออกมาด้วย SELECTCOLUMNS ดังนี้
สรุปคือ เรา Add New Column แล้วใส่สูตรดังนี้
StaticSegment =
VAR CurrentR=customer_table[R Group]
VAR CurrentF=customer_table[F Group]
VAR CurrentM=customer_table[M Group]
VAR filterTable=CALCULATETABLE(RFMtable,
RFMtable[R]=CurrentR,
RFMtable[F]=CurrentF,
RFMtable[M]=CurrentM)
VAR Top1=TOPN(1,filterTable,[Index],ASC)
VAR getSegment=SELECTCOLUMNS(Top1,"FilterSegment",[Segment])
RETURN getSegment
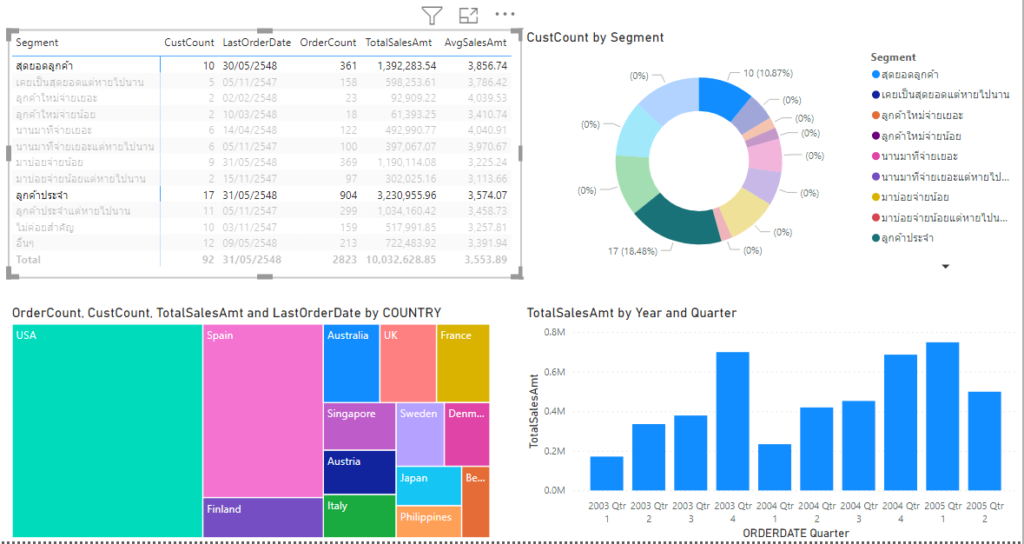
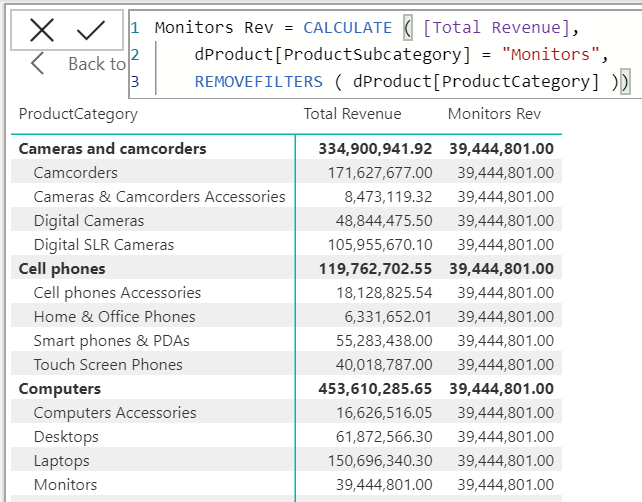
แต่เราจะแบ่งลูกค้ายังไงดีล่ะ? แบ่งตามอะไร? แค่แบ่งตามยอดซื้อเท่านั้นเหรอ? Model หนึ่งที่สามารถใช้ Data มาช่วยในการแบ่งกลุ่มลูกค้าได้นั่นก็คือ RFM Model หรือ RFM Analysis นั่นเอง
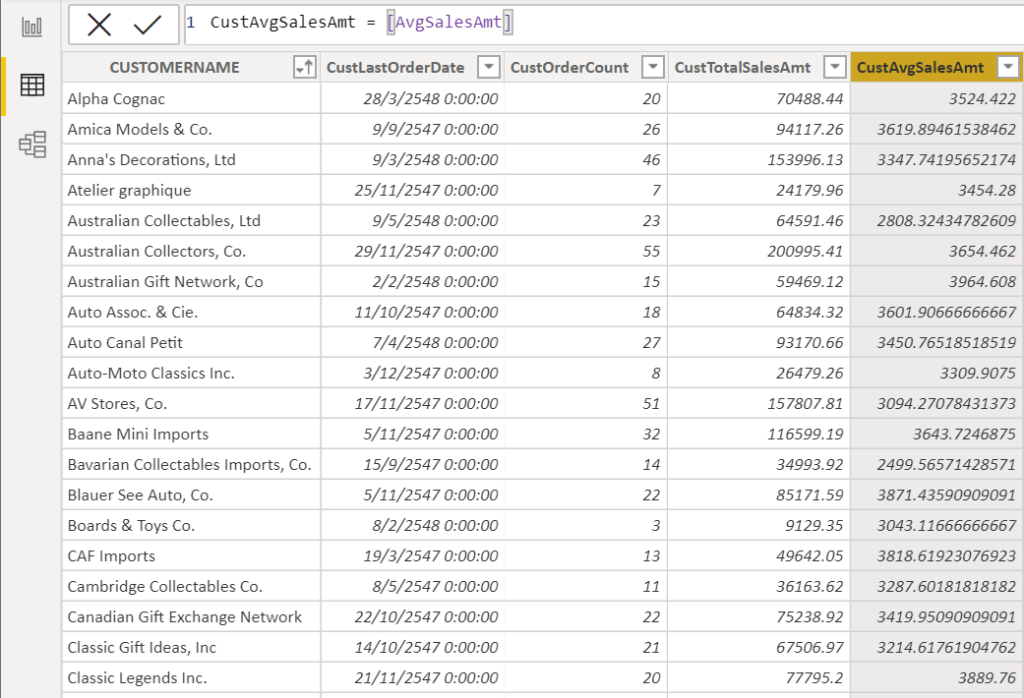
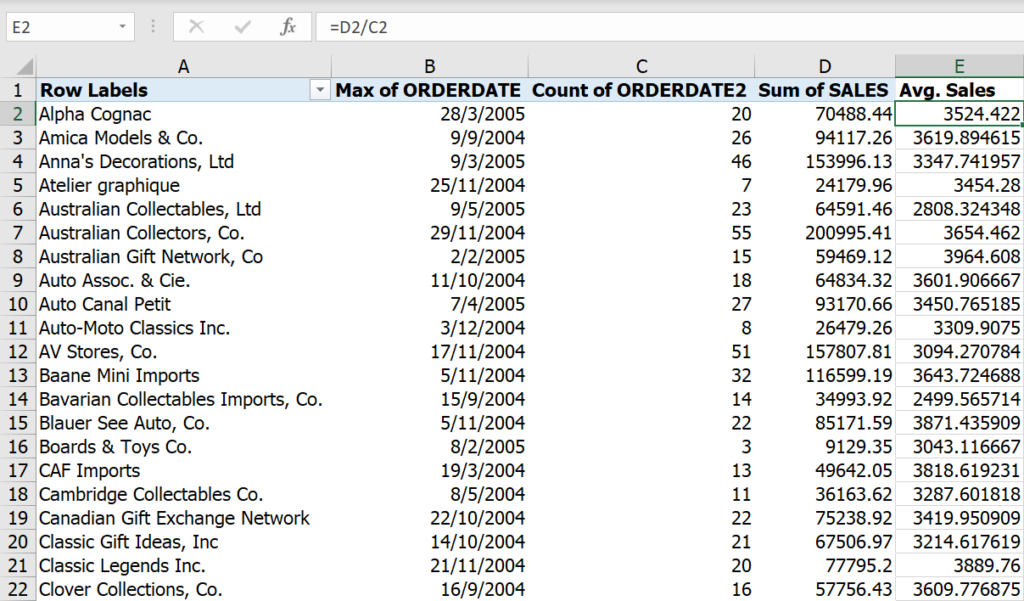
ผมลาก OrderDate ลงมา 2 รอบ ซึ่งมันจะทำการสรุปด้วย Count ให้ ผมจะเปลี่ยนให้สรุปด้วยการใช้ค่า Max แทน เพื่อให้ได้วันที่ล่าสุดที่ซื้อ (อย่าลืมว่าวันที่คือตัวเลข ดังนั้นหาค่า Max ได้) ส่วน OrderDate2 เป็นการนับซึ่งผมจะถือว่าเป็น Frequency การซื้อของลูกค้าคนนั้นไปซะ
การเปลี่ยนวันที่ในคอลัมน์ B เป็น MAX จะได้เลข 3 หมื่นเกือบ 4 หมื่นออกมา ซึ่งมันคือค่าที่แท้จริงของวันที่ เราแค่กดคลิ๊กขวา Number Format แล้วเปลี่ยน Format เป็นวันที่ได้เลย ส่วนยอดเงินเฉลี่ยต่อครั้งในคอลัมน์ E ก็เกิดจากการเอายอดเงินรวมหารด้วยจำนวนครั้งที่ซื้อครับ (อันนี้ใช้วิธีหารเอาข้างๆ แบบลูกทุ่งเลย ในความเป็นจริงจะใช้ Calculated Field หรือ Measure ก็ได้นะครับ)
ที่นี้เราก็ได้ค่า R F M แล้วดังนี้
แบ่งคะแนนด้วยวิธีไหนดี?
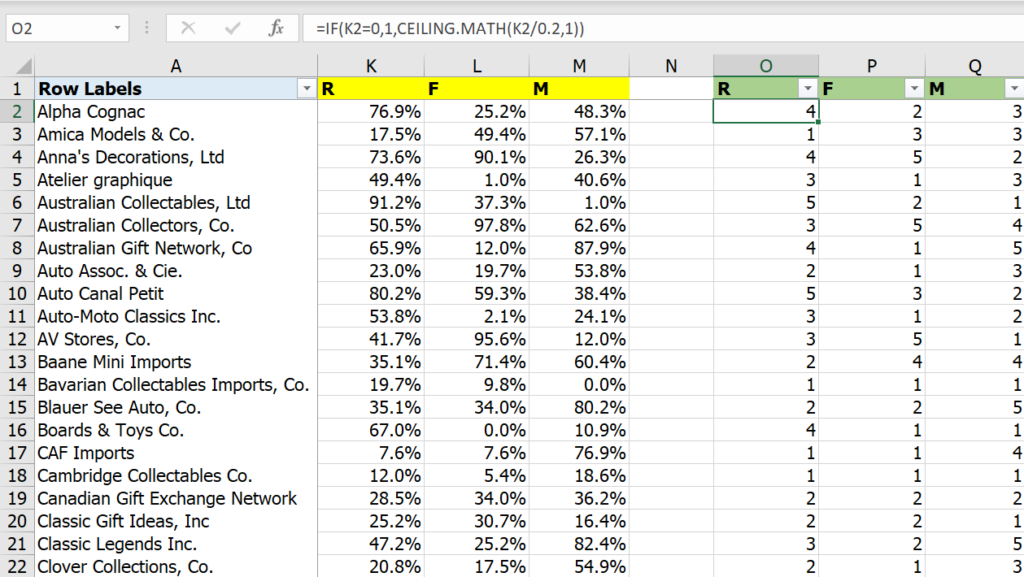
หากเราเอาแค่ค่าน้อยสุดมากสุดมาแบ่งเป็น 5 ท่อนเฉยๆ มันจะไม่ Work อย่างแรง เนื่องจากข้อมูลมันเบ้ขวามากๆ ทำให้แต่ละท่อนมีข้อมูลต่างกันมากเลย ดังนั้นวิธีที่น่าจะ Work ที่สุดก็คือการหาค่า Percentile ที่ 20,40,60,80 มาเป็นตัวแบ่งนั่นเอง
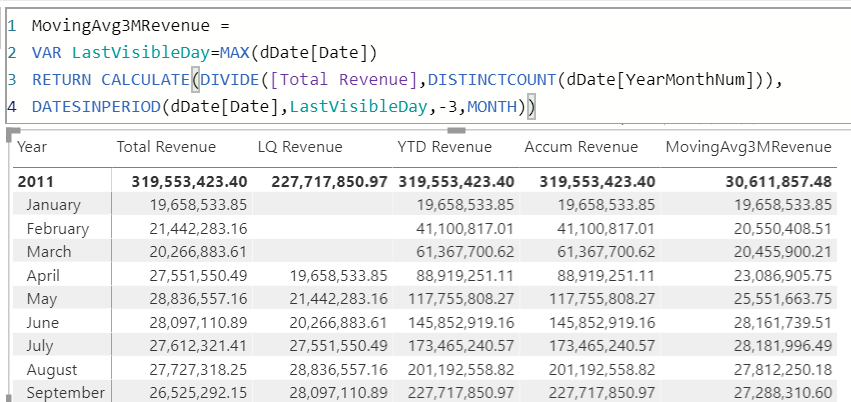
ในตอนต่อไป ผมจะทำด้วยวิธีใช้ DAX ใน Power BI ซึ่งจะสามารถเขียน Measure ออกมาคำนวณให้ได้ผลลัพธ์ที่ต้องการได้แบบอัตโนมัติกว่านี้ครับ ใครสนใจก็รอติดตามได้เลยครับ
ภาษา DAX (Data Analysis eXpression) เป็นภาษาที่ใช้ในการเขียนสูตรของ Power BI และ Power Pivot ซึ่งเป็นภาษาที่มีหน้าตาภายนอกคล้ายคลึงสูตรของ Excel มากๆ แต่เบื้องลึกนั้นอาจมีความต่างพอสมควร…
Concept การทำงานของ DAX นั้นจะผูกโยงกับ Data Model หรือโครงสร้างความสัมพันธ์ของข้อมูลในตาราง และขึ้นอยู่กับบริบทของการ Filter ข้อมูลเป็นอย่างมาก ดังนั้นคนที่ใช้ Excel มาก่อนจำชำนาญแล้ว ก็ยังจำเป็นต้องศึกษา DAX เพิ่มเติมอีกเยอะเลยกว่าจะใช้ได้ DAX ได้เก่ง
ป.ล. 10 ขั้นที่เขียนนี้พูดแค่เรื่องในมิติของ DAX เท่านั้นนะครับ ซึ่งไม่ได้รวมถึงเรื่องสำคัญอื่นๆ ใน Power BI เช่น Power Query / Data Model / ส่วน Report Visualization นะครับ ซึ่งยังต้องเก่งเรื่องพวกนี้อีกถึงจะใช้ Power BI ได้เต็มที เฮ้อ…เหนื่อย! (แต่มันคุ้มนะ เพราะมันเจ๋งมากจริงๆ)
ส่วนตัวผมเองคิดว่าจะนำลำดับขั้นเหล่านี้ไปปรับปรุงคอร์ส Power BI ของผมให้ดียิ่งขึ้นด้วยครับ และน่าจะเป็นแนวทางที่ดีในการพัฒนาคอร์ส DAX Advance ในอนาคตด้วยครับ ^^
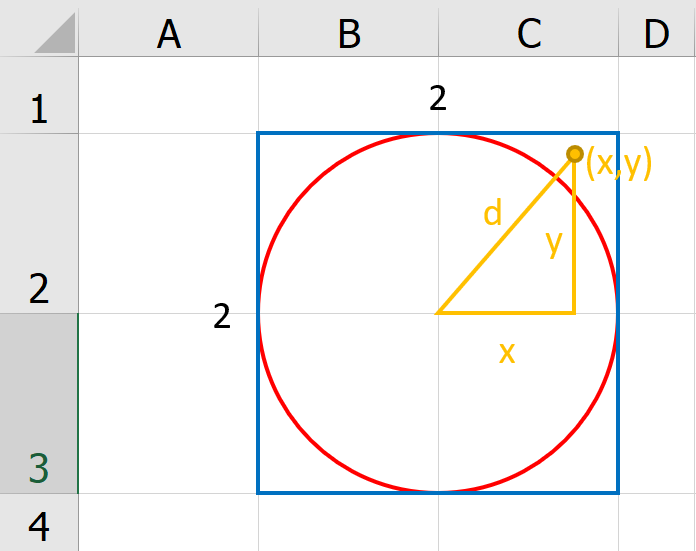
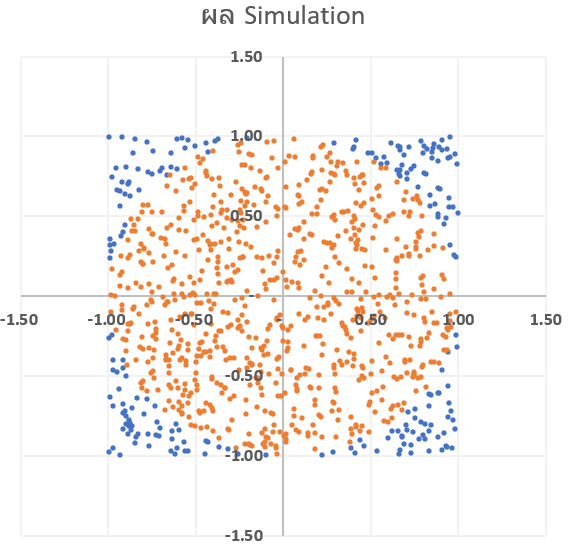
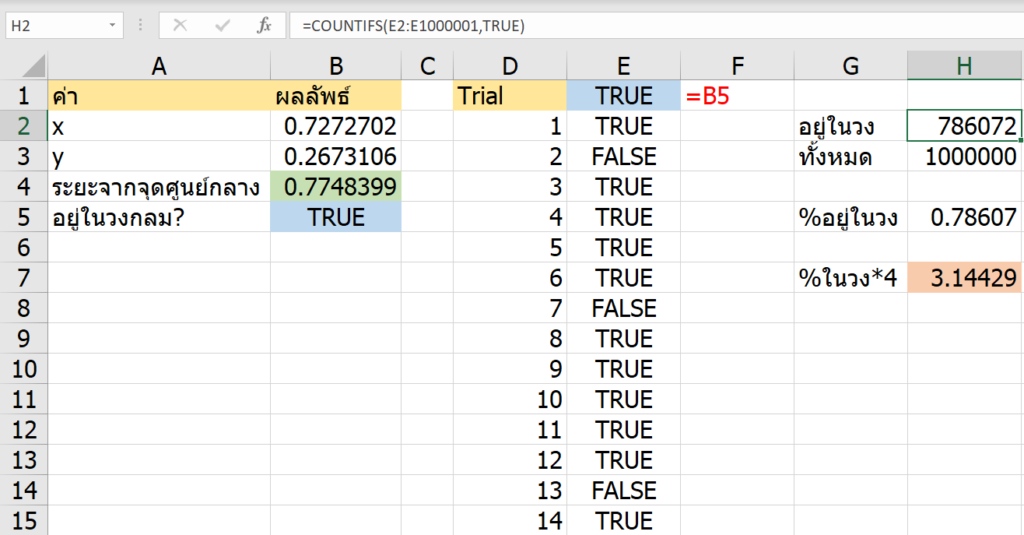
ซึ่งถ้าเราสุ่มจำนวนครั้งมากพอ แล้วหาอัตราส่วนว่ามันอยู่ในวงกลมกี่ % เราก็จะหาค่า Pi ได้ในที่สุดครับ ซึ่งการทำ Simulation จากการสุ่มมีชื่อเรียกว่า Monte Carlo Simulation นั่นเองครับ
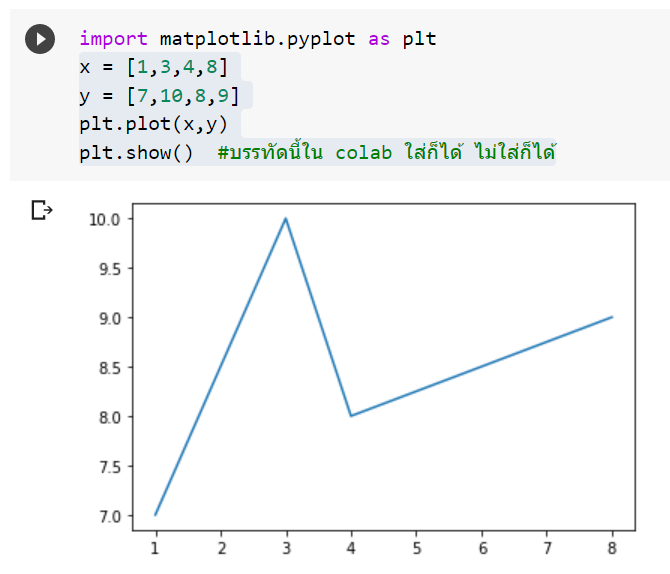
ซึ่งความรู้ทั้งหมดนี้นี่จะช่วยให้พวกเราสามารถสร้างกราฟหน้าตาแปลกๆ ขึ้นมาใช้เองด้วยการเรียกใช้ Python Script ใน Power BI ได้ด้วยนะครับ ดังนั้นเรียนรู้ไว้ไม่เสียหายแน่นอน
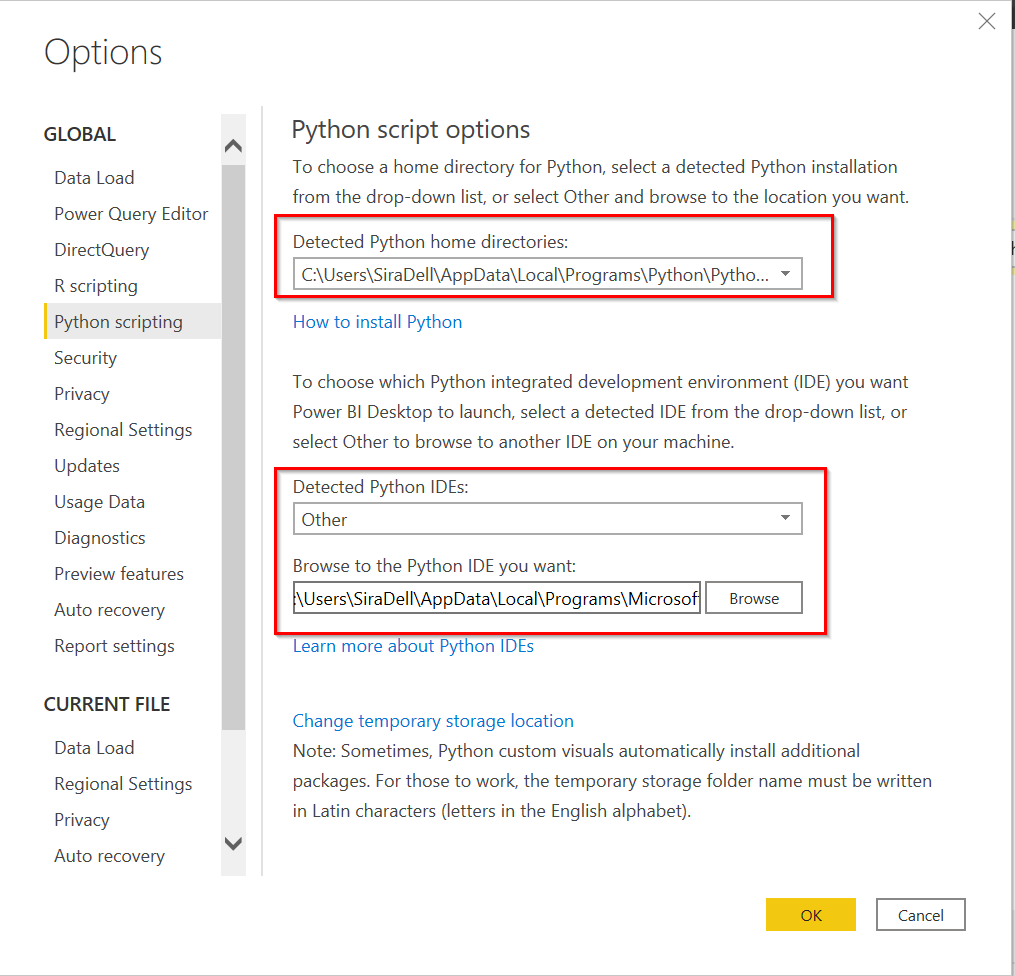
พอ Install ทุกอย่างที่จำเป็นหมดแล้ว ก็เข้าโปรแกรม Power BI ได้ ซึ่งเมื่อลองเข้าไปใน Option จะเห็นว่า มันมองเห็น Python ที่เรา Install ลงในเครื่องแล้ว
ส่วนเรื่องของ IDE จะปล่อยเป็นค่า Default ก็ได้ แต่ของผมเลือก Other แล้ว browse ไปที่ Microsoft Visual Studio Code ตามตำแหน่งนี้ C:\Users\ชื่อUser\AppData\Local\Programs\Microsoft VS Code\Code.exe
ใช้ Python ในขั้นตอน Get Data
เราจะลองใช้ Python ในขั้นตอนของการ Get Data โดยไปที่ Get Data -> More…-> Other -> Python Script
import pandas as pd
TestVar1=pd.read_csv("https://raw.githubusercontent.com/ThepExcel/download/master/ThepExcelsample.csv")
data = {'แอปเปิ้ล': [1, 3, 6, 8],'มะละกอ': [10, 30, 50, 90]}
TestVar2=pd.DataFrame(data)
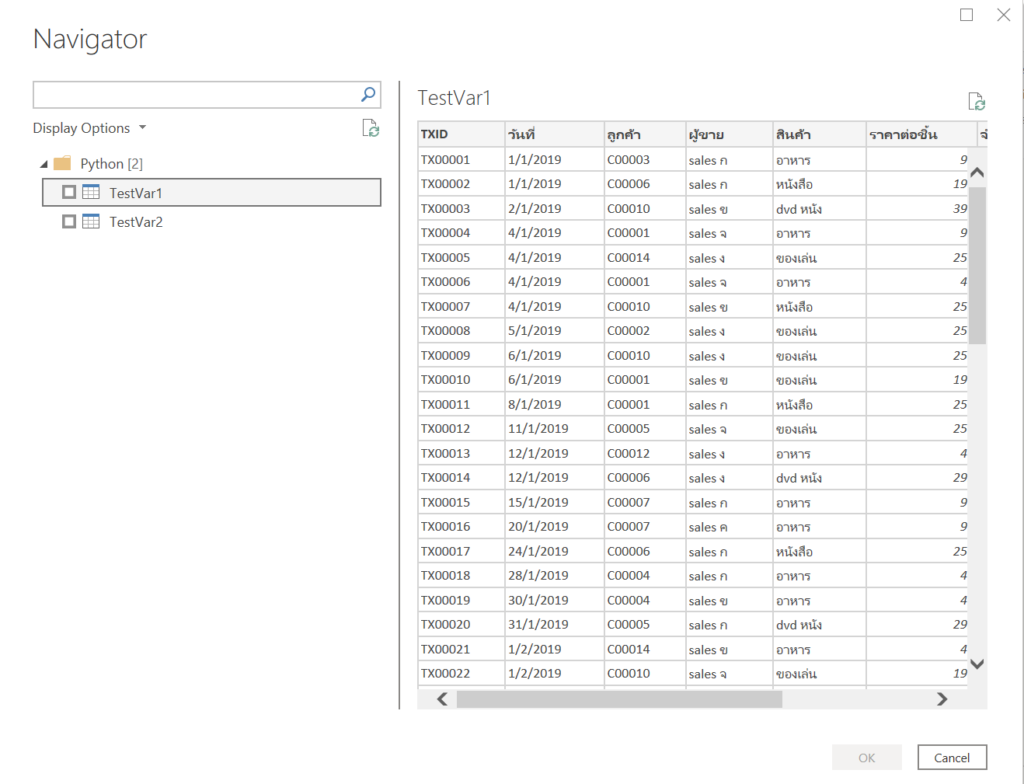
พอกด ok จะเห็นเป็น 2 Object ดังนี้ (สังเกตว่ามองไม่เห็นตัวแปร data ที่เป็น Dictionary)
ให้เลือก TestVar1 แล้วกด Transform เพื่อทำงานต่อ
สังเกตว่าใน step Source จะมีคำสั่ง = Python.Execute( xxxx ) โผล่มา ซึ่งคำสั่งนี้ใช้ได้ใน Power Query ของ Power BI เท่านั้น ไม่สามารถเอาไปใช้ใน Power Query ของ Excel ได้นะครับ
ใช้ Python ในขั้นตอน Transform
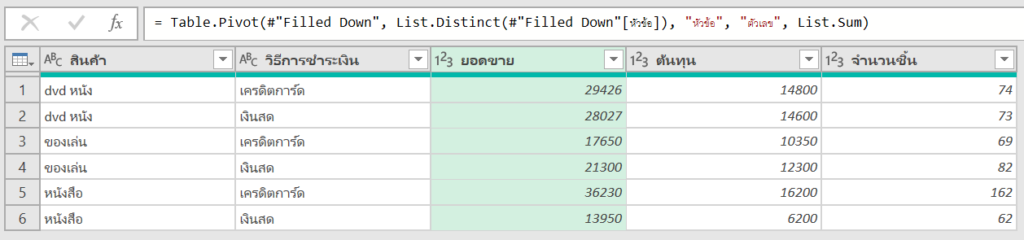
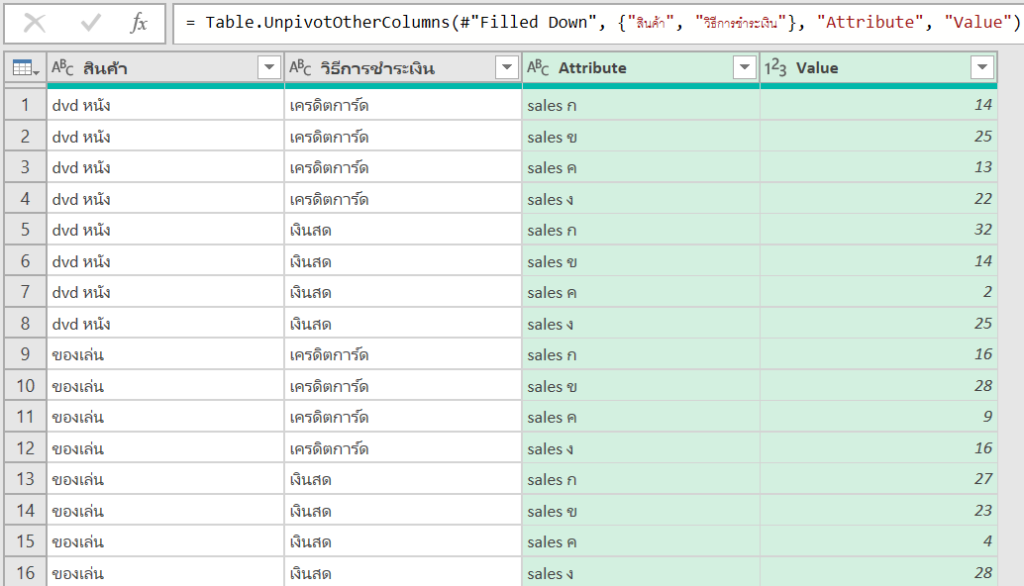
พอ Load Data เข้ามาได้แล้ว เราก็สามารถ Transform โน่นนี่นั่นใน Power Query Editor ได้ตามปกติเลย เช่น ในที่นี้ผมจะ Filter ผู้ขายเป็น sales ก เท่านั้น
จากนั้นเวลาเราจะใช้ Python ทำงานต่อ เราสามารถไปที่ Transform -> Run Python Script ได้
จากนั้นมันจะมี comment บอกว่า #’dataset’ holds the input data for this script นั่นก็แปลว่าตัวแปรชื่อว่า dataset เป็นตัวเก็บข้อมูลก่อนที่จะ run Script ล่าสุดนี้นั่นเอง
เช่น ถ้าผมเขียนใน Script ว่า
#'dataset' holds the input data for this script
dataset2=dataset.copy() #ลองสร้าง data เป็นอีกตัวนึง
dataset2['ยอดขาย']=dataset2['ราคาต่อชิ้น']*dataset2['จำนวนชิ้น'] #สร้างคอลัมน์ยอดขาย
ถ้ามันขึ้นเตือนเรื่อง Privacy ให้เลือกทุกอันเป็น Public ให้หมดแล้วกด ok
สรุปแล้ว เราสามารถใช้ Python ได้ตั้งแต่ขั้นตอน Get Data / Transform Data และ การทำ Visual ด้วยเลย ซึ่งหากใช้ Python ได้คล่องๆ ก็จะทำอะไรได้มากกว่าที่ Power BI ปกติทำได้อีกมาก ที่ผมคิดว่าเหมาะ เช่น การทำ Web Scrapping รวมถึงการใช้ Regex แบบซับซ้อน เป็นต้น (แต่ตัวอย่างนี้ยังไม่ได้แสดงถึงจุดนั้น)
ในบทความนี้ผมจะมาสอนการใช้งานเจ้า INDEX กับ MATCH แบบสั้นๆ ไม่ได้เจาะลึกอะไรมากมาย (ถ้าจะลงลึกเรื่อง INDEX อ่านได้ที่นี่) แต่สามารถเอาไปใช้ได้เลยละกันนะครับ เน้นเอาใจคนมีเวลาน้อย อิอิ
ถ้าถามว่าสูตรในส่วนนี้เขียนยังไง ผมจะบอกว่าอันนี้เป็นเรื่องอื่นที่ไม่เกี่ยวกับ IF โดยสิ้นเชิงเลย ถ้าคุณไม่มีความรู้เรื่องการเขียนสูตรอื่นๆ ก็จะทำ Part นี้ไม่ได้ครับ ดังนั้นให้ไปฝึกฝนเรื่องอื่นๆ ด้วย เช่น ในตัวอย่างนี้มีการใช้ INT หรือจะใช้ ROUNDDOWN ก็ได้ แต่ถ้าไม่รู้จักเลยก็จะทำโจทย์นี้ไม่ได้นั่นเอง ซึ่งจะเห็นว่าไม่ได้เกี่ยวกับ IF เลยนะครับ
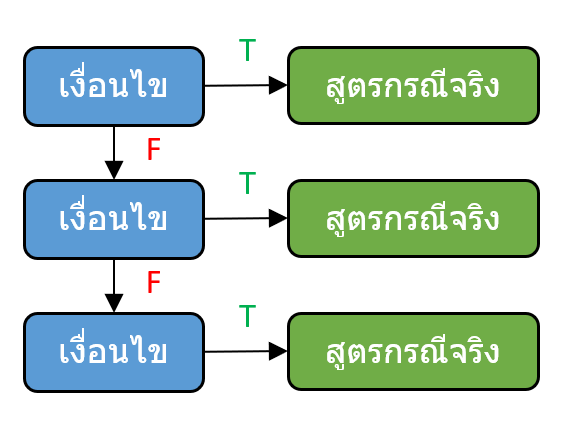
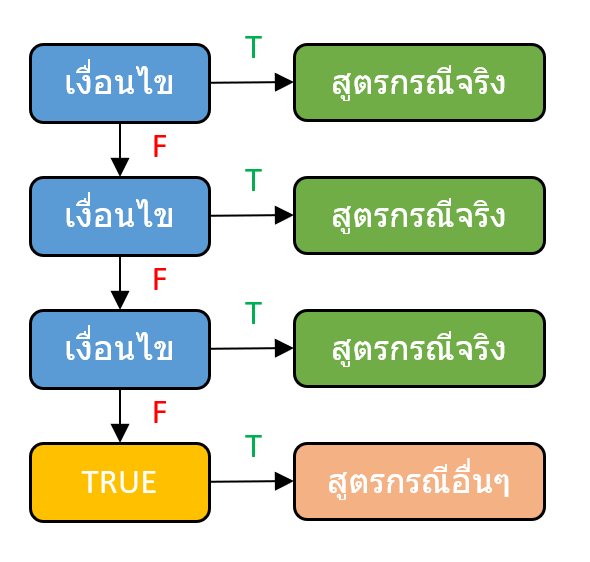
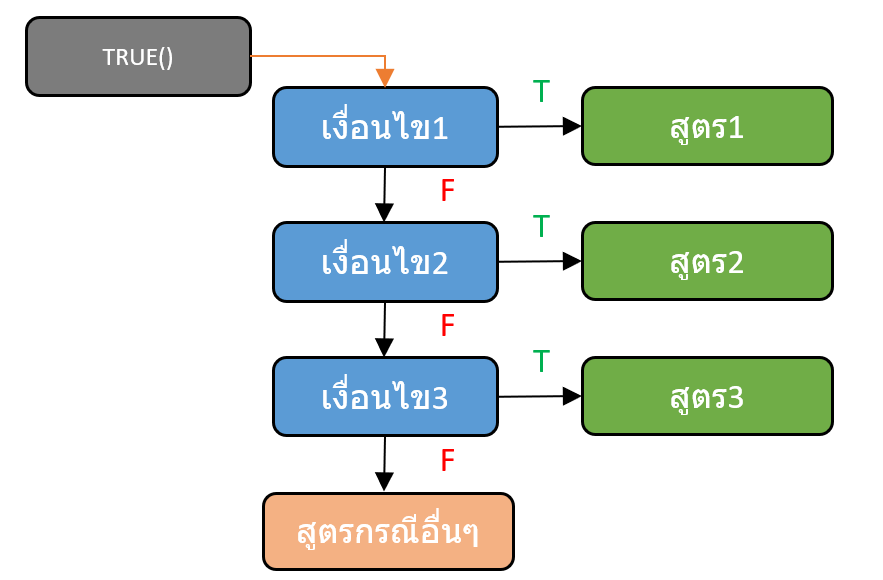
แล้วถ้าผลลัพธ์มีมากกว่า 2 กรณีล่ะ?
อย่างที่ผมบอกไปก่อนหน้านี้ว่า IF สามารถแสดงผลลัพธ์ได้ 2 กรณี หลายคนอาจะสงสัยว่า แล้วถ้าผลลัพธ์มีมากกว่า 2 กรณีล่ะ? จะทำไง?
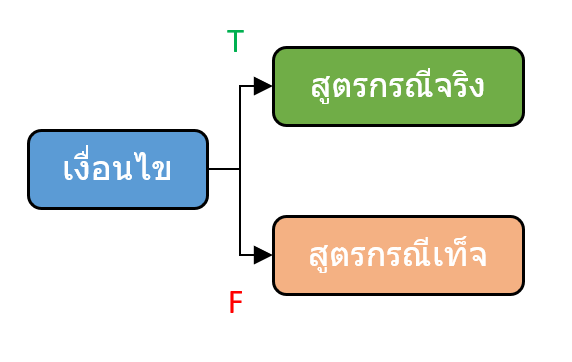
โดยที่ผมจะขอเริ่มจากตัวที่เป็นพื้นฐานที่ใช้ได้ทุก version นั่นก็คือ IF ซ้อนกัน ซึ่งวิธีทำก็คือใส่ IF ลงไปอีกชุดนึงเลยในส่วนที่เป็น value_if_true หรือ value_if_false ก็ได้ (หรือทั้งคู่ก็ได้)
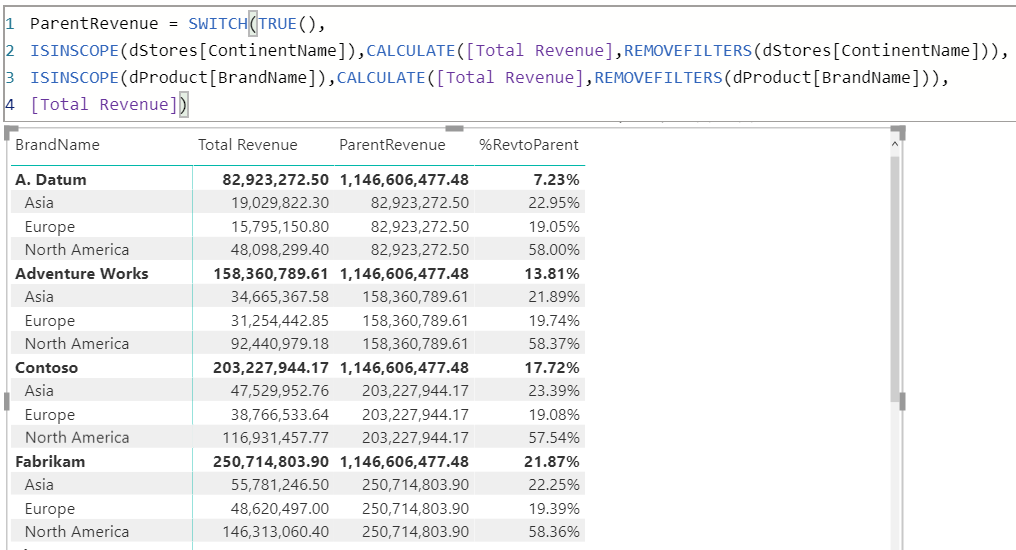
หมายเหตุ : หาก Field ที่เราตั้งใจจะปลด Filter นั้นมีการ Sort by Column อื่นอีก เราก็ต้องปลด Column ที่ไปอ้างอิงการ Sort ด้วยนะ
Calculate กับเงื่อนไข Filter บน Field Date
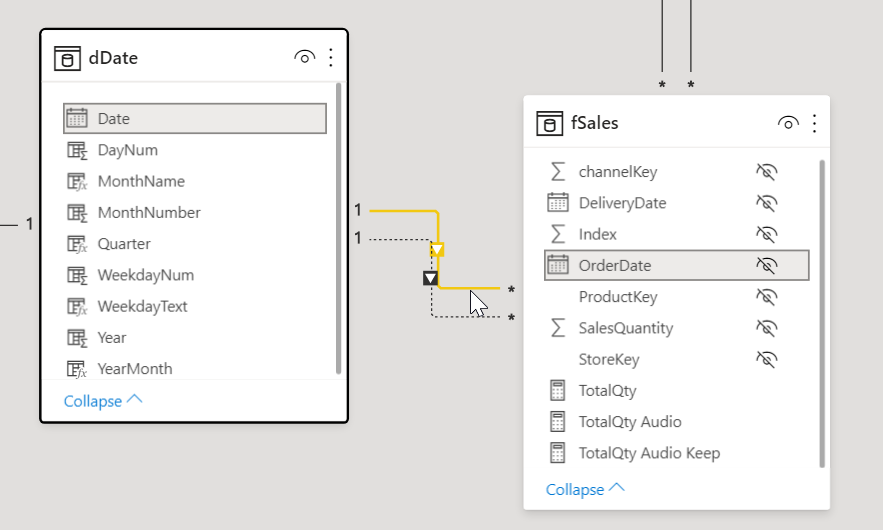
จากที่ผมได้บอกไปก่อนหน้าว่าเวลาจะปลด Filter นั้นจะต้องปลดให้ตรงกับ Field ที่มีการ Filter อยู่ แต่มันมีกรณียกเว้นคือ หากเราไปอ้างอิงคอลัมน์ Date ของตารางวันที่ใน Data Model มันจะเป็นการปลด Filter ออกทั้งตารางวันที่เลย เช่น
วิธีที่ช่วยได้คือ การแก้ทิศทางเส้น Relationship ให้เป็นแบบ Bi-Directional (2 ทิศทาง) ซึ่งผมแนะนำว่าไม่ควรไปแก้ที่ Data Model โดยตรงเพราะมีความเสี่ยงที่ทำให้เกิดความกำกวมของ Model ว่าจะ Filter ตารางจากทิศทางไหนดี
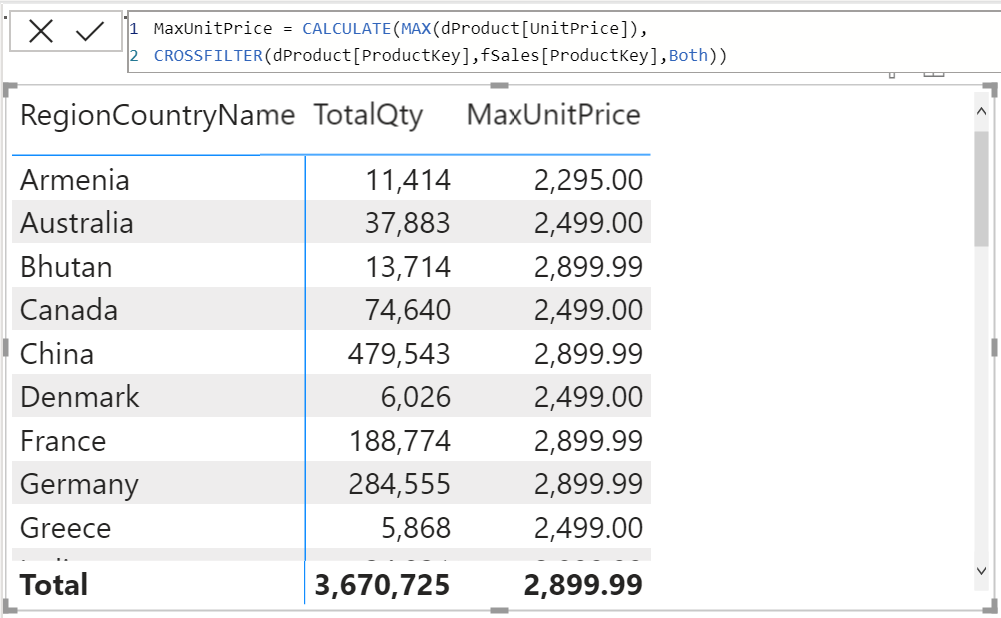
วิธีที่ผมขอแนะนำคือ ให้เปลี่ยนทิศทาง FILTER ด้วย CALCULATE + CROSSFILTER โดยเลือก Direction เป็น Both ดังนี้
ซึ่งเราก็นำไปใช้กับกรณี Split into Rows ได้เช่นกัน
จาก Code ที่มัน Gen มาให้แบบนี้ (ซึ่งซับซ้อน ช่างมันไปก่อน) เราจะสนใจแค่การแก้ตรง SplitTextByDelimiter เหมือนเดิม
= Table.ExpandListColumn(Table.TransformColumns(Source, {{"ผู้เล่น", Splitter.SplitTextByDelimiter(",", QuoteStyle.Csv), let itemType = (type nullable text) meta [Serialized.Text = true] in type {itemType}}}), "ผู้เล่น")
สรุปแล้วให้ แก้ Code กลายเป็นแบบนี้
= Table.ExpandListColumn(Table.TransformColumns(Source, {{"ผู้เล่น", Splitter.SplitTextByAnyDelimiter({",",";","|","และ"}, QuoteStyle.Csv), let itemType = (type nullable text) meta [Serialized.Text = true] in type {itemType}}}), "ผู้เล่น")
เทคนิค Group by แล้วรวมข้อความที่เป็น Text คั่นด้วย Delimiter
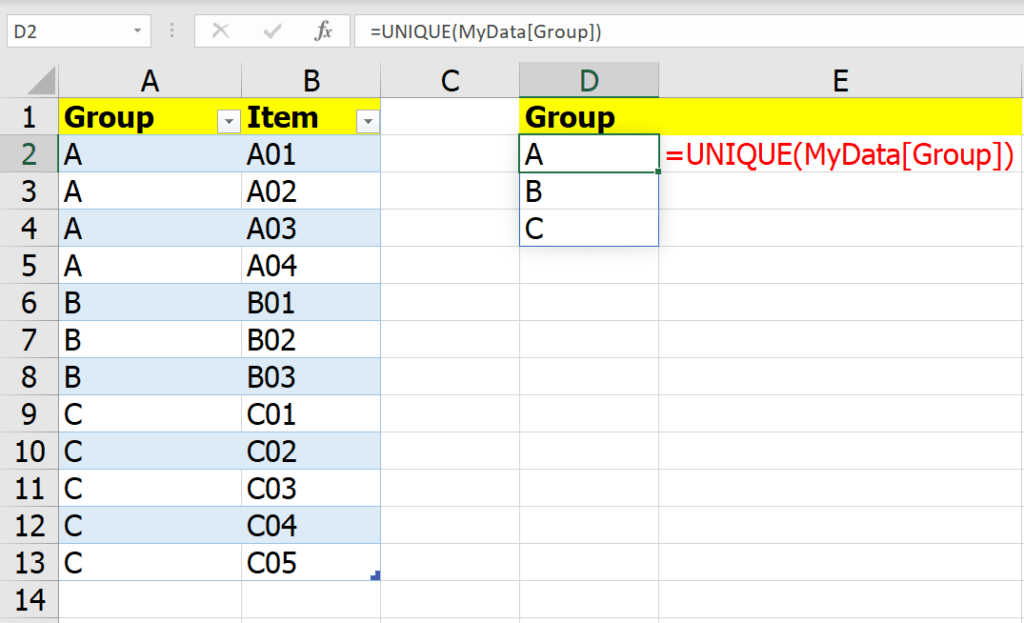
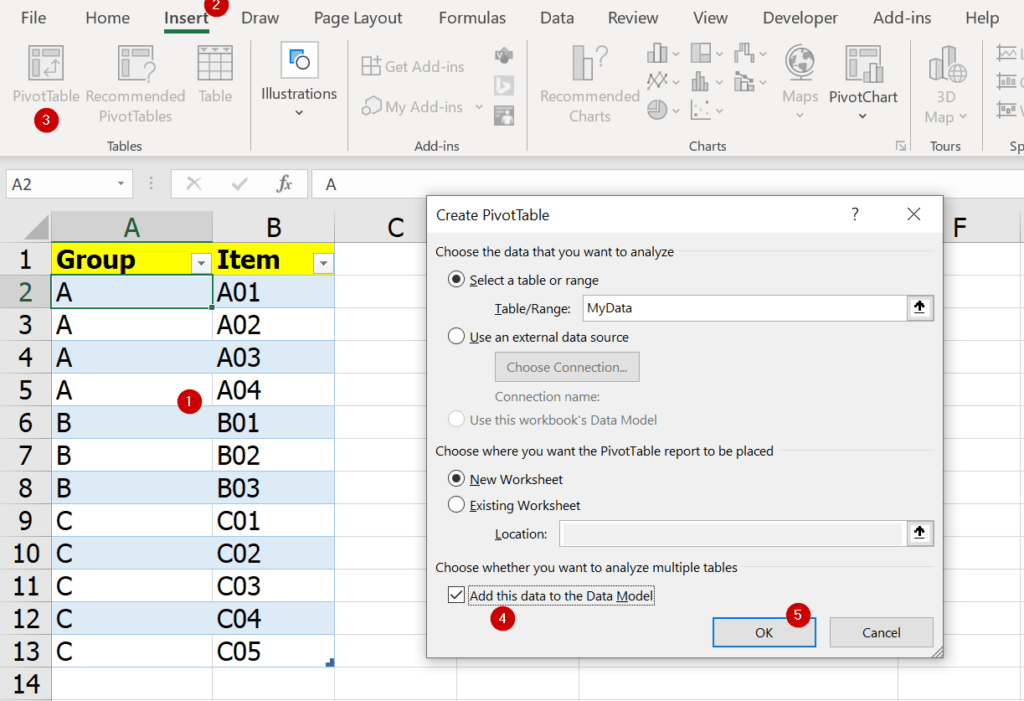
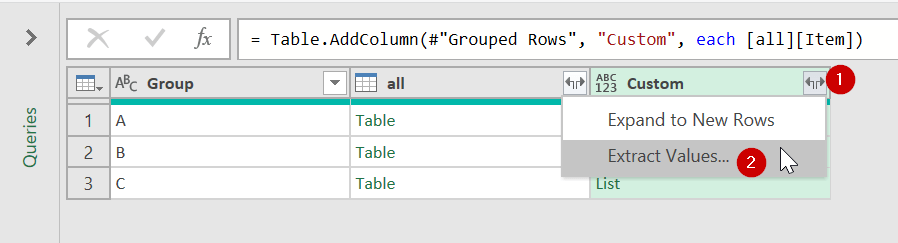
สมมติเรามีข้อมูลดังนี้
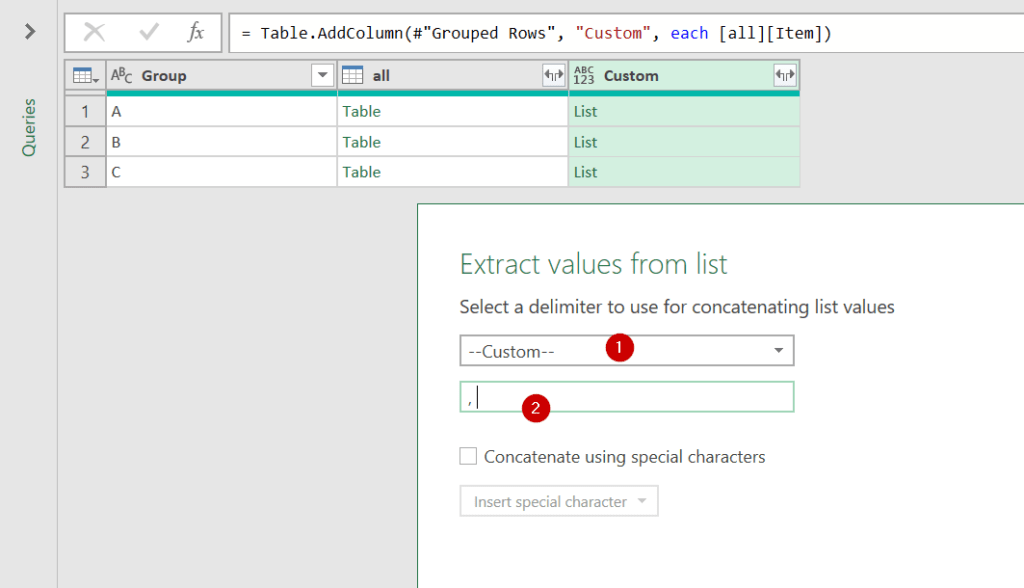
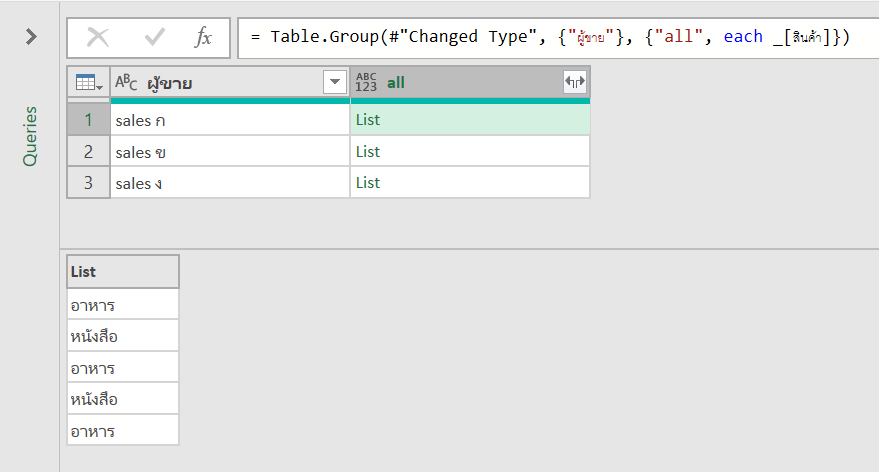
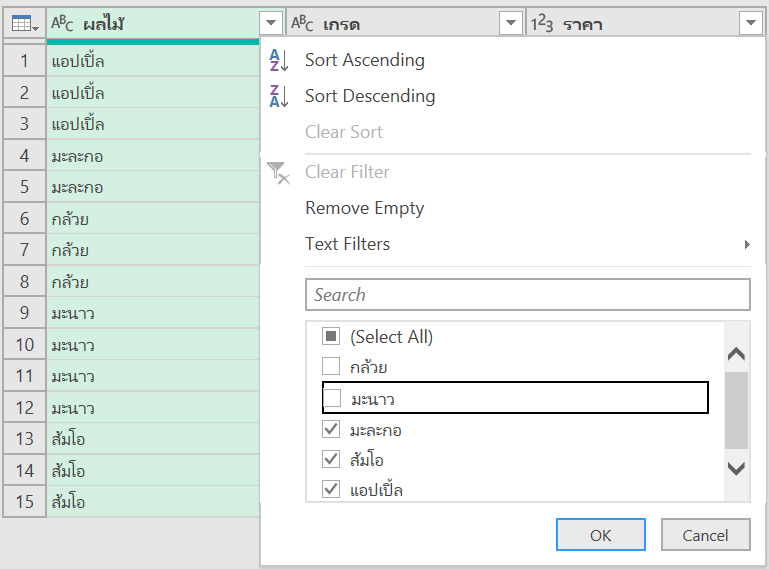
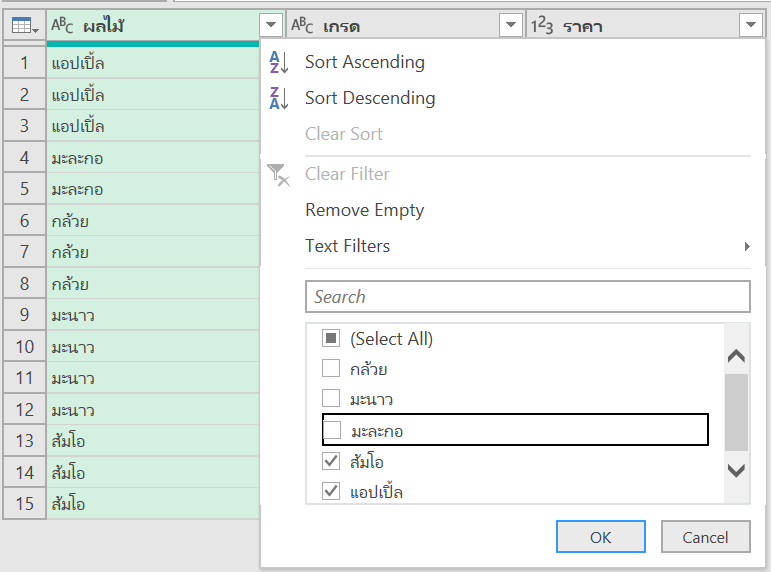
เราจะ Group by ตามผู้ขาย แต่อยากได้รายชื่อสินค้าเอามารวมแล้วคั่นด้วยเครื่องหมาย / จะทำยังไง?
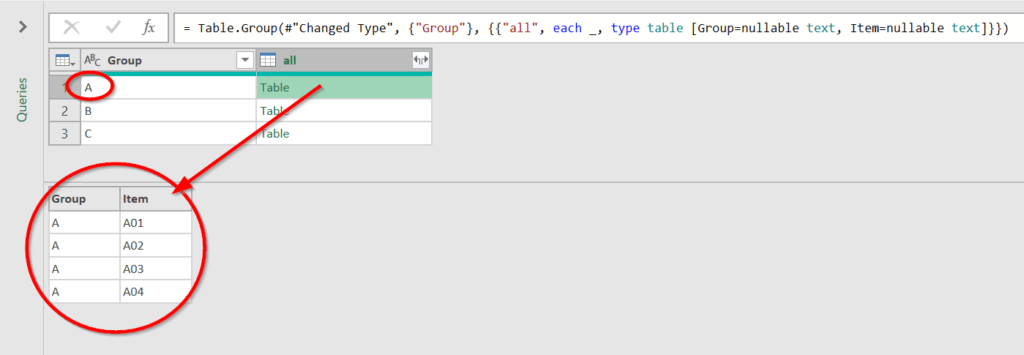
เราสามารถใช้การ Group ที่เรียกว่า All Rows มาช่วยได้ เช่น
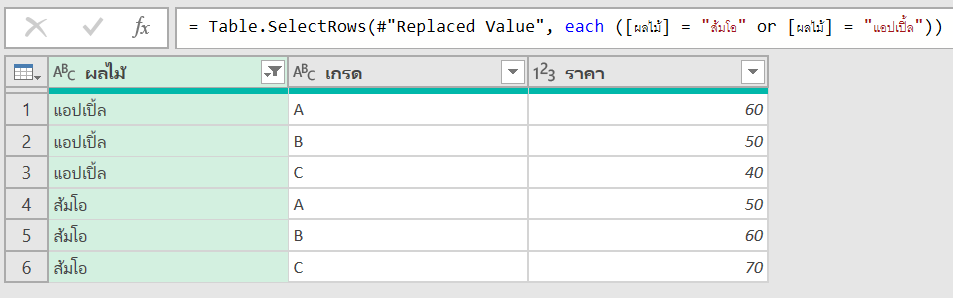
จากนั้นจะได้ผลลัพธ์แบบนี้
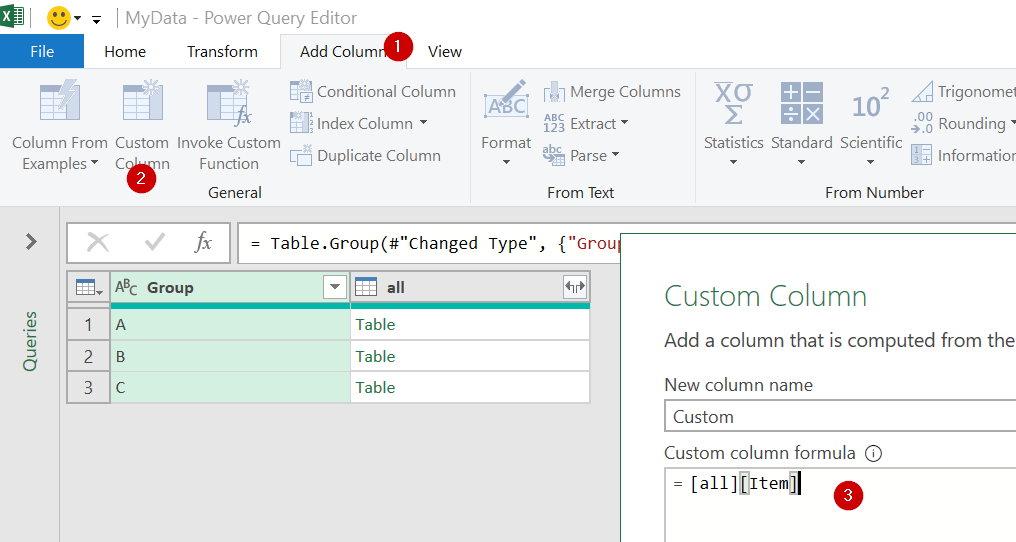
concept คือเหมือนเดิม ว่า _ คืออ้างอิงตารางทั้งตารางที่ผ่านการ Group มาแล้ว ดังนั้นผมสามารถแก้สูตรให้ย่อๆ เหลือแค่นี้ก็ได้ ซึ่งก็จะได้ผลลัพธ์เหมือนเดิมเลย
= Table.Group(#"Changed Type", {"ผู้ขาย"}, {"all", each _})
= Table.TransformColumns(#"Grouped Rows", {"all", each Text.Combine(List.Transform(_, Text.From), "/"), type text})
เทคนิคการ Group by แล้วนับค่าในคอลัมน์แบบไม่ซ้ำ
จาก Data ในเทคนิคที่แล้ว หากเราจะสั่ง Group by ผู้ขาย และจะนับจำนวนลูกค้าแบบไม่ซ้ำกัน เราจะพบว่าไม่สามารถใช้ Count Distinct Rows ใน Group by เพื่อเลือกคอลัมน์ลูกค้าได้สาเหตุเป็นเพราะ Count Distinct Rows ใน Group by เอาไว้นับจำนวนบรรทัดแบบไม่ซ้ำ (โดยดูทั้งบรรทัดเท่านั้น)
= Table.Group(#"Changed Type", {"ผู้ขาย"}, {{"Count", each Table.RowCount(List.Distinct(_[ลูกค้า])), Int64.Type}})
เทคนิคการ Trim แบบให้ทำให้ช่องว่างตรงกลางเหลือแค่ 1 เคาะ
หลายคนอาจไม่ได้สังเกต ว่า Trim ใน Power Query นั้น จะตัดข้อมูลได้แค่ด้านหน้ากับด้านหลังเท่านั้น ไม่สามารถจะเอาข้อมูลช่องว่างตรงกลางออกไปได้ (ต่างจาก TRIM ใน Excel)
ดังนั้นถ้าอยากให้ใน Power Query มัน Trim ได้แบบเดียวกับใน Excel จะต้องมีการแก้ Code ดังนี้
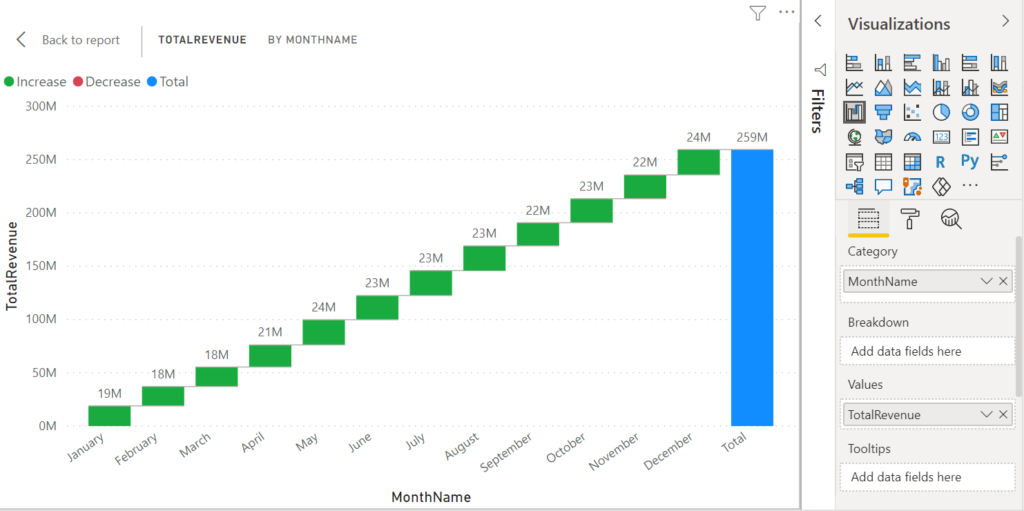
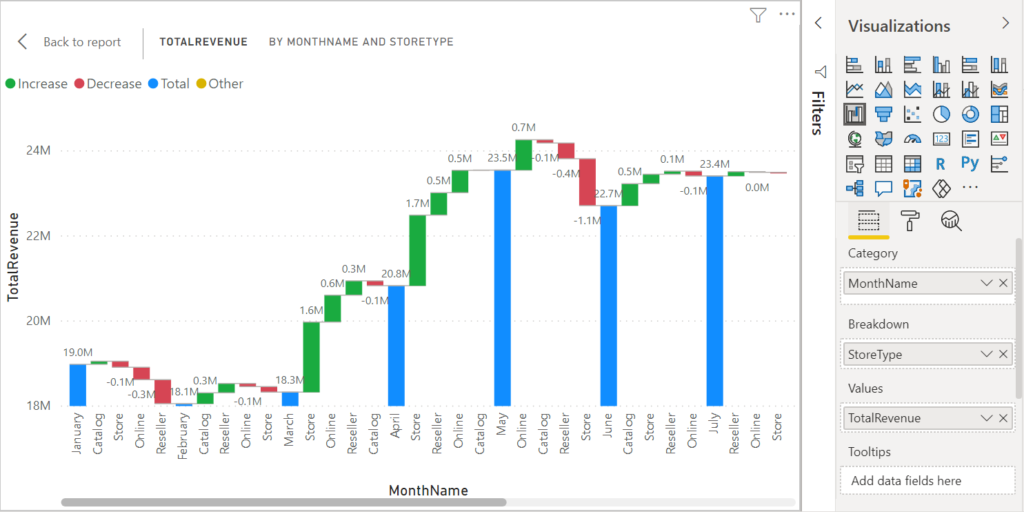
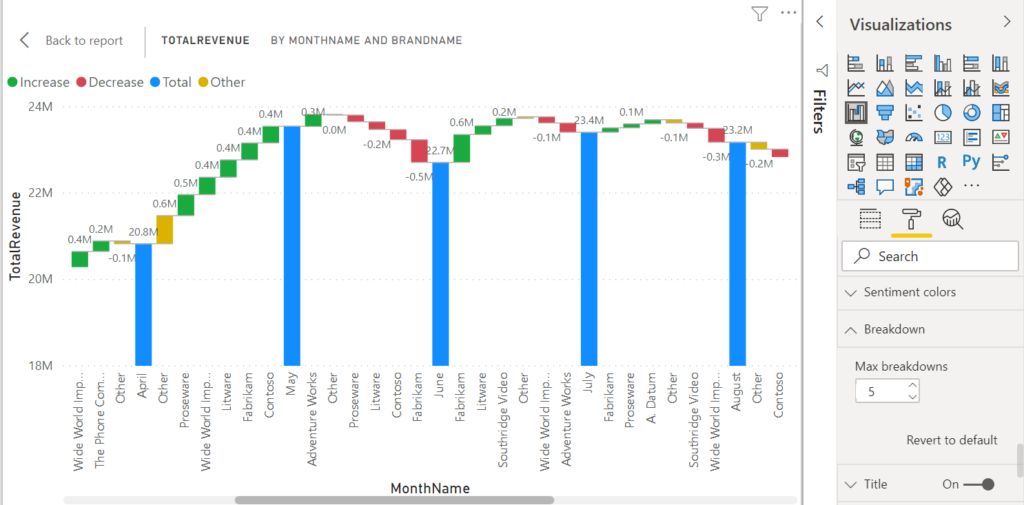
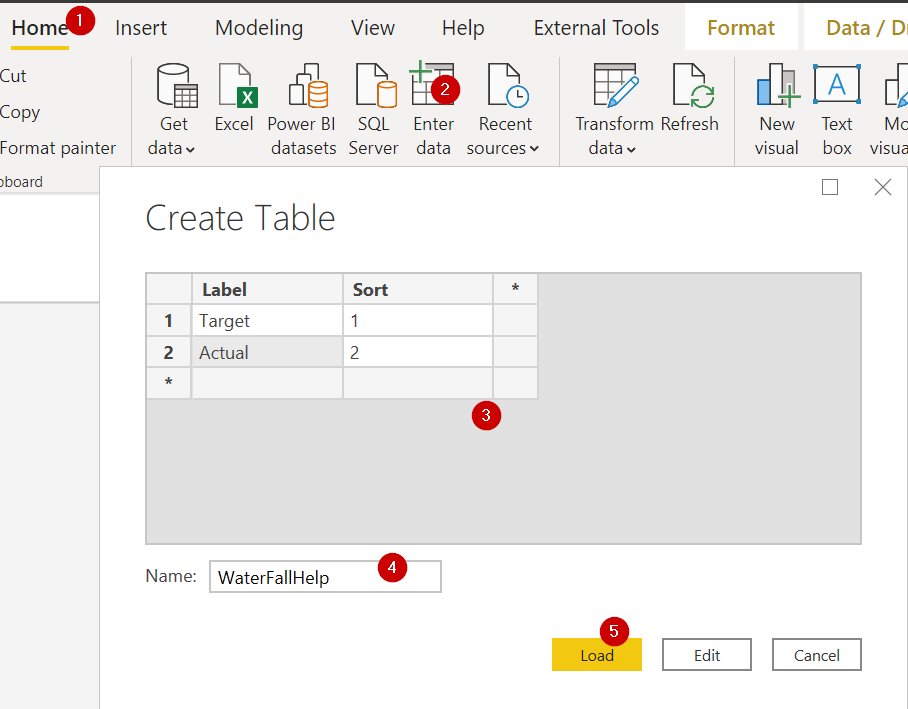
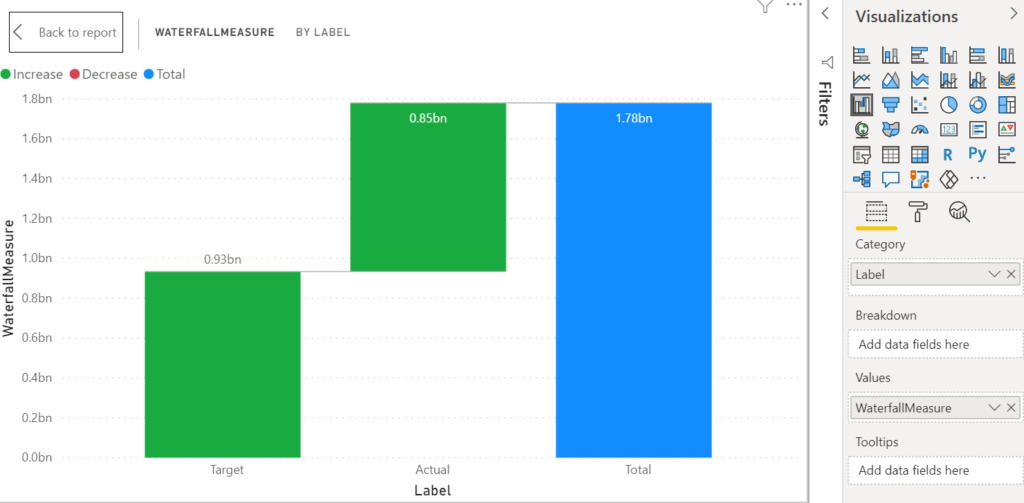
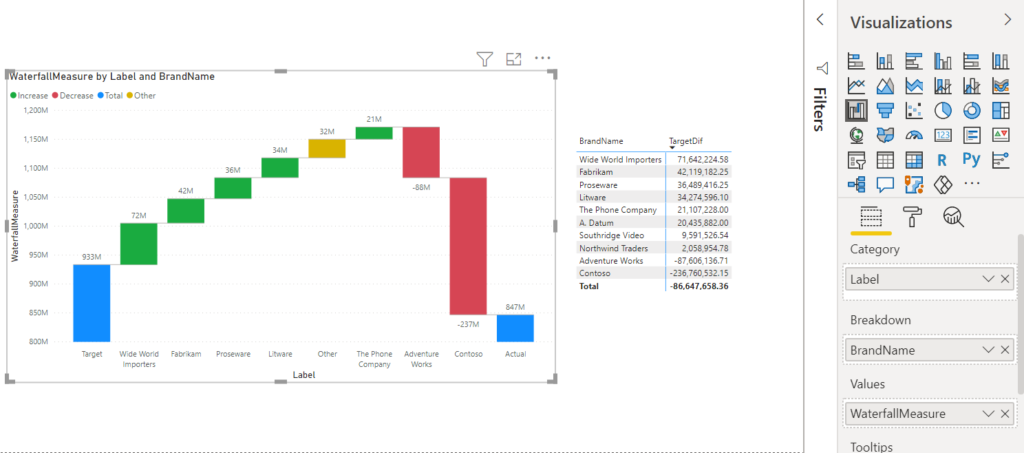
ขอเปิดบทความ Series ใหม่นั่นก็คือการเจาะลึกปรับแต่งการทำงานของ Visual ต่างๆ ใน Power BI ให้สร้างผลลัพธ์ให้ได้ดั่งใจเรามากขึ้น ซึ่งขอประเดิมด้วยกราฟ Waterfall ก่อนเลยครับ
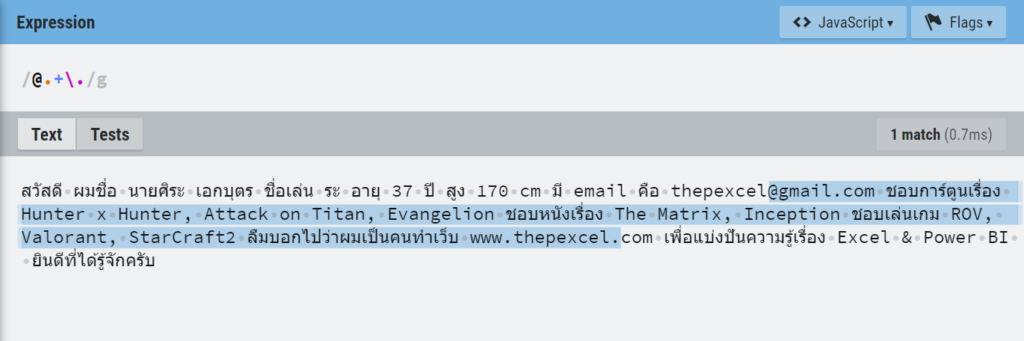
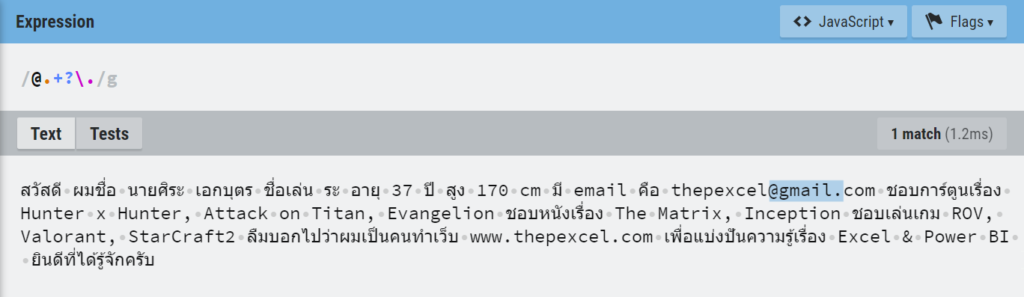
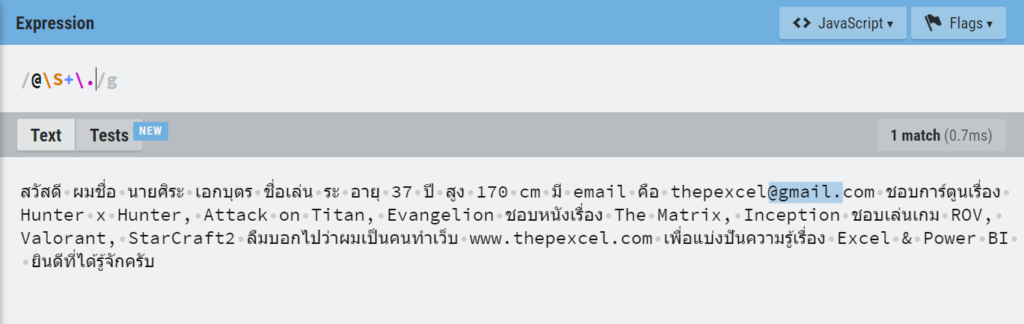
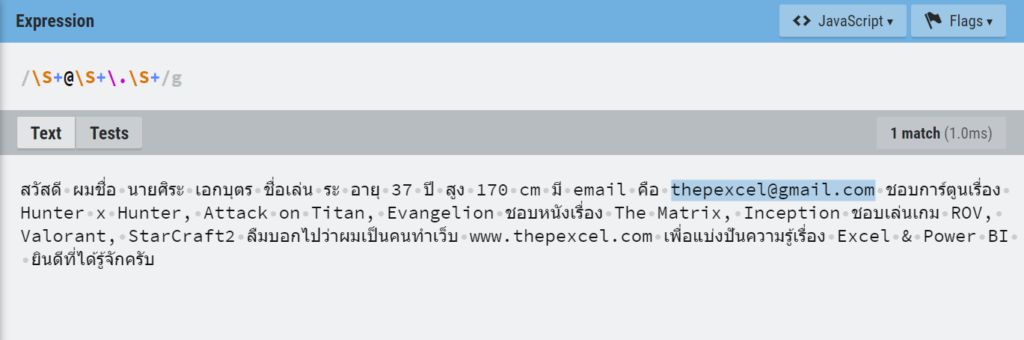
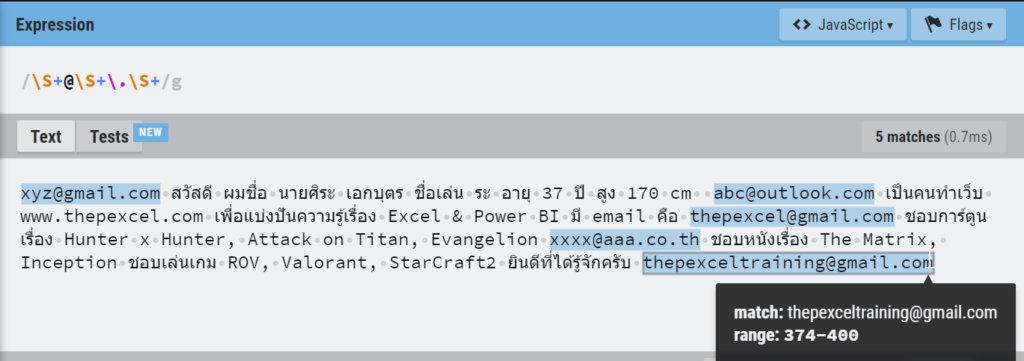
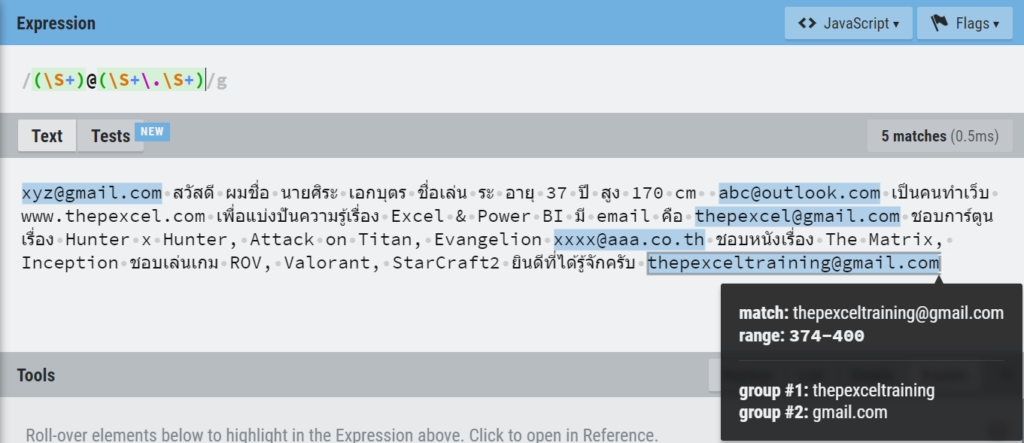
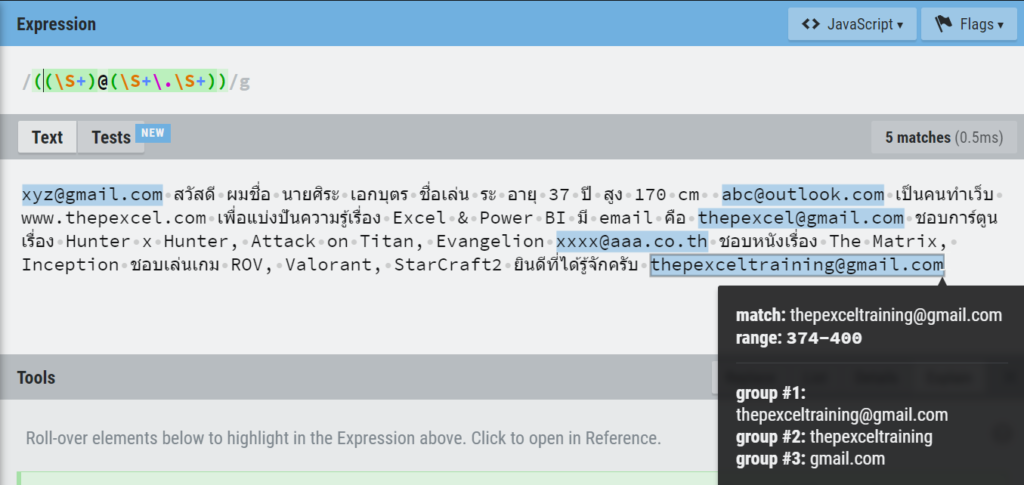
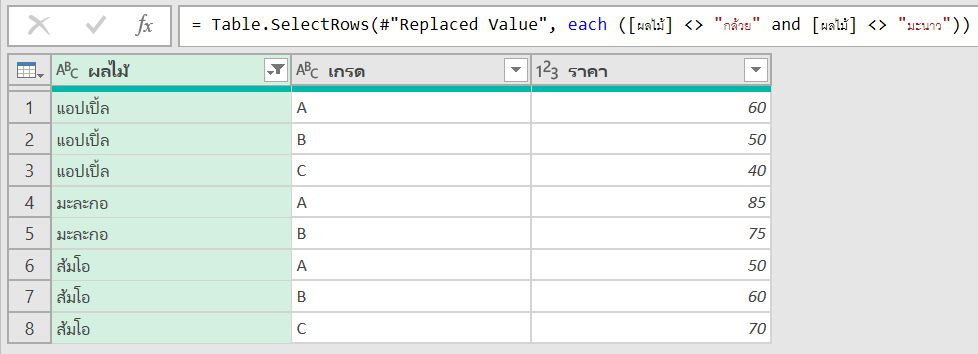
ปรากฏว่ามัน Match ข้อมูลเยอะมาก เพราะเราดันบอกว่าให้เอาตั้งแต่เครื่องหมาย @ แล้วตามด้วยตัวอะไรก็ได้อย่างน้อย 1 ตัว (เพราะใช้+) แล้วก็ตามด้วยด้วยจุด มันก็เล่น Match ให้เยอะที่สุดเท่าที่จะ Match ได้เลย อันนี้คือธรรมชาติของมันที่เรียกว่า Greedy Match (Match แบบตะกละ)
ทางแก้คือ ตอนใช้ Replace Value เพื่อนๆ ควรเลือก Advance แล้วติ๊ก Match Entire Cell Content ด้วย จะได้เป๊ะ!
ปราณคิวรี่ รูปแบบที่ 3 : Column From Example
กระบวนท่านี้เหมือนเป็นท่าไม้ตายที่อัจฉริยะ มันเลียนแบบกระบวนท่าอื่นๆ ได้เพียงใส่ผลลัพธ์ที่ต้องการให้ดูตัวอย่าง เหมือน Flash Fill ใน Excel ยังไงยังงั้นเลยครับ มันก็จะเลือกสูตรหรือคำสั่งที่เหมาะสมให้เราได้คอลัมน์ใหม่ตามที่ต้องการ
ตัวอย่างเช่น เราอาจจะแยกบางส่วนของคำ, เปลี่ยนตัวอักษรเป็นพิมพ์เล็กพิมพ์ใหญ่, เติม 0 หน้าตัวเลข, เขียนเงื่อนไข IF อะไรพวกนี้ เครื่องมือนี้ทำได้หมดเลยครับ!
เอาล่ะ ผมจะทำให้ดูเป็นตัวอย่างนะครับ
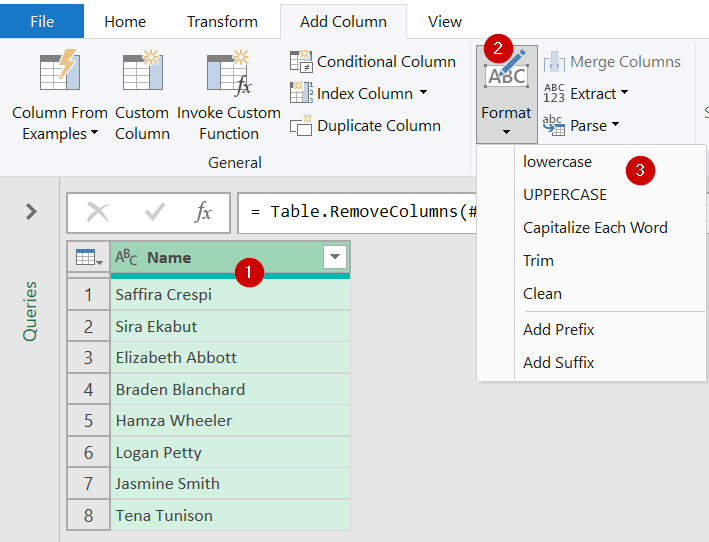
Power Query ให้ความสำคัญเรื่องตัวพิมพ์เล็กพิมพ์ใหญ่เสมอ หมายความว่ามันแยกแยะตัวอักษรที่พิมพ์ต่างกันได้หมด ดังนั้นเราควรทำตัวพิมพ์ให้ตรงกันทั้งหมดก่อนนะ เพื่อนๆ สามารถใช้คำสั่งใน Format ช่วยได้ มีทั้ง lowercase, UPPERCASE, Capitalize Each Word สบายใจได้เลยครับ
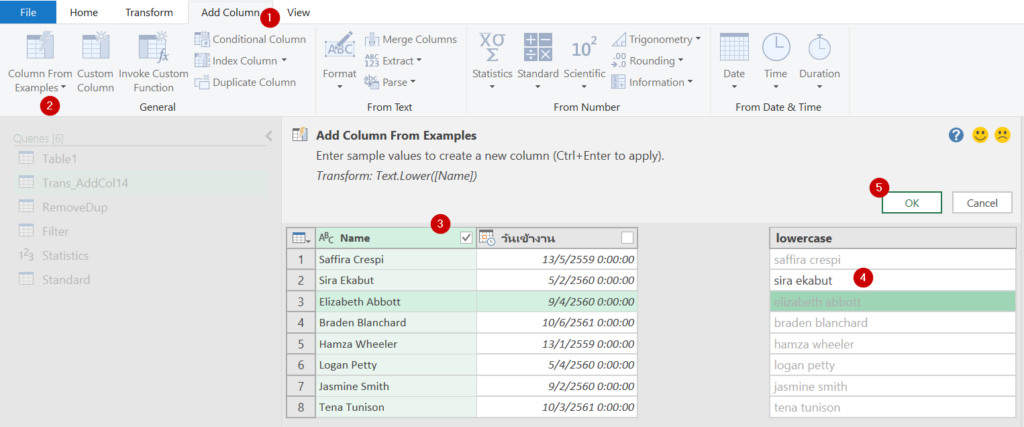
แต่ถ้าเพื่อนๆ ยังไม่รู้จักคำสั่งพวกนี้ดีพอ ก็ใช้ Column From Example ช่วยได้เหมือนกัน เรียกใช้งานแล้วใส่ตัวอย่างผลลัพธ์ที่ต้องการไว้ในคอลัมน์ด้านขวา มันจะคิดสูตรให้เหมือน Flash Fill แต่เจ๋งกว่าตรงที่ Power Query มัน Refresh ได้ด้วยนั่นแหละ
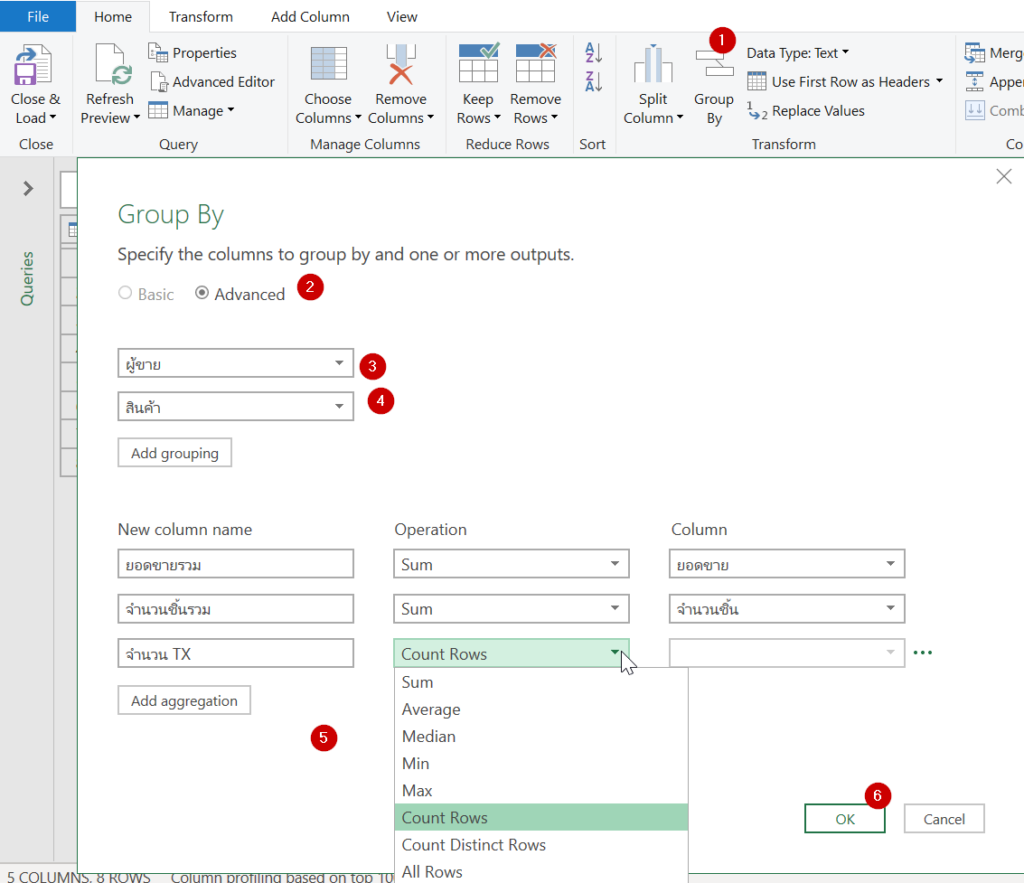
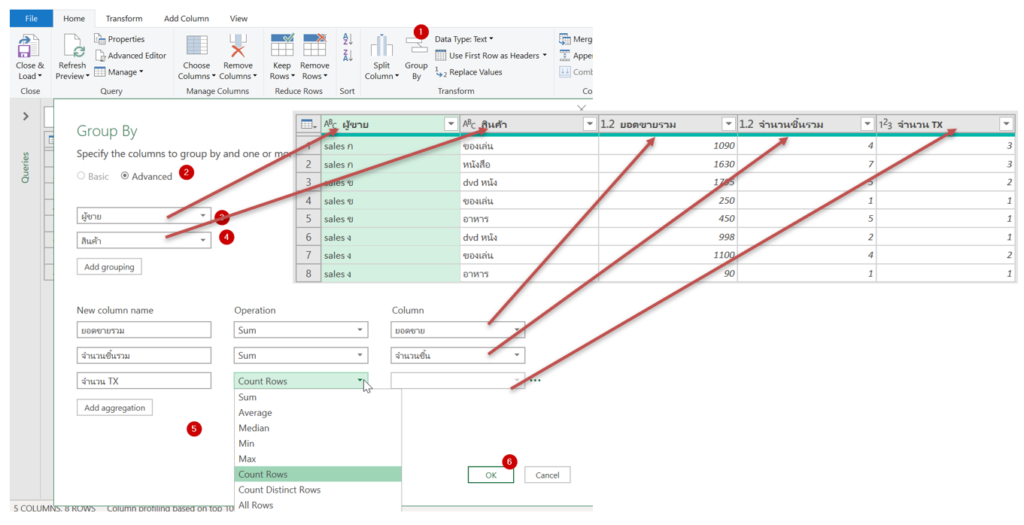
กระบวนท่า Group By จะรวบข้อมูลที่ซ้ำเข้าด้วยกันเป็นบรรทัดเดียว (คล้าย Remove Duplicates) แต่ที่เจ๋งกว่าคือมันสามารถสรุปข้อมูลไปพร้อมกันได้ด้วย เช่น Sum, Count, Average และอื่นๆ
ถ้าสังเกตดูจะเห็นว่าจำนวนแถวลดลง คอลัมน์จะเหลือแค่ตัวที่ Group ไว้ และคอลัมน์สรุป คอลัมน์ที่เหลือหายไปหมด
จริงๆ แล้ว Group By เป็นกำลังหลักที่จะพัฒนาไปใช้กับท่าแบบ Advance ที่เรียกว่า All Rows ในตอนต่อไป ซึ่งผมจะอธิบายให้ฟังอย่างละเอียดนะครับ
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.